Introduction

You know what would be really cool? If VPP could be an eVPN/VxLAN speaker! Sometimes I feel like I’m the very last on the planet to learn about something cool. My latest “A-Ha!"-moment was when I was configuring the eVPN fabric for [Frys-IX], and I wrote up an article about it [here] back in April.
I can build the equivalent of Virtual Private Wires (VPWS), also called L2VPN or Virtual Leased Lines, and these are straightforward because they typically only have two endpoints. A “regular” VxLAN tunnel which is L2 cross connected with another interface already does that just fine. Take a look at an article on [L2 Gymnastics] for that. But the real kicker is that I can also create multi-site L2 domains like Virtual Private LAN Services (VPLS) or also called Virtual Private Ethernet, L2VPN or Ethernet LAN Service (E-LAN). And that is a whole other level of awesome.
In the [previous] article, I noted a specific problem which I’d love to see fixed:
4. Self-Healing: And then there is the problem I find most acute and worthwhile to solve for IPng: if a primary VPP gateway becomes unfit to serve at 3am in the morning, nothing notices and nothing moves the L3 addresses to a healthy standby, even if they are readily available! Automated failover would be fantastic to have …
I’m not one to make false promises (ahem), although I am known for cliff hangers from time to time… so this article shows one approach to solving that problem in an eVPN-centric way.
vpp-evpn: Recap
In this series I’ve been talking about vpp-evpn, a control- and management plane layered on top of
VPP and Bird. It has three components. vpp-evpnd runs on every VPP router: it writes Bird
evpn/vppevpn config snippets into a dedicated include directory, manages the per-bridge Bridge
Virtual Interface (BVI) loopback and the L2FIB in VPP via the binary API, and persists its
programmed state to disk so a daemon restart leaves forwarding completely undisturbed. The per-host
API is a clean CRUD/L gRPC surface – CreateEvpnInstance, BindGroupBVI, and friends.
Then, the fleet-wide picture is owned by vpp-evpnr, a central registry. It stores group membership
(which vpp-evpnd instances share a broadcast domain), the group vMAC and gateway addresses, and the
assigned primary. Failover is strictly serialized with a break-before-make sequence: the current
primary releases the GroupBVI, the eVPN fabric is given a brief settle window to absorb the vMAC
withdrawal, and only then does the incoming primary bind and announce it in BGP. At no point can two
nodes advertise the same vMAC into the same Route Discriminator / Route Target.
Rounding it out, vpp-evpnc is a tab-completing interactive CLI backed by the
[golang-cli] package that I extracted from vpp-maglev. Its
tab-completion tokens come from live List* gRPC calls, so the interactive shell always reflects
the actual fleet. The end result is that I can ask a VPP router to join or leave an eVPN, move the
L3 gateway, and observe the whole fleet through a single gRPC interface – with no SSH sessions and
no hand-edited Bird files. Noice.
vpp-evpn: Health checking Requirements
A system that requires a human to notice a failed gateway and run vpp-evpnc group X bvi set primary is
better than nothing, but only by a little bit. My ultimate goal is for the registry to catch an
unfit primary and move the GroupBVI on its own. To do that, I need a health dimension that tests
actual dataplane forwarding between the VPP nodes sharing a bridge domain – not just whether a
process is alive or a gRPC connection is open, which vpp-evpnr already tracks.
I mulled over it for a little while, and landed on a periodic authenticated multicast heartbeat
between the LCP taps of all members in a group. Each node sends beats and listens for the ones
coming from its peers. If a member goes silent, its peers will notice; if the primary goes silent
and a healthy candidate is available, vpp-evpnr autonomously promotes one. To prevent a flapping
primary from oscillating the eVPN fabric and causing MAC dampening, any failover decision is gated
by HAProxy-style rise/fall counters, which I learned about in the [VPP Maglev] project. The gist of it: a primary must accumulate N consecutive
unfit samples before vpp-evpnr acts, and another M consecutive fit samples before the damping clears.
A post-failover cooldown suppresses further automatic moves on that group while the fabric settles.
If fecal matter really hit the cooling device, I’d rather just sit out the storm than have my
network play Flappy Bird with my traffic.
Three edge cases deserve special attention. A single-member group has no peers to compare
against, so there is no basis for a health verdict and no failover candidate; the primary simply
keeps running. With two members where one is unfit, vpp-evpnr promotes the healthy one – provided
it can reach it over the management network. If the candidate is also unreachable, vpp-evpnr logs
a warning and leaves the primary in place, because moving to an unreachable node would guarantee
an outage rather than merely risking one. With multiple members and an unfit primary, vpp-evpnr
picks the healthiest candidate by priority, then by instance ID as a deterministic tiebreaker. As an
added benefit, group consensus becomes possible: if three candidates all observed the primary
vanish, I can be pretty sure it has an issue.
My solution must also handle component failures gracefully, although in my experience VPP and Bird
crashes are rare, they do happen and precisely when they do, I do not want to end up in an
unrecoverable state. A vpp-evpnd crash must not disturb the dataplane or Bird, because neither
depends on it. An vpp-evpnr crash freezes all roles – no promotions happen while the coordinator
is absent. When vpp-evpnr returns, members reconnect by stable instance ID and the group state is
restored from the registry’s JSON state file. A VPP or Bird restart under a live vpp-evpnd
triggers a reconnect and reconcile. A vpp-evpnd restart will pick up where it left off, examine
the Bird and VPP dataplane, assess and synchronize local situation because who knows, maybe they
crashed too, or the whole machine lost power or rebooted. Once the local vpp-evpnd, Bird and VPP
all agree on their state, vpp-evpnd will signal its readiness and continue to absorb instructions
from the vpp-evpnr orchestration layer.
One extra fail-safe is warranted for the case where a primary has lost both its vpp-evpnr connection
and all peer heartbeats. In that scenario the node is very likely a black hole – it still holds
the vMAC but no coordinator can order it to release, and its peers cannot hear it to verify whether
it is alive. To avoid this “stuck gateway” outcome, I decide to add a fail-closed self-fence:
after a configurable deadline, the health checker should request that its local vpp-evpnd release
the GroupBVI. This is a demotion request, never a promotion, and it is advisory – vpp-evpnd may
decline if it has meanwhile reconnected. My rationale: zero gateways is strictly better than two
gateways advertising the same vMAC and potentially announcing prefixes into the AS8298 backbone and
blackholing traffic.
evpnh: A Health Checker
I make an early architectural decision to keep the health subsystem entirely standalone: its own
package (internal/health) and its own binary (cmd/evpnh). The contract with the rest of the
system is a small gRPC service, where vpp-evpnd is its sole client: it pushes per-group
desired-state (which interface to send beats on, the shared secrets, the expected peer set, and the
current primary/candidate role), and then subscribes to vpp-evpnh’s event stream. vpp-evpnh in
turn has zero outbound dependencies: it never dials VPP, Bird, or vpp-evpnr. All dataplane
actuation that a health event implies – including self-fence – is an event that is sent back to
vpp-evpnd, which is the sole actuator. This strict isolation means I can run vpp-evpnh
standalone with grpcurl for debugging without touching the dataplane at all, and if I want to,
replace the whole implementation with something better, because who knows what some runtime
experience teaches me.
Alright, traveling further up the chain, vpp-evpnd feeds health snapshots up to vpp-evpnr as
HealthReport events, which ride the same EventBroker spine that carries log records and CRUD
events already. vpp-evpnr ingests these with IngestHealthSnapshot, maintains a per-group
aggregate verdict, and feeds some form of autonomous failover reaction loop. The report carries
everything the reaction loop needs: the group slug, the interface name, whether the interface is up,
the node’s current role, and for every expected peer its instance ID, chassis MAC, role, alive
status and last-seen timestamp. I can expose this information and the assessed health verdict in
vpp-evpnc, under a new CLI path like show group X health. On the topic of frontends, these
HealthReports, the health verdict and any possible failover decisions flowing from them can display
as a live beat matrix in the WebUI. Critically, neither vpp-evpnh nor vpp-evpnd ever decide a
cross-host failover; they only report information up the chain of command. The sole autonomous
action is self-fence, which is a demotion. All other operations come from vpp-evpnr (either
autonomously, or manually because I ask for a failover myself).
Beats are sent as authenticated IPv6 link-local multicast datagrams on the LCP tap for each group
(bvi-<evpnid>), inside the customary dedicated dataplane network namespace. The fixed 124-byte
wire format is:
| Field | Size | Notes |
|---|---|---|
| magic | u16 | 0xE7B7 – reject non-evpnh datagrams |
| version | u8 | v2, noting that v1 was a terrible first attempt :) |
| role | u8 | warmup / candidate / primary |
| priority | u16 | election tiebreaker |
| instance_id | 16 B | null-padded; stable per-node identity |
| instance_mac | 6 B | chassis-stable MAC from evpnd |
| boot_id | 16 B | per-boot nonce (restart detection + replay defence) |
| seq | u64 | monotonic per-sender counter |
| interval | u32 | sender’s current beat interval in ms |
| timestamp | u64 | UTC epoch ms |
| group_vmac | 6 B | non-zero only for primary beats |
| evpn_id | 16 B | group slug; a foreign group’s beat is discarded silently |
| vni | u32 | fabric VNI (useful for Prometheus observability) |
| flags | u16 | FlagLeaving=bit 0, other bits reserved |
| HMAC-SHA256 | 32 B | signs the preceding 92-byte header |
The design is reasonably similar to CARP, HSRP, and VRRP. All four use link-local multicast heartbeats, priority-based election, and a graceful-departure signal (FlagLeaving here, priority-0 in CARP and VRRP). The differences matter for this use case: CARP uses HMAC-SHA1, HSRP uses MD5, and VRRP v3 ships with no authentication by default. I use HMAC-SHA256 with multiple pre-shared keys supported so key rotation never drops a beat: add the new key as a second slot so all receivers accept both, switch senders to it, then retire the old slot.

vpp-evpnh does not – promotions always come from vpp-evpnr. Because one
multicast address is the destination for all heartbeats, the listener for group A quietly discards
group B’s heartbeat traffic. It knows how to distinguish them, because of the evpn_id that is the
same for all members in group A.
evpnd/evpnr: Integration

While I do think it’s a good decision that vpp-evpnh ships as its own package with a well-defined
gRPC service, I don’t want production to look like [GNU Hurd],
so in production vpp-evpnd will link in vpp-evpnh and run the health engine as a goroutine. The same
RegisterEvpnhServer registration that the standalone binary calls over a TCP listener is called
inside vpp-evpnd over an in-process channel, with no network socket needed. The effect is that
vpp-evpnd dials its embedded vpp-evpnh the same way vpp-evpnr dials vpp-evpnd: push config
down, drain events up. The gRPC API is the seam, and composite nodes are a thing. Hoi, Boq!
When vpp-evpnr adds an instance to a group, it calls vpp-evpnd’s ConfigurePeerHealth RPC, which
translates the group’s desired-state into a pgConfig struct and calls eng.AddPeerGroup().
When the primary role changes, SetPeerPrimary() flips exactly one group’s primary bit without
touching any other group’s beats or membership. Health events (peer-up, peer-down, isolated,
self-fence-fired) flow up through vpp-evpnd’s EventBroker to vpp-evpnr in the aggregated fleet
stream. If the vpp-evpnh subsystem needed to be replaced – say with a BFD-based or VRRP-based
prober, then the only change would be swapping the internal/health package with another that satisfies
the same gRPC service contract. The rest of the stack is not touched, and that might just come
in handy in the future.
evpnd: Additional observability
Both vpp-evpnd and vpp-evpnr expose a Prometheus /metrics endpoint. Putting on my SRE hat, the
coverage I care about most: beat counters (beats_sent_total, beats_accepted_total,
beats_dropped_total by reason), a gauge for each group’s peer-reachability and self-fence-armed
state, primary-move counters distinguishing operator-driven from autonomous failovers, GroupBVI
actuation latency, and VPP and Bird connection age. Either of them restarting is directly observable
as an uptime discontinuity.
Alongside the HealthReport, each vpp-evpnd emits a TrafficReport on a similar periodic timer.
This report carries per-BVI ingress and egress packet- and octet-rate as exponentially weighted moving
averages over three somewhat arbitrarily chosen windows: 60s, 600s, and 3600s. vpp-evpnr ingests these in the same way it
ingests health reports and can easily surface these reports via GetGroupTraffic. The traffic split between members
is itself a diagnostic: the primary’s GroupBVI carries nearly all the load, while each candidate’s
InstanceBVI sees only a trickle – mostly health check multicast. A candidate showing significant
traffic is a sign that something is wrong with the primary’s path. In the CLI I can surface this as
show group X traffic, analogous to show group X health, which I guess is pretty intuitive.
evpnf: A WebUI
I will admit, I would never have thought of writing a WebUI, let alone a pretty one. But this is where Claude and Gemini really come in handy. When writing the [VPP Maglev] service, I learned a tonne about [SolidJS] and Server-Sent Events (SSE) streams.
Alright fine then, GenAI vibe-coding-friends, for vpp-evpn, I decide to invest in vpp-evpnf, a
web dashboard using the same design patterns. Both are written in SolidJS, both serve their static
bundle embedded in the binary, both connect to their respective registry over HTTP+SSE and expose a
public read-only /view/ path alongside an authenticated mutating /admin/ path. The single
biggest new feature in vpp-evpnf that maglevd-frontend does not have is TOFU:
trust-on-first-use admin credential setup, no more storing admin credentials in environment
variables. I should probably loop around the Maglev frontend and retrofit that ….
Before any admin credential is set, the /admin/ surface returns an unconditional HTTP 404 – not
a login prompt. The one-time setup endpoint is open and offers a simple username/password form.
The password is bcrypt-hashed and the hash is stored in a JSON state file alongside vpp-evpnr’s
registry. Once the first credential is written, the setup endpoint locks: a second call returns
admin already configured. From that point /admin/ requires HTTP Basic Auth against the stored
hash, and the timing is constant regardless of whether the username exists. I take no shortcuts
here: bcrypt.CompareHashAndPassword is deliberately slow, and the no-user path still runs a
dummy comparison to avoid a timing side-channel on username existence.
vpp-evpn - implementation
What follows is for software engineers who want to understand the internals and possibly yell at me for holding Go wrong. If you are more interested in the operational picture, feel free to skip over this to the Results section for a demo.
1. evpnh - health checker
The entry point is internal/health/engine.go. The Engine struct is the single concurrency
point: a sync.Mutex serializes all mutations (add/update/remove peer-group, set-primary), and a
per-group worker carries its own lock for the inner state machine. The node-global
controllerConnected flag is an atomic.Bool so the worker goroutines can read it lock-free
without creating a lock-ordering hazard between engine and worker.
Each group gets a worker in internal/health/worker.go. The worker runs two goroutines: loop()
and recvLoop(). loop() ticks at a configurable evalInterval (default 250 ms). On each tick
it calls pgState.tick() to advance the self-fence clock and compute expiry events, and sends a
beat whenever the role’s send interval has elapsed. recvLoop() blocks on Transport.Recv(),
decodes and verifies each datagram, and calls pgState.recv() to fold it into the membership
table.
The group health state machine lives in internal/health/group.go as pgState. recv() matches
the incoming beat to a member entry (creating one if new), updates alive, records the last-seen
timestamp, and emits peer-up or peer-down events when the alive bit transitions. tick() walks
all members and marks any whose last-seen is older than peerMiss x beatInterval as dead; it also
advances the three-condition self-fence clock (primary AND controller-lost AND alone) and emits
self-fence-fired event when the deadline expires, which is the cue for vpp-evpnd to demote
itself because something is really wrong if it ever finds itself in this scenario.
The wire format is in internal/health/beat.go. Beat.Encode() writes the 92-byte header into a
fixed [124]byte buffer, appends an HMAC-SHA256 signature keyed by the first PSK slot, and returns
the slice. Decode() checks magic and version first, then the evpn_id field (silently dropping a
foreign group’s beat before touching the signature), and finally calls verifyAny() which tries
the header against every configured keyslot with subtle.ConstantTimeCompare. A beat that matches
none is counted under beats_dropped_total with reason bad-sig; a foreign-group beat gets its
own beats_foreign_total counter and is never logged (it is expected and high-volume on any node
participating in more than one group).
The transport is internal/health/transport_linux.go, a mcastTransport wrapping an IPv6
link-local multicast UDP socket bound to the group’s LCP tap. The tap is volatile – a primary-bind
or -release, or VPP restart might destroy and recreate the LCP tap, changing the ifindex. A
background watcher goroutine calls net.InterfaceByName every now and again and rebuilds the socket
on an ifindex change or an up-transition, so beats resume after a role swap with no external
action.
2. evpnc - CLI extensions
The HealthReport and TrafficReport events flow up the same spine as every other event:
vpp-evpnh > vpp-evpnd > vpp-evpnr fleet broker and then down to clients. vpp-evpnc’s
WatchEvents subscription receives them tagged with type="healthreport" and
type="trafficreport". That said, the show group X health and show group X traffic commands do
not open a streaming subscription; they call GetGroupHealth and GetGroupTraffic as point-in-time
RPCs, because the result is a snapshot and not a stream. The CLI renders text output by default and
proto-JSON with -json, consistent with the rest of the command tree.
evpn> show group colo_chbtl0 health
group colo_chbtl0 healthy failover=armed
instance chbtl1 candidate iface=up ns=dataplane
peer chbtl0 primary alive mac=b8:ce:f6:82:98:02 last-seen=2026-06-10 13:33:43Z (0s)
instance chbtl0 primary iface=up ns=dataplane
peer chbtl1 candidate alive mac=02:7b:68:5a:79:84 last-seen=2026-06-10 13:33:40Z (3s)
evpn> show group colo_chbtl0 traffic
group colo_chbtl0
primary chbtl0 connected ifname=bvi-colo_chbtl0
ingress 60s=862pps/2.24Mbps 600s=788pps/3.01Mbps 3600s=726pps/2.54Mbps
egress 60s=16.21kpps/150.52Mbps 600s=14.52kpps/135.48Mbps 3600s=12.77kpps/118.10Mbps
candidate chbtl1 connected ifname=bvi-colo_chbtl0
ingress 60s=12pps/5.55kbps 600s=13pps/5.97kbps 3600s=13pps/6.25kbps
egress 60s=0pps/595bps 600s=0pps/605bps 3600s=0pps/600bps
The traffic split tells the story cleanly: chbtl0 carries 150 Mbps egress; chbtl1 barely
breaks 600 bps. That trickle is the health-check multicast, nothing more.
3. evpnf - a WebUI
vpp-evpnf is a SolidJS single-page application compiled to a static bundle and embedded into the Go
binary via embed.FS. On startup the server mounts web/dist under /view/ and the built-in
/view/api/* JSON endpoints handle REST calls; no external file serving is needed, which matters
a lot for a binary that is supposed to run as a container in Docker, only calling vpp-evpnr for
any and all information. Here’s where all that message passing and events and structured JSON and
CRUDL operations really pay dividends. Making a web-frontend is a breeze! And as I write this, I’m
again thinking that I would never write those words and mean it 🥰
Just like the CLI, the frontend connects to vpp-evpnr over gRPC (server-side), fetches an initial
snapshot from /view/api/state, and then opens an SSE stream at /view/api/events. SolidJS
reactive stores (stores/state.ts, stores/health.ts, stores/mode.ts) hold the fleet snapshot
and fold live SSE events into it. The DOM updates reactively: adding a new group member triggers a
list reconciliation in GroupsView; a groupbvi-bound event on a failover type causes the
affected group’s status badge to animate from healthy to recovering and back. I keep the
animation simple on purpose – a brief CSS transition on background color – because the main job of
the UI is to make state legible, not to be flashy.
The SSE Broker in cmd/evpnf/broker.go maintains a bounded replay ring (up to 2000 events,
capped at 30 seconds old). Last-Event-ID replay lets a browser that lost connectivity for a few
seconds catch up on missed events without a full reload. There is one important special case:
healthreport events fire every 1-5 seconds per member per group, which would flood the replay
ring and slow down reconnects with stale heartbeats. The coalesceKey() function returns a
(group, instance) key for healthreport events, triggering latest-wins coalescing in the ring:
the buffer retains only the newest snapshot from each source, while the live fan-out still
delivers every heartbeat as it arrives.
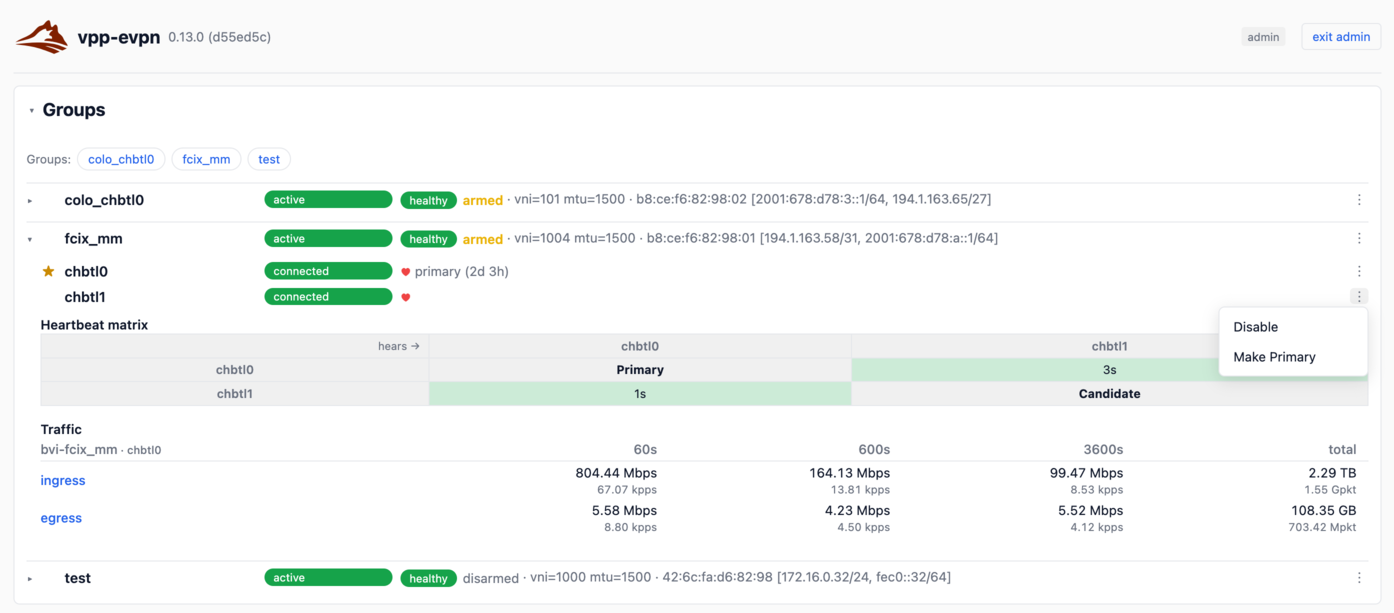
The UI is split into a Groups section and an Instances section, each wrapped in a
Zippy component – a <details>/<summary> element with a cookie-backed open/closed state.
The cookie key is a section: prefix plus the component’s stable id prop, so the browser
remembers which groups and instances were expanded across page reloads and sessions. The Groups
section shows each group as a zippy card: status badge, vMAC, MTU, gateway addresses, and a member
list with role badges. The Instances section shows each vpp-evpnd node with its VPP and Bird version
and connection status.
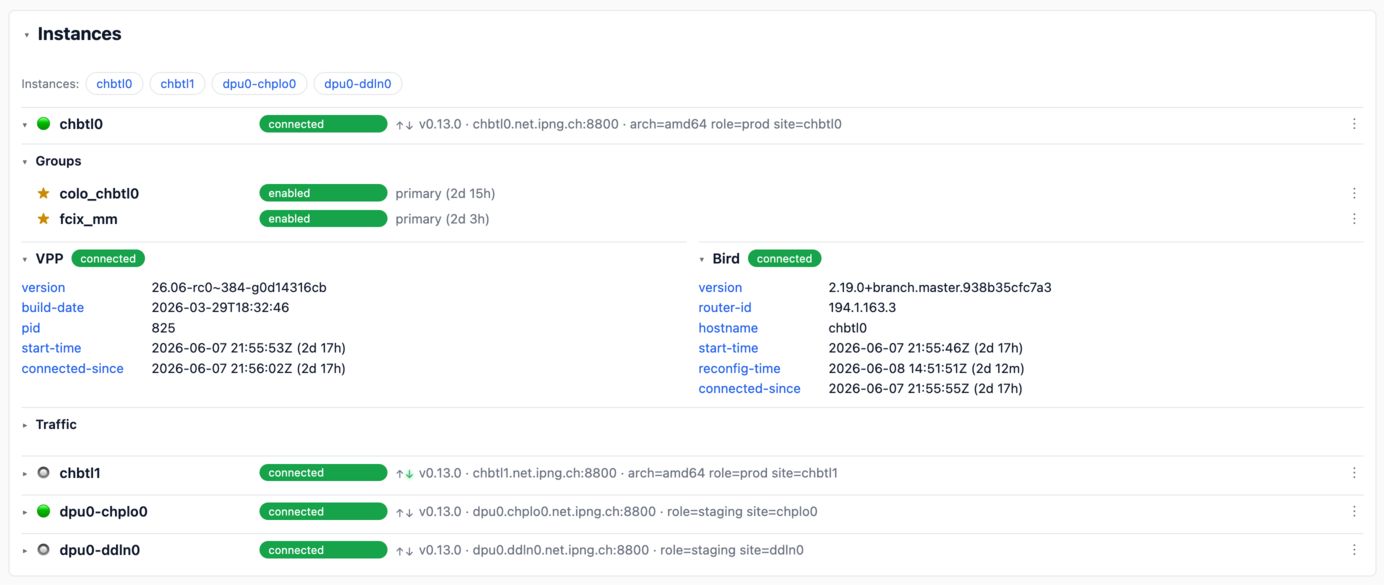
What’s that, you say, UTF-8 emojis?! The WebUI gives me a bit more opportunity to decorate the tables. I’ve used things like a ⭐ to show which instance is primary in a group, and little beating ❤️ emoji’s for health checks that are being emitted, and any API interaction shows little ↑ and ↓ arrows blinking. In the instance views, I used a visual cue also: here I will use colorized dots to show which instances are ‘hot’ that is to say they are in use 🟢, perhaps they are candidate with no primaries assigned 🔘, which makes them eligible for a maintenance window without interrupting traffic. If any one of the instances would have a warning 🟠 or worse, an error state 🔴, it would become immediately obvious.
In admin mode, Kebab menus (yummy!) appear to the right of each group member and instance. They
expose some common operations: make-primary, enable or disable instance/group, enable/disable health
checking and arm/disarm the group, which will turn on or off autonomous failover detection in
vpp-evpnr. The admin path is accessible only after the initial setup, and as with the CLI, all
mutations strictly go through vpp-evpnr via the /admin/api/* handlers and return immediately
with the updated state, which the SSE stream then propagates to all open browser tabs.
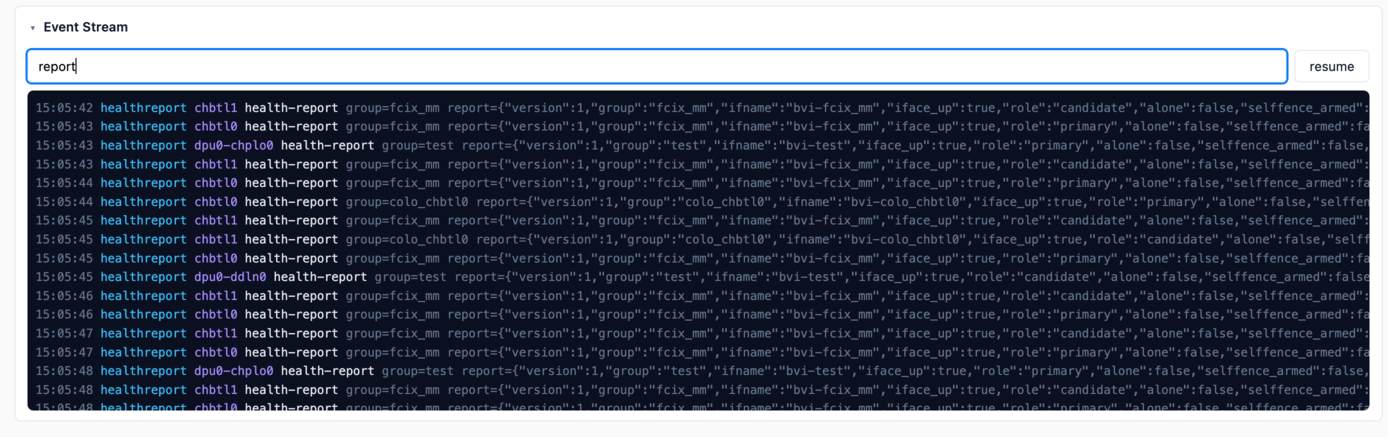
The Event Stream panel at the bottom of the page is visible only in admin mode. It shows a live
feed of all events from vpp-evpnr’s fleet broker: log records, CRUD events, health transitions, and
autonomous failover events. A text input applies a JavaScript RegExp filter in the browser so
I can focus on, say, only failover events or events mentioning a specific instance ID. A Pause
button freezes the display (the SSE stream keeps running underneath) so I can read a burst of
events without the window scrolling away. The chronological order and the event type field make
it easy to reconstruct exactly what the system did and when during a failover.
The biggest lesson from building vpp-evpnf after maglevd-frontend is that SSE replay is worth
engineering carefully. In maglevd-frontend every event was buffered and replayed naively; that
was fine for low-volume backends but would have been unusable for vpp-evpnf given the
healthreport volume. The coalescing design keeps the replay ring useful without bounding it by
event count alone. The Trust On First Use interstitial is the other addition that I’m pleased
with.
Results
Similar to the main implementation, take a look at this asciinema screencast showing a test group creation, simulated failover, cooldown semantics, and observability with metrics and events on the Event Watcher.
What’s next
The four articles in this series started from a whiteboard idea back in 2025, “What if VPP could speak eVPN?” and ended with a system that joins VPP routers into an eVPN broadcast domain, moves L3 gateways between them without dropping the vMAC address, and detects an unfit primary at 3am and fixes it without waking anyone up. That is a satisfying story arc, daayum!
Along the way I made a parking lot of ideas which I’ve left on the table for now, in the interest of shipping something. One thing that would be nice, again reusing the HAProxy-style health checker that I already wrote the code for in the VPP Maglev loadbalancer, is probing from the VPP instances to see if they have upstream (internet) connectivity or not. This would allow another signal for graceful self-healing failover between nodes, if, say, one of them was powered on and connected to the IPng Site Local underlay, but lost its Internet connectivity.
Another idea I’m toying with is leader election for the vpp-evpnr component, so that it (or the
network around it) can fail without posing a risk for health verdicts and failover. I’m still not
sure about this one though, as the risk is a compounding of two events: vpp-evpnr becoming
incapacitated, AND vpp-evpnd suffering a network outage that would call for an orchestrated
failover. I don’t see that as a super common combination.
The system could be a bit faster, but not much I think. The GroupBVI move is about 1500ms, and the non-orchestrated failover is about eight seconds. Some of this sits in the BGP announce/retract of the MAC addresses in eVPN, but also in the OSPF announce/retract of the GroupBVI prefixes themselves. I think I can probably get it down to five seconds or so, but in IPng’s network I’ll still opt to keep them at a lower sensitivity, as I prefer stability over spurious failovers.
Comparing to the Maglev project, there’s a few changes I can backport with the benefit of hindsight:
the “central broker” pattern of vpp-evpn is a bit more user friendly than the “Ship YAML config
files” pattern of vpp-maglev, although the latter can operate completely decentralized.
Interesting tradeoff I should think more about. The TOFU model is defintely going to be backported
to the Maglev frontend, as keeping user/pass credentials in .env files is gross.
For now, the system is running in production on the IPng DPU fleet, there are four nodes deployed and running this code, with an additional 6 or so lined up. And what’s better: my phone has not lit up at 3am yet. So I’m going to call that a win.