Introduction
I’m still hunting for a set of machines with which I can generate 1Tbps and 1Gpps of VPP traffic, and considering a 100G network interface can do at most 148.8Mpps, I will need 7 or 8 of these network cards. Doing a loadtest like this with DACs back-to-back is definitely possible, but it’s a bit more convenient to connect them all to a switch. However, for this to work I would need (at least) fourteen or more HundredGigabitEthernet ports, and these switches tend to get expensive, real quick.
Or do they?
Hardware

I thought I’d ask the #nlnog IRC channel for advice, and of course the usual suspects came past, such as Juniper, Arista, and Cisco. But somebody mentioned “How about Mellanox, like SN2700?” and I remembered my buddy Eric was a fan of those switches. I looked them up on the refurbished market and I found one for EUR 1'400,- for 32x100G which felt suspiciously low priced… but I thought YOLO and I ordered it. It arrived a few days later via UPS from Denmark to Switzerland.
The switch specs are pretty impressive, with 32x100G QSFP28 ports, which can be broken out to a set of sub-ports (each of 1/10/25/50G), with a specified switch throughput of 6.4Tbps in 4.76Gpps, while only consuming ~150W all-up.
Further digging revealed that the architecture of this switch consists of two main parts:

an AMD64 component with an mSATA disk to boot from, two e1000 network cards, and a single USB and RJ45 serial port with standard pinout. It has a PCIe connection to a switch board in the front of the chassis, further more it’s equipped with 8GB of RAM in an SO-DIMM, and its CPU is a two core Celeron(R) CPU 1047UE @ 1.40GHz.
the silicon used in this switch is called Spectrum and identifies itself in Linux as PCI device
03:00.0called Mellanox Technologies MT52100, so the front dataplane with 32x100G is separated from the Linux based controlplane.

When turning on the device, the serial port comes to life and shows me a BIOS, quickly after which it jumps into GRUB2 and wants me to install it using something called ONIE. I’ve heard of that, but now it’s time for me to learn a little bit more about that stuff. I ask around and there’s plenty of ONIE images for this particular type of chip to be found - some are open source, some are semi-open source (as in: were once available but now are behind paywalls etc).
Before messing around with the switch and possibly locking myself out or bricking it, I take out the 16GB mSATA and make a copy of it for safe keeping. I feel somewhat invincible by doing this. How bad could I mess up this switch, if I can just copy back a bitwise backup of the 16GB mSATA? I’m about to find out, so read on!
Software
The Mellanox SN2700 switch is an ONIE (Open Network Install Environment) based platform that supports a multitude of operating systems, as well as utilizing the advantages of Open Ethernet and the capabilities of the Mellanox Spectrum® ASIC. The SN2700 has three modes of operation:
- Preinstalled with Mellanox Onyx (successor to MLNX-OS Ethernet), a home-grown operating system utilizing common networking user experiences and industry standard CLI.
- Preinstalled with Cumulus Linux, a revolutionary operating system taking the Linux user experience from servers to switches and providing a rich routing functionality for large scale applications.
- Provided with a bare ONIE image ready to be installed with the aforementioned or other ONIE-based operating systems.
I asked around a bit more and found that there’s a few more things one might do with this switch. One of them is [SONiC], which stands for Software for Open Networking in the Cloud, and has support for the Spectrum and notably the SN2700 switch. Cool!
I also learned about [DENT], which utilizes the Linux Kernel, Switchdev, and other Linux based projects as the basis for building a new standardized network operating system without abstractions or overhead. Unfortunately, while the Spectrum chipset is known to DENT, this particular layout on SN2700 is not supported.
Finally, my buddy fall0ut said “why not just Debian with switchdev?” and now my eyes opened wide.
I had not yet come across [switchdev], which is
a standard Linux kernel driver model for switch devices which offload the forwarding (data)plane
from the kernel. As it turns out, Mellanox did a really good job writing a switchdev implementation
in the [linux kernel]
for the Spectrum series of silicon, and it’s all upstreamed to the Linux kernel. Wait, what?!
Mellanox Switchdev
I start by reading the [brochure], which shows me the intentions Mellanox had when designing and marketing these switches. It seems that they really meant it when they said this thing is a fully customizable Linux switch, check out this paragraph:
Once the Mellanox Switchdev driver is loaded into the Linux Kernel, each of the switch’s physical ports is registered as a net_device within the kernel. Using standard Linux tools (for example, bridge, tc, iproute), ports can be bridged, bonded, tunneled, divided into VLANs, configured for L3 routing and more. Linux switching and routing tables are reflected in the switch hardware. Network traffic is then handled directly by the switch. Standard Linux networking applications can be natively deployed and run on switchdev. This may include open source routing protocol stacks, such as Quagga, Bird and XORP, OpenFlow applications, or user-specific implementations.
Installing Debian on SN2700
.. they had me at Bird :) so off I go, to install a vanilla Debian AMD64 Bookworm on a 120G mSATA I
had laying around. After installing it, I noticed that the coveted mlxsw driver is not shipped by
default on the Linux kernel image in Debian, so I decide to build my own, letting the [Debian
docs] take my hand and guide me through it.
I find a reference on the Mellanox [GitHub wiki] which shows me which kernel modules to include to successfully use the Spectrum under Linux, so I think I know what to do:
pim@summer:/usr/src$ sudo apt-get install build-essential linux-source bc kmod cpio flex \
libncurses5-dev libelf-dev libssl-dev dwarves bison
pim@summer:/usr/src$ sudo apt install linux-source-6.1
pim@summer:/usr/src$ sudo tar xf linux-source-6.1.tar.xz
pim@summer:/usr/src$ cd linux-source-6.1/
pim@summer:/usr/src/linux-source-6.1$ sudo cp /boot/config-6.1.0-12-amd64 .config
pim@summer:/usr/src/linux-source-6.1$ cat << EOF | sudo tee -a .config
CONFIG_NET_IPIP=m
CONFIG_NET_IPGRE_DEMUX=m
CONFIG_NET_IPGRE=m
CONFIG_IPV6_GRE=m
CONFIG_IP_MROUTE_MULTIPLE_TABLES=y
CONFIG_IP_MULTIPLE_TABLES=y
CONFIG_IPV6_MULTIPLE_TABLES=y
CONFIG_BRIDGE=m
CONFIG_VLAN_8021Q=m
CONFIG_BRIDGE_VLAN_FILTERING=y
CONFIG_BRIDGE_IGMP_SNOOPING=y
CONFIG_NET_SWITCHDEV=y
CONFIG_NET_DEVLINK=y
CONFIG_MLXFW=m
CONFIG_MLXSW_CORE=m
CONFIG_MLXSW_CORE_HWMON=y
CONFIG_MLXSW_CORE_THERMAL=y
CONFIG_MLXSW_PCI=m
CONFIG_MLXSW_I2C=m
CONFIG_MLXSW_MINIMAL=y
CONFIG_MLXSW_SWITCHX2=m
CONFIG_MLXSW_SPECTRUM=m
CONFIG_MLXSW_SPECTRUM_DCB=y
CONFIG_LEDS_MLXCPLD=m
CONFIG_NET_SCH_PRIO=m
CONFIG_NET_SCH_RED=m
CONFIG_NET_SCH_INGRESS=m
CONFIG_NET_CLS=y
CONFIG_NET_CLS_ACT=y
CONFIG_NET_ACT_MIRRED=m
CONFIG_NET_CLS_MATCHALL=m
CONFIG_NET_CLS_FLOWER=m
CONFIG_NET_ACT_GACT=m
CONFIG_NET_ACT_MIRRED=m
CONFIG_NET_ACT_SAMPLE=m
CONFIG_NET_ACT_VLAN=m
CONFIG_NET_L3_MASTER_DEV=y
CONFIG_NET_VRF=m
EOF
pim@summer:/usr/src/linux-source-6.1$ sudo make menuconfig
pim@summer:/usr/src/linux-source-6.1$ sudo make -j`nproc` bindeb-pkg
I run a gratuitous make menuconfig after adding all those config statements to the end of the
.config file, and it figures out how to combine what I wrote before with what was in the file
earlier, and I used the standard Bookworm 6.1 kernel config that came from the default installer, so
that it would be a minimal diff to what Debian itself shipped with.
After Summer stretches her legs a bit compiling this kernel for me, look at the result:
pim@summer:/usr/src$ dpkg -c linux-image-6.1.55_6.1.55-4_amd64.deb | grep mlxsw
drwxr-xr-x root/root 0 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/
-rw-r--r-- root/root 414897 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/mlxsw_core.ko
-rw-r--r-- root/root 19721 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/mlxsw_i2c.ko
-rw-r--r-- root/root 31817 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/mlxsw_minimal.ko
-rw-r--r-- root/root 65161 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/mlxsw_pci.ko
-rw-r--r-- root/root 1425065 2023-11-09 20:22 ./lib/modules/6.1.55/kernel/drivers/net/ethernet/mellanox/mlxsw/mlxsw_spectrum.ko
Good job, Summer! On my mSATA disk, I tell Linux to boot its kernel using the following in GRUB,
which will make the kernel not create spiffy interface names like enp6s0 or eno1 but just
enumerate them all one by one and call them eth0 and so on:
pim@fafo:~$ grep GRUB_CMDLINE /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT=""
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,115200n8 net.ifnames=0 biosdevname=0"
Mellanox SN2700 running Debian+Switchdev
I insert the freshly installed Debian Bookworm with custom compiled 6.1.55+mlxsw kernel into the
switch, and it boots on the first try. I see 34 (!) ethernet ports, noting that the first two come
from an Intel NIC but carrying a MAC address from Mellanox (starting with 0c:42:a1) and the other
32 have a common MAC address (from Mellanox, starting with 04:3f:72), and what I noticed is that
the MAC addresses here are skipping one between subsequent ports, which leads me to believe that
these 100G ports can be split into two (perhaps 2x50G, 2x40G, 2x25G, 2x10G, which I intend to find
out later). According to the official spec sheet, the switch allows 2-way breakout ports as well as
converter modules, to insert for example a 25G SFP28 into a QSFP28 switchport.
Honestly, I did not think I would get this far, so I humorously (at least, I think so) decide to call this switch [FAFO].
First off, the mlxsw driver loaded:
root@fafo:~# lsmod | grep mlx
mlxsw_spectrum 708608 0
mlxsw_pci 36864 1 mlxsw_spectrum
mlxsw_core 217088 2 mlxsw_pci,mlxsw_spectrum
mlxfw 36864 1 mlxsw_core
vxlan 106496 1 mlxsw_spectrum
ip6_tunnel 45056 1 mlxsw_spectrum
objagg 53248 1 mlxsw_spectrum
psample 20480 1 mlxsw_spectrum
parman 16384 1 mlxsw_spectrum
bridge 311296 1 mlxsw_spectrum
I run sensors-detect and pwmconfig, let the fans calibrate and write their config file. The fans
come back down to a more chill (pun intended) speed, and I take a closer look. It seems all fans and
all thermometers, including the ones in the QSFP28 cages and the Spectrum switch ASIC are
accounted for:
root@fafo:~# sensors
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +30.0°C (high = +87.0°C, crit = +105.0°C)
Core 0: +29.0°C (high = +87.0°C, crit = +105.0°C)
Core 1: +30.0°C (high = +87.0°C, crit = +105.0°C)
acpitz-acpi-0
Adapter: ACPI interface
temp1: +27.8°C (crit = +106.0°C)
temp2: +29.8°C (crit = +106.0°C)
mlxsw-pci-0300
Adapter: PCI adapter
fan1: 6239 RPM
fan2: 5378 RPM
fan3: 6268 RPM
fan4: 5378 RPM
fan5: 6326 RPM
fan6: 5442 RPM
fan7: 6268 RPM
fan8: 5315 RPM
temp1: +37.0°C (highest = +41.0°C)
front panel 001: +23.0°C (crit = +73.0°C, emerg = +75.0°C)
front panel 002: +24.0°C (crit = +73.0°C, emerg = +75.0°C)
front panel 003: +23.0°C (crit = +73.0°C, emerg = +75.0°C)
front panel 004: +26.0°C (crit = +73.0°C, emerg = +75.0°C)
...
From the top, first I see the classic CPU core temps, then an ACPI interface which I’m not quite
sure I understand the purpose of (possibly motherboard, but not PSU because pulling one out does not
change any values). Finally, the sensors using driver mlxsw-pci-0300, are those on the switch PCB
carrying the Spectrum silicon, and there’s a thermometer for each of the QSFP28 cages, possibly
reading from the optic, as most of them are empty except the first four which I inserted optics to.
Slick!
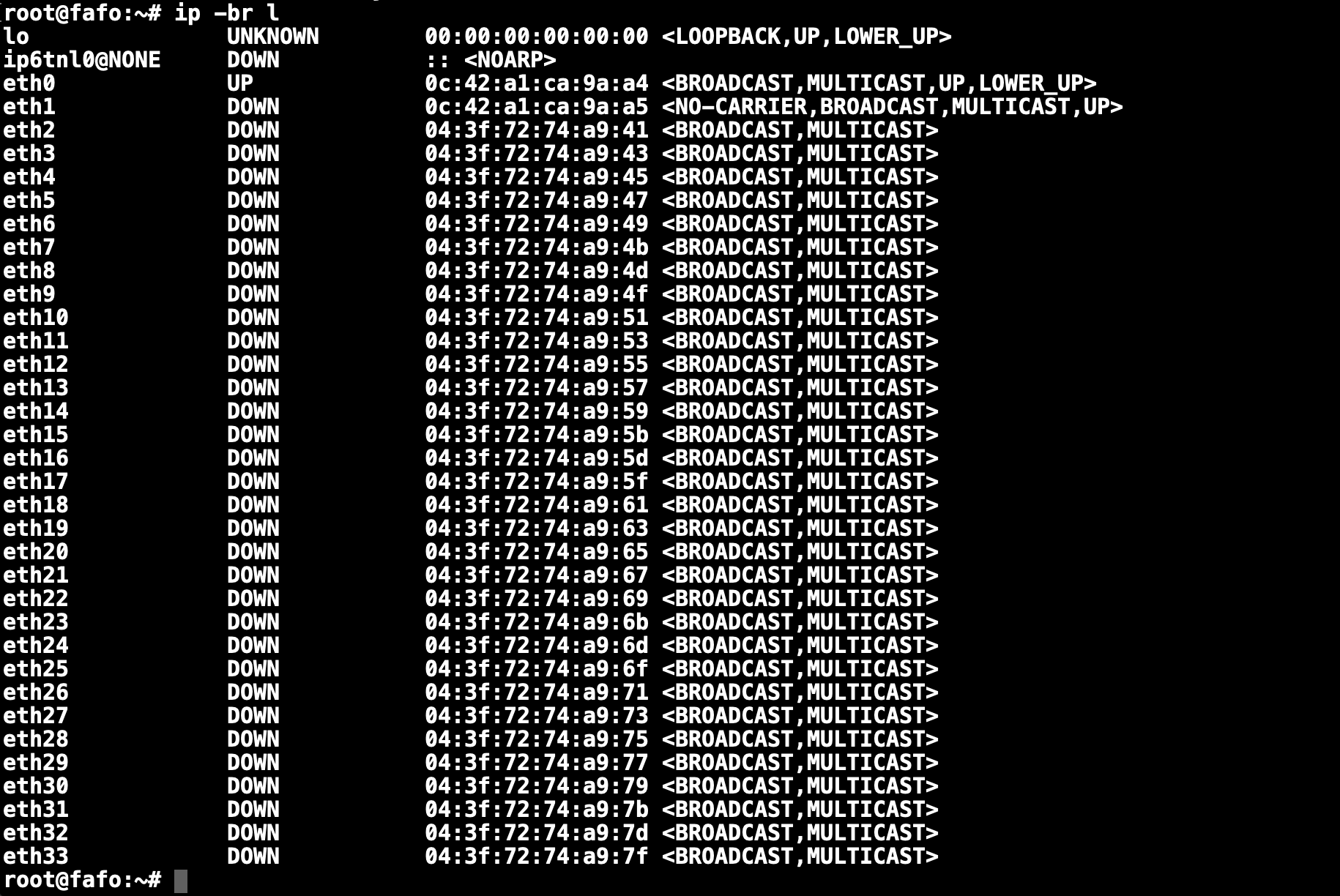
I notice that the ports are in a bit of a weird order. Firstly, eth0-1 are the two 1G ports on the Debian machine. But then, the rest of the ports are the Mellanox Spectrum ASIC:
- eth2-17 correspond to port 17-32, which seems normal, but
- eth18-19 correspond to port 15-16
- eth20-21 correspond to port 13-14
- eth30-31 correspond to port 3-4
- eth32-33 correspond to port 1-2
The switchports are actually sequentially numbered with respect to MAC addresses, with eth2
starting at 04:3f:72:74:a9:41 and finally eth34 having 04:3f:72:74:a9:7f (for 64 consecutive
MACs).
Somehow though, the ports are wired in a different way on the front panel. As it turns out, I can
insert a little udev ruleset that will take care of this:
root@fafo:~# cat << EOF > /etc/udev/rules.d/10-local.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="mlxsw_spectrum*", \
NAME="sw$attr{phys_port_name}"
EOF
After rebooting the switch, the ports are now called swp1 .. swp32 and they also correspond with
their physical ports on the front panel. One way to check this, is using ethtool --identify swp1
which will blink the LED of port 1, until I press ^C. Nice.
Debian SN2700: Diagnostics
The first thing I’m curious to try, is if Link Layer Discovery Protocol [LLDP] works. This is a vendor-neutral protocol that network devices use to advertise their identity to peers over Ethernet. I install an open source LLDP daemon and plug in a DAC from port1 to a Centec switch in the lab.
And indeed, quickly after that, I see two devices, the first on the Linux machine eth0 which is
the Unifi switch that has my LAN, and the second is the Centec behind swp1:
root@fafo:~# apt-get install lldpd
root@fafo:~# lldpcli show nei summary
-------------------------------------------------------------------------------
LLDP neighbors:
-------------------------------------------------------------------------------
Interface: eth0, via: LLDP
Chassis:
ChassisID: mac 44:d9:e7:05:ff:46
SysName: usw6-BasementServerroom
Port:
PortID: local Port 9
PortDescr: fafo.lab
TTL: 120
Interface: swp1, via: LLDP
Chassis:
ChassisID: mac 60:76:23:00:01:ea
SysName: sw3.lab
Port:
PortID: ifname eth-0-25
PortDescr: eth-0-25
TTL: 120
With this I learn that the switch forwards these datagrams (ethernet type 0x88CC) from the
dataplane to the Linux controlplane. I would call this punting in VPP language, but switchdev
calls it trapping, and I can see the LLDP packets when tcpdumping on ethernet device swp1.
So today I learned how to trap packets :-)
Debian SN2700: ethtool
One popular diagnostics tool that is useful (and, hopefully well known because it’s awesome),
isethtool, a command-line tool in Linux for managing network interface devices. It allows me to
modify the parameters of the ports and their transceivers, as well as query the information of those
devices.
Here are few common examples, all of which work on this switch running Debian:
ethtool swp1: Shows link capabilities (eg, 1G/10G/25G/40G/100G)ethtool -s swp1 speed 40000 duplex full autoneg off: Force speed/duplexethtool -m swp1: Shows transceiver diagnostics like SFP+ light levels, link levels (also--module-info)ethtool -p swp1: Flashes the transceiver port LED (also--identify)ethtool -S swp1: Shows packet and octet counters, and sizes, discards, errors, and so on (also--statistics)
I specifically love the digital diagnostics monitoring (DDM), originally specified in [SFF-8472], which allows me to read the EEPROM of optical transceivers and get all sorts of critical diagnostics. I wish DPDK and VPP had that!
Debian SN2700: devlink
In reading up on the switchdev ecosystem, I stumbled across devlink, an API to expose device
information and resources not directly related to any device class, such as switch ASIC
configuration. As a fun fact, devlink was written by the same engineer who wrote the mlxsw driver
for Linux, Jiří Pírko. Its documentation can be found in the [linux
kernel], and it ships with any modern
iproute2 distribution. The specific (somewhat terse) documentation of the mlxsw driver
[lives there] as well.
There’s a lot to explore here, but I’ll focus my attention to three things:
1. devlink resource
When learning that the switch also does IPv4 and IPv6 routing, I immediately thought: how many prefixes can be offloaded to the ASIC? One way to find out is to query what types of resources it has:
root@fafo:~# devlink resource show pci/0000:03:00.0
pci/0000:03:00.0:
name kvd size 258048 unit entry dpipe_tables none
resources:
name linear size 98304 occ 1 unit entry size_min 0 size_max 159744 size_gran 128 dpipe_tables none
resources:
name singles size 16384 occ 1 unit entry size_min 0 size_max 159744 size_gran 1 dpipe_tables none
name chunks size 49152 occ 0 unit entry size_min 0 size_max 159744 size_gran 32 dpipe_tables none
name large_chunks size 32768 occ 0 unit entry size_min 0 size_max 159744 size_gran 512 dpipe_tables none
name hash_double size 65408 unit entry size_min 32768 size_max 192512 size_gran 128 dpipe_tables none
name hash_single size 94336 unit entry size_min 65536 size_max 225280 size_gran 128 dpipe_tables none
name span_agents size 3 occ 0 unit entry dpipe_tables none
name counters size 32000 occ 4 unit entry dpipe_tables none
resources:
name rif size 8192 occ 0 unit entry dpipe_tables none
name flow size 23808 occ 4 unit entry dpipe_tables none
name global_policers size 1000 unit entry dpipe_tables none
resources:
name single_rate_policers size 968 occ 0 unit entry dpipe_tables none
name rif_mac_profiles size 1 occ 0 unit entry dpipe_tables none
name rifs size 1000 occ 1 unit entry dpipe_tables none
name physical_ports size 64 occ 36 unit entry dpipe_tables none
There’s a lot to unpack here, but this is a tree of resources, each with names and children. Let me
focus on the first one, called kvd, which stands for Key Value Database (in other words, a set
of lookup tables). It contains a bunch of children called linear, hash_double and hash_single.
The kernel [docs]
explain it in more detail, but this is where the switch will keep its FIB in Content Addressable
Memory (CAM) of certain types of elements of a given length and count. All up, the size is 252KB,
which is not huge, but also certainly not tiny!
Here I learn that it’s subdivided into:
- linear: 96KB bytes of flat memory using an index, further divided into regions:
***singles***: 16KB of size 1, nexthops***chunks***: 48KB of size 32, multipath routes with <32 entries***large_chunks***: 32KB of size 512, multipath routes with <512 entries
- hash_single: 92KB bytes of hash table for keys smaller than 64 bits (eg. L2 FIB, IPv4 FIB and neighbors)
- hash_double: 63KB bytes of hash table for keys larger than 64 bits (eg. IPv6 FIB and neighbors)
2. devlink dpipe
Now that I know the memory layout and regions of the CAM, I can start making some guesses on the FIB size. The devlink pipeline debug API (DPIPE) is aimed at providing the user visibility into the ASIC’s pipeline in a generic way. The API is described in detail in the [kernel docs]. I feel free to take a peek at the dataplane configuration innards:
root@fafo:~# devlink dpipe table show pci/0000:03:00.0
pci/0000:03:00.0:
name mlxsw_erif size 1000 counters_enabled false
match:
type field_exact header mlxsw_meta field erif_port mapping ifindex
action:
type field_modify header mlxsw_meta field l3_forward
type field_modify header mlxsw_meta field l3_drop
name mlxsw_host4 size 0 counters_enabled false resource_path /kvd/hash_single resource_units 1
match:
type field_exact header mlxsw_meta field erif_port mapping ifindex
type field_exact header ipv4 field destination ip
action:
type field_modify header ethernet field destination mac
name mlxsw_host6 size 0 counters_enabled false resource_path /kvd/hash_double resource_units 2
match:
type field_exact header mlxsw_meta field erif_port mapping ifindex
type field_exact header ipv6 field destination ip
action:
type field_modify header ethernet field destination mac
name mlxsw_adj size 0 counters_enabled false resource_path /kvd/linear resource_units 1
match:
type field_exact header mlxsw_meta field adj_index
type field_exact header mlxsw_meta field adj_size
type field_exact header mlxsw_meta field adj_hash_index
action:
type field_modify header ethernet field destination mac
type field_modify header mlxsw_meta field erif_port mapping ifindex
From this I can puzzle together how the CAM is actually used:
- mlxsw_host4: matches on the interface port and IPv4 destination IP, using
hash_singleabove with one unit for each entry, and when looking that up, puts the result into the ethernet destination MAC (in other words, the FIB entry points at an L2 nexthop!) - mlxsw_host6: matches on the interface port and IPv6 destination IP using
hash_doublewith two units for each entry. - mlxsw_adj: holds the L2 adjacencies, and the lookup key is an index, size and hash index, where the returned value is used to rewrite the destination MAC and select the egress port!
Now that I know the types of tables and what they are matching on (and then which action they are performing), I can also take a look at the actual data in the FIB. For example, if I create an IPv4 interface on the switch and ping a member on directly connected network there, I can see an entry show up in the L2 adjacency table, like so:
root@fafo:~# ip addr add 100.65.1.1/30 dev swp31
root@fafo:~# ping 100.65.1.2
root@fafo:~# devlink dpipe table dump pci/0000:03:00.0 name mlxsw_host4
pci/0000:03:00.0:
index 0
match_value:
type field_exact header mlxsw_meta field erif_port mapping ifindex mapping_value 71 value 1
type field_exact header ipv4 field destination ip value 100.65.1.2
action_value:
type field_modify header ethernet field destination mac value b4:96:91:b3:b1:10
To decypher what the switch is doing: if the ifindex is 71 (which corresponds to swp31), and the
IPv4 destination IP address is 100.65.1.2, then the destination MAC address will be set to
b4:96:91:b3:b1:10, so the switch knows where to send this ethernet datagram.
And now I have found what I need to know to be able to answer the question of the FIB size. This switch can take 92K IPv4 routes and 31.5K IPv6 routes, and I can even inspect the FIB in great detail. Rock on!
3. devlink port split
But reading the switch chip configuration and FIB is not all that devlink can do, it can also make
changes! One particularly interesting one is the ability to split and unsplit ports. What this means
is that, when you take a 100Gbit port, it internally is divided into four so-called lanes of
25Gbit each, where a 40Gbit port is internally divided into four lanes of 10Gbit each. Splitting
ports is the act of taking such a port and reconfiguring its lanes.
Let me show you, by means of example, what spliting the first two switchports might look like. They begin their life as 100G ports, which support a number of link speeds, notably: 100G, 50G, 25G, but also 40G, 10G, and finally 1G:
root@fafo:~# ethtool swp1
Settings for swp1:
Supported ports: [ FIBRE ]
Supported link modes: 1000baseKX/Full
10000baseKR/Full
40000baseCR4/Full
40000baseSR4/Full
40000baseLR4/Full
25000baseCR/Full
25000baseSR/Full
50000baseCR2/Full
100000baseSR4/Full
100000baseCR4/Full
100000baseLR4_ER4/Full
root@fafo:~# devlink port show | grep 'swp[12] '
pci/0000:03:00.0/61: type eth netdev swp1 flavour physical port 1 splittable true lanes 4
pci/0000:03:00.0/63: type eth netdev swp2 flavour physical port 2 splittable true lanes 4
root@fafo:~# devlink port split pci/0000:03:00.0/61 count 4
[ 629.593819] mlxsw_spectrum 0000:03:00.0 swp1: link down
[ 629.722731] mlxsw_spectrum 0000:03:00.0 swp2: link down
[ 630.049709] mlxsw_spectrum 0000:03:00.0: EMAD retries (1/5) (tid=64b1a5870000c726)
[ 630.092179] mlxsw_spectrum 0000:03:00.0 swp1s0: renamed from eth2
[ 630.148860] mlxsw_spectrum 0000:03:00.0 swp1s1: renamed from eth2
[ 630.375401] mlxsw_spectrum 0000:03:00.0 swp1s2: renamed from eth2
[ 630.375401] mlxsw_spectrum 0000:03:00.0 swp1s3: renamed from eth2
root@fafo:~# ethtool swp1s0
Settings for swp1s0:
Supported ports: [ FIBRE ]
Supported link modes: 1000baseKX/Full
10000baseKR/Full
25000baseCR/Full
25000baseSR/Full
Whoa, what just happened here? The switch took the port defined by pci/0000:03:00.0/61 which says
it is splittable and has four lanes, and split it into four NEW ports called swp1s0-swp1s3,
and the resulting ports are 25G, 10G or 1G.

However, I make an important observation. When splitting swp1 in 4, the switch also removed port
swp2, and remember at the beginning of this article I mentioned that the MAC addresses seemed to
skip one entry between subsequent interfaces? Now I understand why: when spltting the port into two,
it will use the second MAC address for the second 50G port; but if I split it into four, it’ll use
the MAC addresses from the adjacent port and decommission it. In other words: this switch can do
32x100G, or 64x50G, or 64x25G/10G/1G.
It doesn’t matter which of the PCI interfaces I split on. The operation is also reversible, I can
issue devlink port unsplit to return the port to its aggregate state (eg. 4 lanes and 100Gbit),
which will remove the swp1s0-3 ports and put back swp1 and swp2 again.
What I find particularly impressive about this, is that for most hardware vendors, this splitting of ports requires a reboot of the chassis, while here it can happen entirely online. Well done, Mellanox!
Performance
OK, so this all seems to work, but does it work well? If you’re a reader of my blog you’ll know that I love doing loadtests, so I boot my machine, Hippo, and I connect it with two 100G DACs to the switch on ports 31 and 32:
[ 1.354802] ice 0000:0c:00.0: 252.048 Gb/s available PCIe bandwidth (16.0 GT/s PCIe x16 link)
[ 1.447677] ice 0000:0c:00.0: firmware: direct-loading firmware intel/ice/ddp/ice.pkg
[ 1.561979] ice 0000:0c:00.1: 252.048 Gb/s available PCIe bandwidth (16.0 GT/s PCIe x16 link)
[ 7.738198] ice 0000:0c:00.0 enp12s0f0: NIC Link is up 100 Gbps Full Duplex, Requested FEC: RS-FEC,
Negotiated FEC: RS-FEC, Autoneg Advertised: On, Autoneg Negotiated: True, Flow Control: None
[ 7.802572] ice 0000:0c:00.1 enp12s0f1: NIC Link is up 100 Gbps Full Duplex, Requested FEC: RS-FEC,
Negotiated FEC: RS-FEC, Autoneg Advertised: On, Autoneg Negotiated: True, Flow Control: None
I hope you’re hungry, Hippo, cuz you’re about to get fed!
Debian SN2700: L2
To use the switch in L2 mode, I intuitively create Linux bridge, say br0, and add ports to that.
From the Mellanox documentation I learn that there can be multiple bridges, each isolated from one
another, but there can only be one such bridge with vlan_filtering set. VLAN Filtering allows
the switch to only accept tagged frames from a list of configured VLANs, and drop the rest. This
is what you’d imagine a regular commercial switch would provide.
So off I go, creating the bridge in which I’ll add two ports (HundredGigabitEthernet port swp31 and swp32), and I will allow for the maximum MTU size of 9216, also known as [Jumbo Frames].
root@fafo:~# ip link add name br0 type bridge
root@fafo:~# ip link set br0 type bridge vlan_filtering 1 mtu 9216 up
root@fafo:~# ip link set swp31 mtu 9216 master br0 up
root@fafo:~# ip link set swp32 mtu 9216 master br0 up
These two ports are now access ports, that is to say they accept and emit only untagged traffic,
and due to the vlan_filtering flag, they will drop all other frames. Using the standard bridge
utility from Linux, I can manipulate the VLANs on these ports.
First, I’ll remove the default VLAN and add VLAN 1234 to both ports, specifying that VLAN 1234 is the so-called Port VLAN ID (pvid). This makes them the equivalent of Cisco’s switchport access 1234:
root@fafo:~# bridge vlan del vid 1 dev swp1
root@fafo:~# bridge vlan del vid 1 dev swp2
root@fafo:~# bridge vlan add vid 1234 dev swp1 pvid
root@fafo:~# bridge vlan add vid 1234 dev swp2 pvid
Then, I’ll add a few tagged VLANs to the ports, so that they become the Cisco equivalent of a trunk port allowing these tagged VLANs and assuming untagged traffic is still VLAN 1234:
root@fafo:~# for port in swp1 swp2; do for vlan in 100 200 300 400; do \
bridge vlan add vid $vlan dev $port; done; done
root@fafo:~# bridge vlan
port vlan-id
swp1 100 200 300 400
1234 PVID
swp2 100 200 300 400
1234 PVID
br0 1 PVID Egress Untagged
When these commands are run against the interfaces swp*, they are picked up by the mlxsw kernel
driver, and transmitted to the Spectrum switch chip, in other words, these commands end up
programming the silicon. Traffic through these switch ports on the front, rarely (if ever) get
forwarded to the Linux kernel, very similar to [VPP], the traffic stays mostly in
the dataplane. Some traffic, such as LLDP (and as we’ll see later, IPv4 ARP and IPv6 neighbor
discovery), will be forwarded from the switch chip over the PCIe link to the kernel, after which the
results are transmitted back via PCIe to program the switch chip L2/L3 Forwarding Information Base
(FIB).
Now I turn my attention to the loadtest, by configuring T-Rex in L2 Stateless mode. I start a bidirectional loadtest with 256b packets at 50% of line rate, which looks just fine:
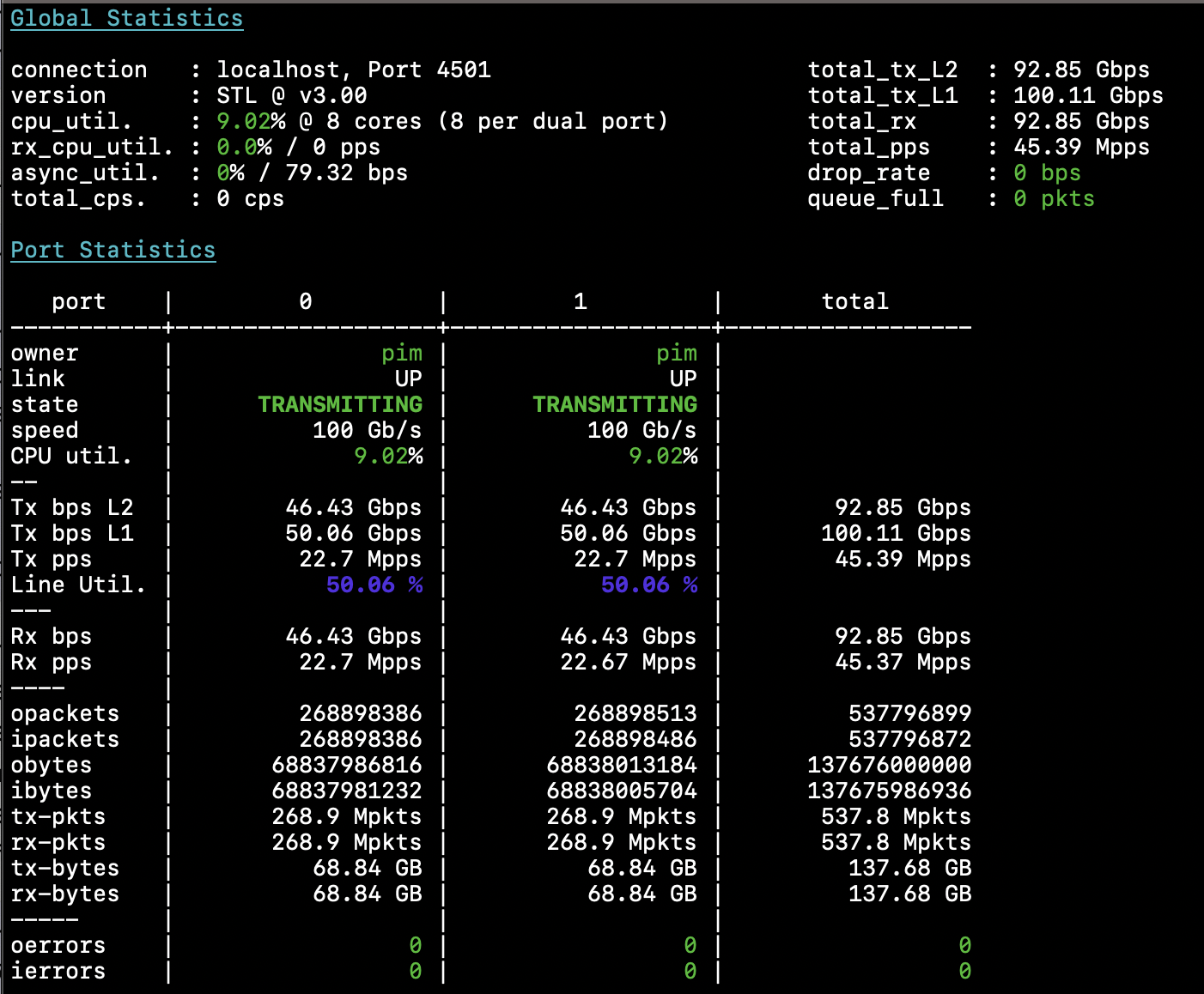
At this point I can already conclude that this is all happening in the dataplane, as the Spectrum
switch is connected to the Debian machine using a PCIe v3.0 x8 link, which is even obscured by
another device on the PCIe bus, so the Debian kernel is in no way able to process more than a token
amount of traffic, and yet I’m seeing 100Gbit go through the switch chip and the CPU load on the
kernel pretty much zero. I can however retrieve the link statistics using ip stats, and those will
show me the actual counters of the silicon, not just the trapped packets. If you’ll recall, in VPP
the only packets that the TAP interfaces see are those packets that are punted, and the Linux
kernel there is completely oblivious to the total dataplane throughput. Here, the interface is
showing the correct dataplane packet and byte counters, which means that things like SNMP will
automatically just do the right thing.
root@fafo:~# dmesg | grep 03:00.*bandwidth
[ 2.180410] pci 0000:03:00.0: 16.000 Gb/s available PCIe bandwidth, limited by 5.0 GT/s
PCIe x4 link at 0000:00:01.2 (capable of 31.504 Gb/s with 8.0 GT/s PCIe x4 link)
root@fafo:~# uptime
03:19:16 up 2 days, 14:14, 1 user, load average: 0.00, 0.00, 0.00
root@fafo:~# ip stats show dev swp32 group link
72: swp32: group link
RX: bytes packets errors dropped missed mcast
5106713943502 15175926564 0 0 0 103
TX: bytes packets errors dropped carrier collsns
23464859508367 103495791750 0 0 0 0
Debian SN2700: IPv4 and IPv6
I now take a look at the L3 capabilities of the switch. To do this, I simply destroy the bridge
br0, which will return the enslaved switchports. I then convert the T-Rex loadtester to use an L3
profile, and configure the switch as follows:
root@fafo:~# ip addr add 100.65.1.1/30 dev swp31
root@fafo:~# ip nei replace 100.65.1.2 lladdr b4:96:91:b3:b1:10 dev swp31
root@fafo:~# ip ro add 16.0.0.0/8 via 100.65.1.2 dev swp31
root@fafo:~# ip addr add 100.65.2.1/30 dev swp32
root@fafo:~# ip nei replace 100.65.2.2 lladdr b4:96:91:b3:b1:11 dev swp32
root@fafo:~# ip ro add 48.0.0.0/8 via 100.65.2.2 dev swp32
Several other routers I’ve loadtested have the same (cosmetic) issue, that T-Rex doesn’t reply to
ARP packets after the first few seconds, so I first set the IPv4 address, then add a static L2
adjacency for the T-Rex side (on MAC b4:96:91:b3:b1:10), and route 16.0.0.0/8 to port 0 and I
route 48.0.0.0/8 to port 1 of the loadtester.
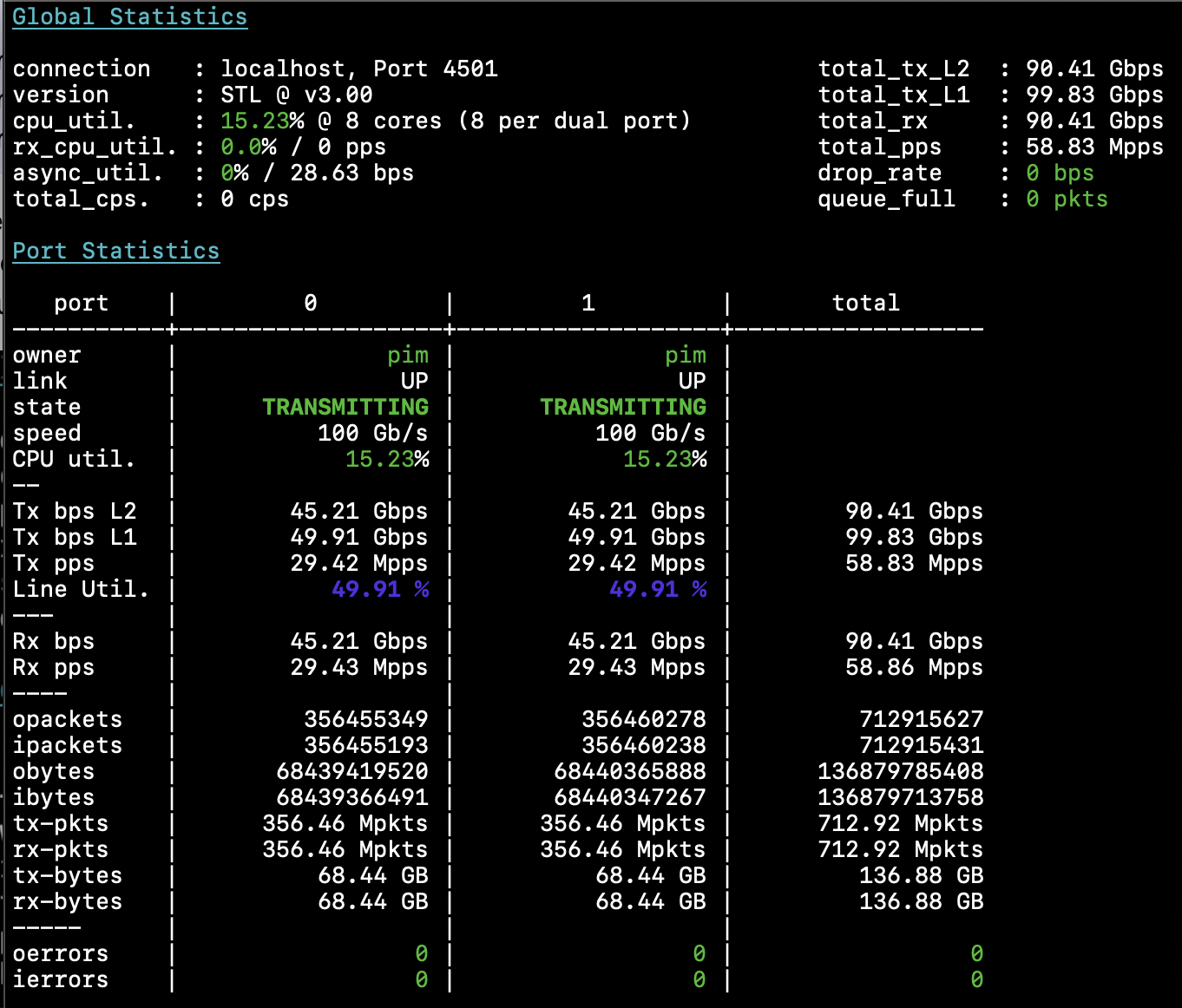
I start a stateless L3 loadtest with 192 byte packets in both directions, and the switch keeps up
just fine. Taking a closer look at the ip stats instrumentation, I see that there’s the ability to
turn on L3 counters in addition to L2 (ethernet) counters. So I do that on my two router ports while
they are happily forwarding 58.9Mpps, and I can now see the difference between dataplane (forwarded in
hardware) and CPU (forwarded by the CPU)
root@fafo:~# ip stats set dev swp31 l3_stats on
root@fafo:~# ip stats set dev swp32 l3_stats on
root@fafo:~# ip stats show dev swp32 group offload subgroup l3_stats
72: swp32: group offload subgroup l3_stats on used on
RX: bytes packets errors dropped mcast
270222574848200 1137559577576 0 0 0
TX: bytes packets errors dropped
281073635911430 1196677185749 0 0
root@fafo:~# ip stats show dev swp32 group offload subgroup cpu_hit
72: swp32: group offload subgroup cpu_hit
RX: bytes packets errors dropped missed mcast
1068742 17810 0 0 0 0
TX: bytes packets errors dropped carrier collsns
468546 2191 0 0 0 0
The statistics above clearly demonstrate that the lion’s share of the packets have been forwarded by the ASIC, and only a few (notably things like IPv6 neighbor discovery, IPv4 ARP, LLDP, and of course any traffic to the IP addresses configured on the router) will go to the kernel.
Debian SN2700: BVI (or VLAN Interfaces)
I’ve played around a little bit with L2 (switch) and L3 (router) ports, but there is one middle ground. I’ll keep the T-Rex loadtest running in L3 mode, but now I’ll reconfigure the switch to put the ports back into the bridge, each port in its own VLAN, and have so-called Bridge Virtual Interface, also known as VLAN interfaces – this is where the switch has a bunch of ports together in a VLAN, but the switch itself has an IPv4 or IPv6 address in that VLAN as well, which can act as a router.
I reconfigure the switch to put the interfaces back into VLAN 1000 and 2000 respectively, and move the IPv4 addresses and routes there – so here I go, first putting the switch interfaces back into L2 mode and adding them to the bridge, each in their own VLAN, by making them access ports:
root@fafo:~# ip link add name br0 type bridge vlan_filtering 1
root@fafo:~# ip link set br0 address 04:3f:72:74:a9:7d mtu 9216 up
root@fafo:~# ip link set swp31 master br0 mtu 9216 up
root@fafo:~# ip link set swp32 master br0 mtu 9216 up
root@fafo:~# bridge vlan del vid 1 dev swp31
root@fafo:~# bridge vlan del vid 1 dev swp32
root@fafo:~# bridge vlan add vid 1000 dev swp31 pvid
root@fafo:~# bridge vlan add vid 2000 dev swp32 pvid
From the ASIC specs, I understand that these BVIs need to (re)use a MAC from one of the members, so
the first thing I do is give br0 the right MAC address. Then I put the switch ports into the bridge,
remove VLAN 1 and put them in their respective VLANs. At this point, the loadtester reports 100%
packet loss, because the two ports can no longer see each other at layer2, and layer3 configs have
been removed. But I can restore connectivity with two BVIs as follows:
root@fafo:~# for vlan in 1000 2000; do
ip link add link br0 name br0.$vlan type vlan id $vlan
bridge vlan add dev br0 vid $vlan self
ip link set br0.$vlan up mtu 9216
done
root@fafo:~# ip addr add 100.65.1.1/24 dev br0.1000
root@fafo:~# ip ro add 16.0.0.0/8 via 100.65.1.2
root@fafo:~# ip nei replace 100.65.1.2 lladdr b4:96:91:b3:b1:10 dev br0.1000
root@fafo:~# ip addr add 100.65.2.1/24 dev br0.2000
root@fafo:~# ip ro add 48.0.0.0/8 via 100.65.2.2
root@fafo:~# ip nei replace 100.65.2.2 lladdr b4:96:91:b3:b1:11 dev br0.2000
And with that, the loadtest shoots back in action: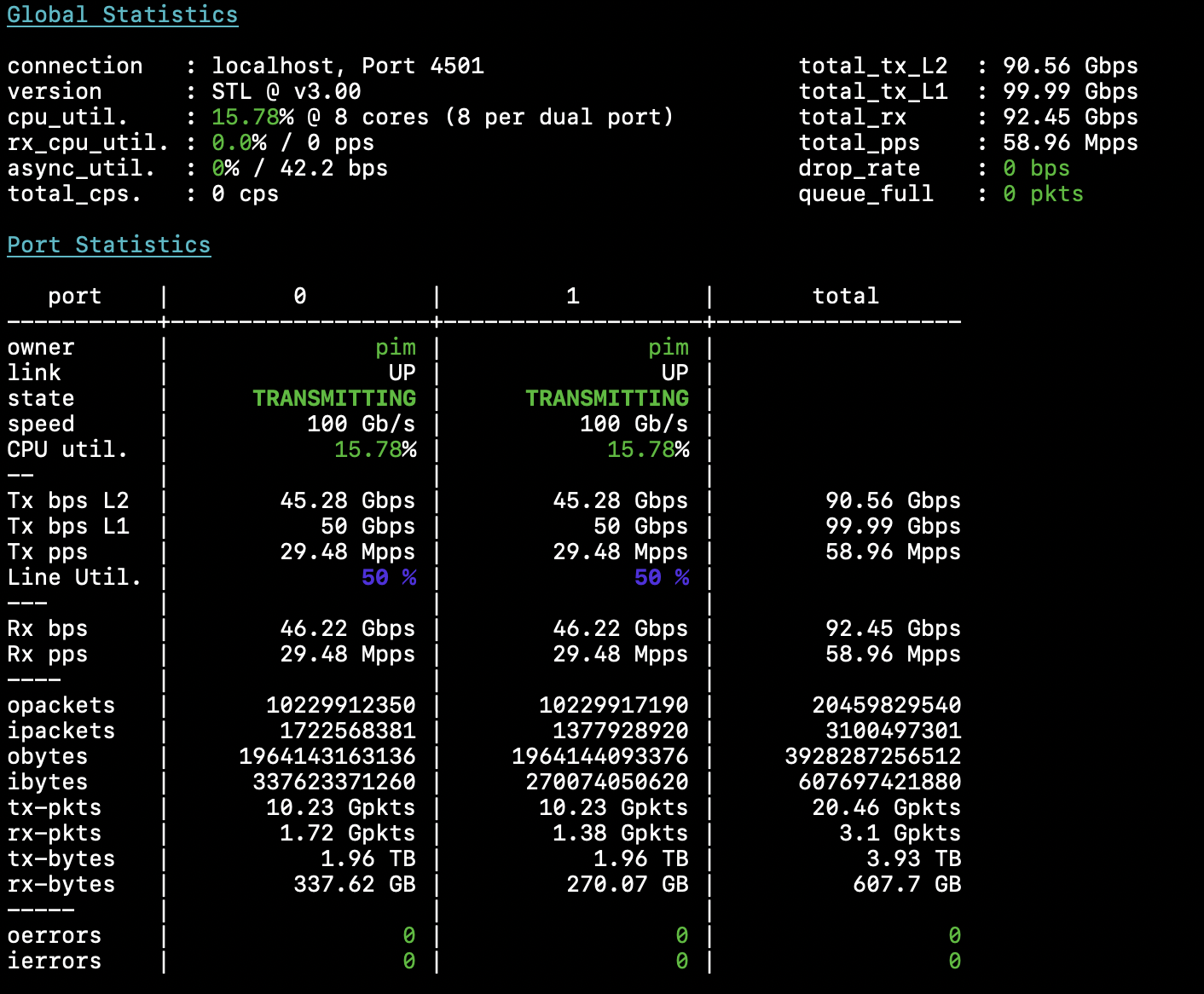
First a quick overview of the sitation I have created:
root@fafo:~# bridge vlan
port vlan-id
swp31 1000 PVID
swp32 2000 PVID
br0 1 PVID Egress Untagged
root@fafo:~# ip -4 ro
default via 198.19.5.1 dev eth0 onlink rt_trap
16.0.0.0/8 via 100.65.1.2 dev br0.1000 offload rt_offload
48.0.0.0/8 via 100.65.2.2 dev br0.2000 offload rt_offload
100.65.1.0/24 dev br0.1000 proto kernel scope link src 100.65.1.1 rt_offload
100.65.2.0/24 dev br0.2000 proto kernel scope link src 100.65.2.1 rt_offload
198.19.5.0/26 dev eth0 proto kernel scope link src 198.19.5.62 rt_trap
root@fafo:~# ip -4 nei
198.19.5.1 dev eth0 lladdr 00:1e:08:26:ec:f3 REACHABLE
100.65.1.2 dev br0.1000 lladdr b4:96:91:b3:b1:10 offload PERMANENT
100.65.2.2 dev br0.2000 lladdr b4:96:91:b3:b1:11 offload PERMANENT
Looking at the situation now, compared to the regular IPv4 L3 loadtest, there is one important
difference. Now, the switch can have any number of ports in VLAN 1000, which will all amongst
themselves do L2 forwarding at line rate, and when they need to send IPv4 traffic out, they will ARP
for the gateway (for example at 100.65.1.1/24), which will get trapped and forwarded to the CPU,
after which the ARP reply will go out so that the machines know where to find the gateway. From that
point on, IPv4 forwarding happens once again in hardware, which can be shown by the keywords
rt_offload in the routing table (br0, in the ASIC), compared to the rt_trap (eth0, in the
kernel). Similarly for the IPv4 neighbors, the L2 adjacency is programmed into the CAM (the output
of which I took a look at above), do forwarding can be done directly by the ASIC without
intervention from the CPU.
As a result, these VLAN Interfaces (which are synonymous with BVIs), work at line rate out of the box.
Results
This switch is phenomenal, and Jiří Pírko and the Mellanox team truly outdid themselves with their mlxsw
switchdev implementation. I have in my hands a very affordable 32x100G or 64x(50G, 25G, 10G, 1G) and
anything in between, with IPv4 and IPv6 forwarding in hardware, with a limited FIB size, not too
dissimilar from the [Centec] switches that IPng Networks
runs in its AS8298 network, albeit without MPLS forwarding capabilities.
Still, for a LAB switch, to better test 25G and 100G topologies, this switch is very good value for my money spent, and that it runs Debian and is fully configurable with things like Kees and Ansible. Considering there’s a whole range of 48x10G and 48x25G switches as well from Mellanox, all completely open and officially allowed to run OSS stuff on, these make a perfect fit for IPng Networks!
Acknowledgements
This article was written after fussing around and finding out, but a few references were particularly helpful, and I’d like to acknowledge the following super useful sites:
- [mlxsw wiki] on GitHub
- [jpirko’s kernel driver] on GitHub
- [SONiC wiki] on GitHub
- [Spectrum Docs] on NVIDIA
And to the community for writing and maintaining this excellent switchdev implementation.