- Author: Pim van Pelt <pim@ipng.nl>
- Reviewers: Coloclue Network Committee <routers@coloclue.net>
- Status: Draft - Review - Published
Introduction
Coloclue AS8283 operates several Linux routers running Bird. Over the years, the performance of their previous hardware platform (Dell R610) has deteriorated, and they were up for renewal. At the same time, network latency/jitter has been very high, and variability may be caused by the Linux router hardware, their used software, the inter-datacenter links, or any combination of these. The routers were replaced with relatively modern hardware. In a previous post, I looked into the links between the datacenters, and demonstrated that they are performing as expected (1.41Mpps of 802.1q ethernet frames in both directions). That leaves the software. This post explores a replacement of the Linux kernel routers by a userspace process running VPP, which is an application built on DPDK.
Executive Summary
I was unable to run VPP due to an issue detecting and making use of the Intel x710 network cards in this chassis. While the Intel i210-AT cards worked well, both with the standard vfio-pci driver and with an alternative igb_uio driver, I did not manage to get the Intel x710 cards to fully work (noting that I have the same Intel x710 NIC working flawlessly in VPP on another Supermicro chassis). See below for a detailed writeup of what I tried and which results were obtained. In the end, I reverted the machine back to its (mostly) original state, with three pertinent changes:
- I left the Debian Backports kernel 5.10 running
- I turned on IOMMU (Intel VT-d was already on), booting with
iommu=pt intel_iommu=on - I left Hyperthreading off in the BIOS (it was on when I started)
After I restored the machine to its original Linux+Bird configuration, I noticed a marked improvement in latency, jitter and throughput. A combination of these changes is likely beneficial, so I do recommend making this change on all Coloclue routers, while we continue our quest for faster, more stable network performance.
So the bad news is: I did not get to prove that VPP and DPDK are awesome in AS8283. Yet.
But the good news is: network performance improved drastically. I’ll take it :)
Timeline
|
|
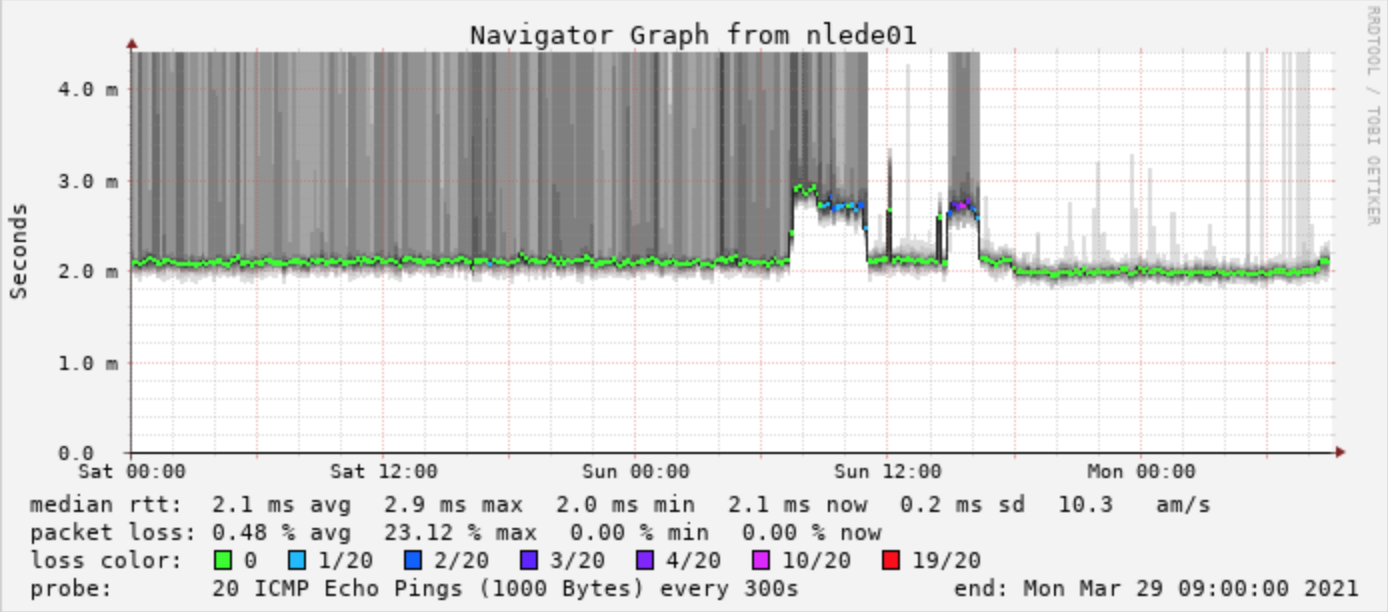
The graph on the left shows latency from AS15703 (True) in EUNetworks to a Coloclue machine hosted in NorthC. As far as Smokeping is concerned, latency has been quite poor for as long as it can remember (at least a year). The graph on the right shows the latency from AS12859 (BIT) to the beacon on 185.52.225.1/24 which is announced only on dcg-1, on the day this project was carried out.
Looking more closely at the second graph:
Sunday 07:30: The machine was put into maintenance, which made the latency jump. This is because the beacon was no longer reachable directly behind dcg-1 from AS12859 over NL-IX, but via an alternative path which traversed several more Coloclue routers, hence higher latency and jitter/loss.
Sunday 11:00: I rolled back the VPP environment on the machine, restoring it to its original configuration, except running kernel 5.10 and with Intel VT-d and Hyperthreading both turned off in the BIOS. A combination of those changes has definitely worked wonders. See also the mtr results down below.
Sunday 14:50: Because I didn’t want to give up, and because I expected a little more collegiality from my friend dcg-1, I gave it another go by enabling IOMMU and PT, booting the 5.10 kernel with iommu=pt and intel_iommu=on. Now, with the igb_uio driver loaded, VPP detected both the i210 and x710 NICs, however it did not want to initialize the 4th port on the NIC (this was enp1s0f3, the port to Fusix Networks), and the port eno1 only partially worked (IPv6 was fine, IPv4 was not). During this second attempt though, the rest of VPP and Bird came up, including NL-IX, the LACP, all internal interfaces, IPv4 and IPv6 OSPF and all BGP peering sessions with members.
Sunday 16:20: I could not in good faith turn on eBGP peers though, because of the interaction with eno1 and enp1s0f3 described in more detail below. I then ran out of time, and restored service with Linux 5.10 kernel and the original Bird configuration, now with Intel VT-d turned on and IOMMU/PT enabled in the kernel.
Quick Overview
This paper, at a high level, discusses the following:
- Gives a brief introduction of VPP and its new Linux CP work
- Discusses a means to isolate a /24 on exactly one Coloclue router
- Demonstrates changes made to run VPP, even though they were not applied
- Compares latency/throughput before-and-after in a surprising improvement, unrelated to VPP
1. Introduction to VPP
VPP stands for Vector Packet Processing. In development since 2002, VPP is production code currently running in shipping products. It runs in user space on multiple architectures including x86, ARM, and Power architectures on both x86 servers and embedded devices. The design of VPP is hardware, kernel, and deployment (bare metal, VM, container) agnostic. It runs completely in userspace. VPP helps push extreme limits of performance and scale. Independent testing shows that, at scale, VPP-powered routers are two orders of magnitude faster than currently available technologies.
The Linux (and BSD) kernel is not optimized for network I/O. Each packet (or in some implementations, a small batch of packets) generates an interrupt which causes the kernel to stop what it’s doing, schedule the interrupt handler, do the necessary steps in the networking stack for each individual packet in turn: layer2 input, filtering, NAT session matching and packet rewriting, IP next-hop lookup, interface and L2 next-hop lookup, and marshalling the packet back onto the network, or handing it over to an application running on the local machine. And it does this for each packet one after another.
VPP takes away a few inefficiencies in this process in a few ways:
- VPP does not use interrupts, does not use the kernel network driver, and does not use the kernel networking stack at all. Instead, it attaches directly to the PCI device and polls the network card directly for incoming packets.
- Once network traffic gets busier, VPP constructs a collection of packets called a vector, to pass through a directed graph of smaller functions. There’s a clear performance benefit of such an architecture: the first packet from the vector will hit possibly a cold instruction/data cache in the CPU, but the second through Nth packet from the vector will execute on a hot cache and not need most/any memory access, executing at an order of magnitude faster or even better.
- VPP is multithreaded and can have multiple cores polling and executing receive and transmit queues for network interfaces at the same time. Routing information (like next hops, forwarding tables, etc) should be carefully maintained, but in principle, VPP linearly scales with the amount of cores.
It is straight forward to obtain 10Mpps of forwarding throughput per CPU core, so a 32 core machine (handling 320Mpps) can realistically saturate 21x10Gbit interfaces (at 14.88Mpps). A similar 32-core machine, if it has sufficient amounts of PCI slots and network cards can route an internet mixture of traffic at throughputs of roughly 492Gbit (320Mpps at 650Kpps per 10G of imix).
VPP, upon startup, will disassociate the NICs with the kernel and bind them into the vpp process, which will promptly run at 100% CPU, due to its DPDK polling. There’s a tool vppcli which allows the operator to configure the VPP process: create interfaces, set attributes like link state, MTU, MPLS, Bonding, IPv4/IPv6 addresses and add/remove routes in the forwarding information base (or FIB). VPP further works with plugins, that add specific functionality, examples of this is LLDP, DHCP, IKEv2, NAT, DSLITE, Load Balancing, Firewall ACLs, GENEVE, VXLAN, VRRP, and Wireguard, to name but a few popular ones.
Introduction to Linux CP Plugin
However, notably (or perhaps notoriously), VPP is only a dataplane application, it does not have any routing protols like OSPF or BGP. A relatively new plugin is called the Linux Control Plane (or LCP), and it consists of two parts, one is public and one is under development at the time of this article. The first plugin allows the operator to create a Linux tap interface and pass though or punt traffic from the dataplane into it. This way, the userspace VPP application creates a link back into the kernel, and an interface (eg. vpp0) appears. Input packets in VPP have all input features (firewall, NAT, session matching, etc), and if the packet is sent to an IP address with an LCP pair associated with it, it is punted to the tap device. So if on the Linux side, the same IP address is put on the resulting vpp0 device, Linux will see it. Responses from the kernel into the tap device are picked up by the Linux CP plugin and re-injected into the dataplane, and all output features of VPP are applied. This makes bidirectional traffic possible. You can read up on the Linux CP plugin in the VPP documentation.
Here’s a barebones example of plumbing the VPP interface GigabitEthernet7/0/0 through a network device vpp0 in the dataplane network namespace.
pim@vpp-west:~$ sudo systemctl restart vpp
pim@vpp-west:~$ vppctl lcp create GigabitEthernet7/0/0 host-if vpp0 namespace dataplane
pim@vpp-west:~$ sudo ip netns exec dataplane ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: vpp0: <BROADCAST,MULTICAST> mtu 9000 qdisc mq state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:8a:0e:97 brd ff:ff:ff:ff:ff:ff
pim@vpp-west:~$ vppctl show interface
Name Idx State MTU (L3/IP4/IP6/MPLS) Counter Count
GigabitEthernet7/0/0 1 down 9000/0/0/0
local0 0 down 0/0/0/0
tap1 2 up 9000/0/0/0
Introduction to Linux NL Plugin
You may be wondering, what happens with interface addresses or static routes? Usually, a userspace application like ip link add or ip address add or a higher level process like bird or FRR will want to set routes towards next hops upon interfaces using routing protocols like OSPF or BGP. The Linux kernel picks these events up and can share them as so called netlink messages with interested parties. Enter the second plugin (the one that is under development at the moment), which is a netlink listener. Its job is to pick up netlink messages from the kernel and apply them to the VPP dataplane. With the Linux NL plugin enabled, events like adding or removing links, addresses, routes, set linkstate or MTU, will all mirrored into the dataplane. I’m hoping the netlink code will be released in the upcoming VPP release, but contact me any time if you’d like to discuss details of the code, which can be found currently under community review in the VPP Gerrit
Building on the example above, with this Linux NL plugin enabled, we can now manipulate VPP state from Linux, for example creating an interface and adding an IPv4 address to it (of course, IPv6 works just as well!):
pim@vpp-west:~$ sudo ip netns exec dataplane ip link set vpp0 up mtu 1500
pim@vpp-west:~$ sudo ip netns exec dataplane ip addr add 2001:db8::1/64 dev vpp0
pim@vpp-west:~$ sudo ip netns exec dataplane ip addr add 10.0.13.2/30 dev vpp0
pim@vpp-west:~$ sudo ip netns exec dataplane ping -c1 10.0.13.1
PING 10.0.13.1 (10.0.13.1) 56(84) bytes of data.
64 bytes from 10.0.13.1: icmp_seq=1 ttl=64 time=0.591 ms
--- 10.0.13.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.591/0.591/0.591/0.000 ms
pim@vpp-west:~$ vppctl show interface
Name Idx State MTU (L3/IP4/IP6/MPLS) Counter Count
GigabitEthernet7/0/0 1 up 1500/0/0/0 rx packets 4
rx bytes 268
tx packets 14
tx bytes 1140
drops 2
ip4 2
local0 0 down 0/0/0/0
tap1 2 up 9000/0/0/0 rx packets 10
rx bytes 796
tx packets 2
tx bytes 140
ip4 1
ip6 8
pim@vpp-west:~$ vppctl show interface address
GigabitEthernet7/0/0 (up):
L3 10.0.13.2/30
L3 2001:db8::1/64
local0 (dn):
tap1 (up):
As can be seen above, setting the link state up, setting the MTU, adding an address were all captured by the Linux NL plugin and applied in the dataplane. Further to this, the Linux NL plugin also synchronizes route updates into the forwarding information base (or FIB) of the dataplane:
pim@vpp-west:~$ sudo ip netns exec dataplane ip route add 100.65.0.0/24 via 10.0.13.1
pim@vpp-west:~$ vppctl show ip fib 100.65.0.0
ipv4-VRF:0, fib_index:0, flow hash:[src dst sport dport proto flowlabel ] epoch:0 flags:none locks:[adjacency:1, default-route:1, lcp-rt:1, ]
100.65.0.0/24 fib:0 index:15 locks:2
lcp-rt refs:1 src-flags:added,contributing,active,
path-list:[27] locks:2 flags:shared, uPRF-list:19 len:1 itfs:[1, ]
path:[34] pl-index:27 ip4 weight=1 pref=0 attached-nexthop: oper-flags:resolved,
10.0.13.1 GigabitEthernet7/0/0
[@0]: ipv4 via 10.0.13.1 GigabitEthernet7/0/0: mtu:1500 next:5 flags:[] 52540015f82a5254008a0e970800
Note: I built the code for VPP v21.06 including the Linux CP and Linux NL plugins at tag 21.06-rc0~476-g41cf6e23d on Debian Buster for the rest of this project, to match the operating system in use on Coloclue routers. I did this without additional modifications (even though I must admit, I do know of a few code paths in the netlink handler that still trigger a crash, and I have a few fixes in my client at home, so I’ll be careful to avoid the pitfalls for now :-).
2. Isolating a Device Under Test
Coloclue has several routers, so to ensure that the traffic traverses only the one router under test, I decided to use an allocated but currently unused IPv4 prefix and announce that only from one of the four routers, so that all traffic to and from that /24 goes over that router. Coloclue uses a piece of software called Kees, a set of Python and Jinja2 scripts to generate a Bird1.6 configuration for each router. This is great because that allows me to add a small feature to get what I need: beacons.
A beacon is a prefix that is sent to (some, or all) peers on the internet to attract traffic in a particular way. I added a function called is_coloclue_beacon() which reads the input YAML file and uses a construction similar to the existing feature for “supernets”. It determines if a given prefix must be announced to peers and upstreams. Any IPv4 and IPv6 prefixes from the beacons list will be then matched in is_coloclue_beacon() and announced.
Based on a per-router config (eg. vars/dcg-1.router.nl.coloclue.net.yml) I can now add the following YAML stanza:
coloclue:
beacons:
- prefix: "185.52.225.0"
length: 24
comment: "VPP test prefix (pim)"
Because tinkering with routers in the Default Free Zone is a great way to cause an outage, I need to ensure that the code I wrote was well tested. I first ran ./update-routers.sh check with no beacon config. This succeeded:
[...]
checking: /opt/router-staging/dcg-1.router.nl.coloclue.net/bird.conf
checking: /opt/router-staging/dcg-1.router.nl.coloclue.net/bird6.conf
checking: /opt/router-staging/dcg-2.router.nl.coloclue.net/bird.conf
checking: /opt/router-staging/dcg-2.router.nl.coloclue.net/bird6.conf
checking: /opt/router-staging/eunetworks-2.router.nl.coloclue.net/bird.conf
checking: /opt/router-staging/eunetworks-2.router.nl.coloclue.net/bird6.conf
checking: /opt/router-staging/eunetworks-3.router.nl.coloclue.net/bird.conf
checking: /opt/router-staging/eunetworks-3.router.nl.coloclue.net/bird6.conf
And I made sure that the generated function is indeed empty:
function is_coloclue_beacon()
{
# Prefix must fall within one of our supernets, otherwise it cannot be a beacon.
if (!is_coloclue_more_specific()) then return false;
return false;
}
Then, I ran the configuration again with one IPv4 beacon set on dcg-1, and still all the bird configs on both IPv4 and IPv6 for all routers parsed correctly, and the generated function on the dcg-1 IPv4 filters file was populated:
function is_coloclue_beacon()
{
# Prefix must fall within one of our supernets, otherwise it cannot be a beacon.
if (!is_coloclue_more_specific()) then return false;
if (net = 185.52.225.0/24) then return true; /* VPP test prefix (pim) */
return false;
}
I then wired up the function into function ebgp_peering_export() and submitted the beacon configuration above, as well as a static route for that beacon prefix to a server running in the NorthC (previously called DCG) datacenter. You can read the details in this Kees commit. The dcg-1 router is connected to NL-IX, so it’s expected that after this configuration went live, peers can now see that prefix only via NL-IX, and it’s a more specific to the overlapping supernet (which is 185.52.224.0/22).
And indeed, a traceroute now only traverses dcg-1 as seen from peer BIT (AS12859 coming from NL-IX):
1. lo0.leaf-sw4.bit-2b.network.bit.nl
2. lo0.leaf-sw6.bit-2a.network.bit.nl
3. xe-1-3-1.jun1.bit-2a.network.bit.nl
4. coloclue.the-datacenter-group.nl-ix.net
5. vpp-test.ams.ipng.ch
As well as return traffic from Coloclue to that peer:
1. bond0-100.dcg-1.router.nl.coloclue.net
2. bit.bit2.nl-ix.net
3. lo0.leaf-sw6.bit-2a.network.bit.nl
4. lo0.leaf-sw4.bit-2b.network.bit.nl
5. sandy.ipng.nl
3. Installing VPP
First, I need to ensure that the machine is reliably reachable via its IPMI interface (normally using serial-over-lan, but to make sure as well Remote KVM). This is required because all network interfaces above will be bound by VPP, and if the vpp process ever were to crash, it will be restarted without configuration. On a production router, one would expect there to be a configuration daemon that can persist a configuration and recreate it in case of a server restart or dataplane crash.
Before we start, let’s build VPP with our two beautiful plugins, copy them to dcg-1, and install all the supporting packages we’ll need:
pim@vpp-builder:~/src/vpp$ make install-dep
pim@vpp-builder:~/src/vpp$ make build
pim@vpp-builder:~/src/vpp$ make build-release
pim@vpp-builder:~/src/vpp$ make pkg-deb
pim@vpp-builder:~/src/vpp$ dpkg -c build-root/vpp-plugin-core*.deb | egrep 'linux_(cp|nl)_plugin'
-rw-r--r-- root/root 92016 2021-03-27 12:06 ./usr/lib/x86_64-linux-gnu/vpp_plugins/linux_cp_plugin.so
-rw-r--r-- root/root 57208 2021-03-27 12:06 ./usr/lib/x86_64-linux-gnu/vpp_plugins/linux_nl_plugin.so
pim@vpp-builder:~/src/vpp$ scp build-root/*.deb root@dcg-1.nl.router.coloclue.net:/root/vpp/
pim@dcg-1:~$ sudo apt install libmbedcrypto3 libmbedtls12 libmbedx509-0 libnl-3-200 \
libnl-route-3-200 libnuma1 python3-cffi python3-cffi-backend python3-ply python3-pycparser
pim@dcg-1:~$ sudo dpkg -i /root/vpp/*.deb
pim@dcg-1:~$ sudo usermod -a -G vpp pim
On a BGP speaking router, netlink messages can come in rather quickly as peers come and go. Due to an unfortunate design choice in the Linux kernel, messages are not buffered for clients, which means that a buffer overrun can occur. To avoid this, I’ll raise the netlink socket size to 64MB, leverging a feature that will create a producer queue in the Linux NL plugin, so that VPP can try to drain the messages from the kernel into its memory as quickly as possible. To be able to raise the netlink socket buffer size, we need to set some variables with sysctl (take note as well on the usual variables VPP wants to set with regards to hugepages in /etc/sysctl.d/80-vpp.conf, which the Debian package installs for you):
pim@dcg-1:~$ cat << EOF | sudo tee /etc/sysctl.d/81-vpp-netlink.conf
# Increase netlink to 64M
net.core.rmem_default=67108864
net.core.wmem_default=67108864
net.core.rmem_max=67108864
net.core.wmem_max=67108864
EOF
pim@dcg-1:~$ sudo sysctl -p /etc/sysctl.d/81-vpp-netlink.conf /etc/sysctl.d/80-vpp.conf
VPP Configuration
Now that I’m sure traffic to and from 185.52.225.0/24 will go over dcg-1, let’s take a look at the machine itself. It has a six network cards, two onboard Intel i210 gigabit and one Intel x710-DA4 quad-tengig network cards. To run VPP, the network cards in the machine need to be supported in Intel’s DPDK libraries. The ones in this machine are all OK (but as we’ll see later, problematic for unexplained reasons):
root@dcg-1:~# lspci | grep Ether
01:00.0 Ethernet controller: Intel Corporation Ethernet Controller X710 for 10GbE SFP+ (rev 02)
01:00.1 Ethernet controller: Intel Corporation Ethernet Controller X710 for 10GbE SFP+ (rev 02)
01:00.2 Ethernet controller: Intel Corporation Ethernet Controller X710 for 10GbE SFP+ (rev 02)
01:00.3 Ethernet controller: Intel Corporation Ethernet Controller X710 for 10GbE SFP+ (rev 02)
06:00.0 Ethernet controller: Intel Corporation I210 Gigabit Network Connection (rev 03)
07:00.0 Ethernet controller: Intel Corporation I210 Gigabit Network Connection (rev 03)
To handle the inbound traffic, netlink messages and other internal memory structure, I’ll allocate 2GB of hugepages to the VPP process. I’ll then of course enable the two Linux CP plugins. Because VPP has a lot of statistics counters (for example, a few stats for each used prefix in its forwarding information base or FIB), I will need to give it more than the default of 32MB of stats memory. I’d like to execute a few startup commands to further configure the VPP runtime upon startup, so I’ll add a startup-config stanza. Finally, although on a production router I would, here I will not specify the DPDK interfaces, because I know that VPP will take over any supported network card that is in link down state upon startup. As long as I boot the machine with unconfigured NICs, I will be good.
So, here’s the configuration I end up adding to /etc/vpp/startup.conf:
unix {
startup-config /etc/vpp/vpp-exec.conf
}
memory {
main-heap-size 2G
main-heap-page-size default-hugepage
}
plugins {
path /usr/lib/x86_64-linux-gnu/vpp_plugins
plugin linux_cp_plugin.so { enable }
plugin linux_nl_plugin.so { enable }
}
statseg {
size 128M
}
# linux-cp {
# default netns dataplane
# }
Note: It is important to isolate the tap devices into their own Linux network namespace. If this is not done, packets arriving via the dataplane will not have a route up and into the kernel for interfaces VPP is not aware of, making those kernel-enabled interfaces unreachable. Due to the use of a network namespace, all applications in Linux will have to be run in that namespace (think: bird, sshd, snmpd, etc) and the firewall rules with iptables will also have to be carefully applied into that namespace. Considering for this test we are using all interfaces in the dataplane, this point is moot, and we’ll take a small shortcut and introduce the tap devices in the default namespace.
In the configuration file, I added a startup-config (also known as exec) stanza. This is a set of VPP CLI commands that will be executed every time the process starts. It’s a great way to get the VPP plumbing done ahead of time. I figured, if I let VPP take the network cards, but then re-present tap interfaces with names which have the same name that the Linux kernel driver would’ve given them, the rest of the machine will mostly just work.
So the final trick is to disable every interface in /etc/nework/interfaces on dcg-1 and then configure it with a combination of a /etc/vpp/vpp-exec.conf and a small shell script that puts the IP addresses and things back just the way Debian would’ve put them using the /etc/network/interfaces file. Here we go!
# Loopback interface
create loopback interface instance 0
lcp create loop0 host-if lo0
# Core: dcg-2
lcp create GigabitEthernet6/0/0 host-if eno1
# Infra: Not used.
lcp create GigabitEthernet7/0/0 host-if eno2
# LACP to Arista core switch
create bond mode lacp id 0
set interface state TenGigabitEthernet1/0/0 up
set interface mtu packet 1500 TenGigabitEthernet1/0/0
set interface state TenGigabitEthernet1/0/1 up
set interface mtu packet 1500 TenGigabitEthernet1/0/1
bond add BondEthernet0 TenGigabitEthernet1/0/0
bond add BondEthernet0 TenGigabitEthernet1/0/1
set interface mtu packet 1500 BondEthernet0
lcp create BondEthernet0 host-if bond0
# VLANs on bond0
create sub-interfaces BondEthernet0 100
lcp create BondEthernet0.100 host-if bond0.100
create sub-interfaces BondEthernet0 101
lcp create BondEthernet0.101 host-if bond0.101
create sub-interfaces BondEthernet0 102
lcp create BondEthernet0.102 host-if bond0.102
create sub-interfaces BondEthernet0 120
lcp create BondEthernet0.120 host-if bond0.120
create sub-interfaces BondEthernet0 201
lcp create BondEthernet0.201 host-if bond0.201
create sub-interfaces BondEthernet0 202
lcp create BondEthernet0.202 host-if bond0.202
create sub-interfaces BondEthernet0 205
lcp create BondEthernet0.205 host-if bond0.205
create sub-interfaces BondEthernet0 206
lcp create BondEthernet0.206 host-if bond0.206
create sub-interfaces BondEthernet0 2481
lcp create BondEthernet0.2481 host-if bond0.2481
# NLIX
lcp create TenGigabitEthernet1/0/2 host-if enp1s0f2
create sub-interfaces TenGigabitEthernet1/0/2 7
lcp create TenGigabitEthernet1/0/2.7 host-if enp1s0f2.7
create sub-interfaces TenGigabitEthernet1/0/2 26
lcp create TenGigabitEthernet1/0/2.26 host-if enp1s0f2.26
# Fusix Networks
lcp create TenGigabitEthernet1/0/3 host-if enp1s0f3
create sub-interfaces TenGigabitEthernet1/0/3 108
lcp create TenGigabitEthernet1/0/3.108 host-if enp1s0f3.108
create sub-interfaces TenGigabitEthernet1/0/3 110
lcp create TenGigabitEthernet1/0/3.110 host-if enp1s0f3.110
create sub-interfaces TenGigabitEthernet1/0/3 300
lcp create TenGigabitEthernet1/0/3.300 host-if enp1s0f3.300
And then to set up the IP address information, a small shell script:
ip link set lo0 up mtu 16384
ip addr add 94.142.247.1/32 dev lo0
ip addr add 2a02:898:0:300::1/128 dev lo0
ip link set eno1 up mtu 1500
ip addr add 94.142.247.224/31 dev eno1
ip addr add 2a02:898:0:301::12/127 dev eno1
ip link set eno2 down
ip link set bond0 up mtu 1500
ip link set bond0.100 up mtu 1500
ip addr add 94.142.244.252/24 dev bond0.100
ip addr add 2a02:898::d1/64 dev bond0.100
ip link set bond0.101 up mtu 1500
ip addr add 172.28.0.252/24 dev bond0.101
ip link set bond0.102 up mtu 1500
ip addr add 94.142.247.44/29 dev bond0.102
ip addr add 2a02:898:0:e::d1/64 dev bond0.102
ip link set bond0.120 up mtu 1500
ip addr add 94.142.247.236/31 dev bond0.120
ip addr add 2a02:898:0:301::6/127 dev bond0.120
ip link set bond0.201 up mtu 1500
ip addr add 94.142.246.252/24 dev bond0.201
ip addr add 2a02:898:62:f6::fffd/64 dev bond0.201
ip link set bond0.202 up mtu 1500
ip addr add 94.142.242.140/28 dev bond0.202
ip addr add 2a02:898:100::d1/64 dev bond0.202
ip link set bond0.205 up mtu 1500
ip addr add 94.142.242.98/27 dev bond0.205
ip addr add 2a02:898:17::fffe/64 dev bond0.205
ip link set bond0.206 up mtu 1500
ip addr add 185.52.224.92/28 dev bond0.206
ip addr add 2a02:898:90:1::2/125 dev bond0.206
ip link set bond0.2481 up mtu 1500
ip addr add 94.142.247.82/29 dev bond0.2481
ip addr add 2a02:898:0:f::2/64 dev bond0.2481
ip link set enp1s0f2 up mtu 1500
ip link set enp1s0f2.7 up mtu 1500
ip addr add 193.239.117.111/22 dev enp1s0f2.7
ip addr add 2001:7f8:13::a500:8283:1/64 dev enp1s0f2.7
ip link set enp1s0f2.26 up mtu 1500
ip addr add 213.207.10.53/26 dev enp1s0f2.26
ip addr add 2a02:10:3::a500:8283:1/64 dev enp1s0f2.26
ip link set enp1s0f3 up mtu 1500
ip link set enp1s0f3.108 up mtu 1500
ip addr add 94.142.247.243/31 dev enp1s0f3.108
ip addr add 2a02:898:0:301::15/127 dev enp1s0f3.108
ip link set enp1s0f3.110 up mtu 1500
ip addr add 37.139.140.23/31 dev enp1s0f3.110
ip addr add 2a00:a7c0:e20b:110::2/126 dev enp1s0f3.110
ip link set enp1s0f3.300 up mtu 1500
ip addr add 185.1.94.15/24 dev enp1s0f3.300
ip addr add 2001:7f8:b6::205b:1/64 dev enp1s0f3.300
4. Results
And this is where it went horribly wrong. After installing the VPP packages on the dcg-1 machine, running Debian Buster on a Supermicro Super Server/X11SCW-F with BIOS 1.5 dated 10/12/2020, the vpp process was unable to bind the PCI devices for the Intel x710 NICs. I tried the following combinations:
- Stock Buster kernel
4.19.0-14-amd64and Backports kernel5.10.0-0.bpo.3-amd64. - The kernel driver
vfio-pciand the DKMS forigb_uiofrom Debian packagedpdk-igb-uio-dkms. - Intel IOMMU off, on and strict (kernel boot parameter
intel_iommu=onandintel_iommu=strict) - BIOS setting for Intel VT-d on and off.
Each time, I would start VPP with an explicit dpdk {} stanza, and observed the following. With the default vfio-pci driver, the VPP process would not start, and instead it would be spinning loglines:
[ 74.378330] vfio-pci 0000:01:00.0: Masking broken INTx support
[ 74.384328] vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x19@0x1d0
## Repeated for all of the NICs 0000:01:00.[0123]
Commenting out the dpdk { dev 0000:01:00.* } devices would allow it to start, detect the two i210 NICs, which both worked fine.
With the igb_uio driver, VPP would start, but not detect the x710 devices at all, it would detect the two i210 NICs, but they would not pass traffic or even link up:
[ 139.495061] igb_uio 0000:01:00.0: uio device registered with irq 128
[ 139.522507] DMAR: DRHD: handling fault status reg 2
[ 139.528383] DMAR: [DMA Read] Request device [01:00.0] PASID ffffffff fault addr 138dac000 [fault reason 06] PTE Read access is not set
## Repeated for all 6 NICs
I repeated this test of both drivers for all combinations of kernel, IOMMU and BIOS settings for VT-d, with exactly identical results.
Baseline
In a traceroute from BIT to Coloclue (using Junipers on hops 1-3, Linux kernel routing on hop 4), it’s clear that (a) only NL-IX is used on hop 4, which means that only dcg-1 is in the path and no other routers at Coloclue. From hop 4 onwards, one can clearly see high variance, with a 49.7ms standard deviation on a ~247.1ms worst case, even though the end to end latency is only 1.6ms and the NL-IX port is not congested.
sandy (193.109.122.4) 2021-03-27T22:36:11+0100
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. lo0.leaf-sw4.bit-2b.network.bit.nl 0.0% 4877 0.3 0.2 0.1 7.8 0.2
2. lo0.leaf-sw6.bit-2a.network.bit.nl 0.0% 4877 0.3 0.2 0.2 1.1 0.1
3. xe-1-3-1.jun1.bit-2a.network.bit.nl 0.0% 4877 0.5 0.3 0.2 9.3 0.7
4. coloclue.the-datacenter-group.nl-ix.net 0.2% 4877 1.8 18.3 1.7 253.5 45.0
5. vpp-test.ams.ipng.ch 0.1% 4877 1.9 23.6 1.6 247.1 49.7
On the return path, seen by a traceroute from Coloclue to BIT (using Linux kernel routing on hop 2, Junipers on hops 2-4), it becomes clear that the very first hop (the Linux machine dcg-1) is contributing to high variance, with a 49.4ms standard deviation on a 257.9ms worst case, again on an NL-IX port that was not congested and easy sailing in BIT’s 10Gbit network from there on.
vpp-test (185.52.225.1) 2021-03-27T21:36:43+0000
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. bond0-100.dcg-1.router.nl.coloclue.net 0.1% 4839 0.2 12.9 0.1 251.2 38.2
2. bit.bit2.nl-ix.net 0.0% 4839 10.7 22.6 1.4 261.8 48.3
3. lo0.leaf-sw5.bit-2a.network.bit.nl 0.0% 4839 1.8 20.9 1.6 263.0 46.9
4. lo0.leaf-sw3.bit-2b.network.bit.nl 0.0% 4839 155.7 22.7 1.4 282.6 50.9
5. sandy.ede.ipng.nl 0.0% 4839 1.8 22.9 1.6 257.9 49.4
New Configuration
As I mentioned, I had expected this article to have a different outcome, in that I would’ve wanted to show off the superior routing performance under VPP of the beacon 185.52.225.1/24 which is found from AS12859 (BIT) via NL-IX directly through dcg-1. Alas, I did not manage to get the Intel x710 NIC to work with VPP, I ultimately rolled back but kept a few settings (Intel VT-d enabled and IOMMU on, hyperthreading disabled, Linux kernel 5.10 which uses a much newer version of the i40e for the NIC).
That combination definitely helped, the latency is now very smooth between BIT and Coloclue, a mean latency of 1.7ms, worst case 4.3ms and a standard deviation of 0.2ms only. That is as good as you could expect:
sandy (193.109.122.4) 2021-03-28T16:20:05+0200
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. lo0.leaf-sw4.bit-2b.network.bit.nl 0.0% 4342 0.3 0.2 0.2 0.4 0.1
2. lo0.leaf-sw6.bit-2a.network.bit.nl 0.0% 4342 0.3 0.2 0.2 0.9 0.1
3. xe-1-3-1.jun1.bit-2a.network.bit.nl 0.0% 4341 0.4 1.0 0.3 28.3 2.3
4. coloclue.the-datacenter-group.nl-ix.net 0.0% 4341 1.8 1.8 1.7 3.4 0.1
5. vpp-test.ams.ipng.ch 0.0% 4341 1.8 1.7 1.7 4.3 0.2
On the return path, seen by a traceroute again from Coloclue to BIT, it becomes clear that dcg-1 is no longer causing jitter or loss, at least not to NL-IX and AS12859. The latency there is as well an expected 1.8ms with a worst cast of 3.5ms and a standard deviation of 0.1ms, in other words comparable to the BIT –> Coloclue path:
vpp-test (185.52.225.1) 2021-03-28T14:20:50+0000
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. bond0-100.dcg-1.router.nl.coloclue.net 0.0% 4303 0.2 0.2 0.1 0.9 0.1
2. bit.bit2.nl-ix.net 0.0% 4303 1.6 2.2 1.4 17.1 2.2
3. lo0.leaf-sw5.bit-2a.network.bit.nl 0.0% 4303 1.8 1.7 1.6 6.6 0.4
4. lo0.leaf-sw3.bit-2b.network.bit.nl 0.0% 4303 1.6 1.5 1.4 4.2 0.2
5. sandy.ede.ipng.nl 0.0% 4303 1.9 1.8 1.7 3.5 0.1
Appendix
Assorted set of notes – because I did give it “one last try” and managed to get VPP to almost work on this Coloclue router :)
- Boot kernel 5.10 with
intel_iommu=on iommu=pt - Load kernel module
igb_uioand unloadvfio-pcibefore starting VPP
What follows is a bunch of debugging information – useful perhaps for a future attempt at running VPP at Coloclue.
root@dcg-1:/etc/vpp# tail -10 startup.conf
dpdk {
uio-driver igb_uio
dev 0000:06:00.0
dev 0000:07:00.0
dev 0000:01:00.0
dev 0000:01:00.1
dev 0000:01:00.2
dev 0000:01:00.3
}
root@dcg-1:/etc/vpp# lsmod | grep uio
uio_pci_generic 16384 0
igb_uio 20480 5
uio 20480 12 igb_uio,uio_pci_generic
[ 39.211999] igb_uio: loading out-of-tree module taints kernel.
[ 39.218094] igb_uio: module verification failed: signature and/or required key missing - tainting kernel
[ 39.228147] igb_uio: Use MSIX interrupt by default
[ 91.595243] igb 0000:06:00.0: removed PHC on eno1
[ 91.716041] igb_uio 0000:06:00.0: mapping 1K dma=0x101c40000 host=0000000095299b4e
[ 91.723683] igb_uio 0000:06:00.0: unmapping 1K dma=0x101c40000 host=0000000095299b4e
[ 91.733221] igb 0000:07:00.0: removed PHC on eno2
[ 91.856255] igb_uio 0000:07:00.0: mapping 1K dma=0x101c40000 host=0000000095299b4e
[ 91.863918] igb_uio 0000:07:00.0: unmapping 1K dma=0x101c40000 host=0000000095299b4e
[ 91.988718] igb_uio 0000:06:00.0: uio device registered with irq 127
[ 92.039935] igb_uio 0000:07:00.0: uio device registered with irq 128
[ 105.040391] i40e 0000:01:00.0: i40e_ptp_stop: removed PHC on enp1s0f0
[ 105.232452] igb_uio 0000:01:00.0: mapping 1K dma=0x103a64000 host=00000000bc39c074
[ 105.240108] igb_uio 0000:01:00.0: unmapping 1K dma=0x103a64000 host=00000000bc39c074
[ 105.249142] i40e 0000:01:00.1: i40e_ptp_stop: removed PHC on enp1s0f1
[ 105.472489] igb_uio 0000:01:00.1: mapping 1K dma=0x180187000 host=000000003182585c
[ 105.480148] igb_uio 0000:01:00.1: unmapping 1K dma=0x180187000 host=000000003182585c
[ 105.489178] i40e 0000:01:00.2: i40e_ptp_stop: removed PHC on enp1s0f2
[ 105.700497] igb_uio 0000:01:00.2: mapping 1K dma=0x12108a000 host=000000006ccf7ec6
[ 105.708160] igb_uio 0000:01:00.2: unmapping 1K dma=0x12108a000 host=000000006ccf7ec6
[ 105.717272] i40e 0000:01:00.3: i40e_ptp_stop: removed PHC on enp1s0f3
[ 105.916553] igb_uio 0000:01:00.3: mapping 1K dma=0x121132000 host=00000000a0cf9ceb
[ 105.924214] igb_uio 0000:01:00.3: unmapping 1K dma=0x121132000 host=00000000a0cf9ceb
[ 106.051801] igb_uio 0000:01:00.0: uio device registered with irq 127
[ 106.131501] igb_uio 0000:01:00.1: uio device registered with irq 128
[ 106.211155] igb_uio 0000:01:00.2: uio device registered with irq 129
[ 106.288722] igb_uio 0000:01:00.3: uio device registered with irq 130
[ 106.367089] igb_uio 0000:06:00.0: uio device registered with irq 130
[ 106.418175] igb_uio 0000:07:00.0: uio device registered with irq 131
### Note above: Gi6/0/0 and Te1/0/3 both use irq 130.
root@dcg-1:/etc/vpp# vppctl show log | grep dpdk
2021/03/28 15:57:09:184 notice dpdk EAL: Detected 6 lcore(s)
2021/03/28 15:57:09:184 notice dpdk EAL: Detected 1 NUMA nodes
2021/03/28 15:57:09:184 notice dpdk EAL: Selected IOVA mode 'PA'
2021/03/28 15:57:09:184 notice dpdk EAL: No available hugepages reported in hugepages-1048576kB
2021/03/28 15:57:09:184 notice dpdk EAL: No free hugepages reported in hugepages-1048576kB
2021/03/28 15:57:09:184 notice dpdk EAL: No available hugepages reported in hugepages-1048576kB
2021/03/28 15:57:09:184 notice dpdk EAL: Probing VFIO support...
2021/03/28 15:57:09:184 notice dpdk EAL: WARNING! Base virtual address hint (0xa80001000 != 0x7eff80000000) not respected!
2021/03/28 15:57:09:184 notice dpdk EAL: This may cause issues with mapping memory into secondary processes
2021/03/28 15:57:09:184 notice dpdk EAL: WARNING! Base virtual address hint (0xec0c61000 != 0x7efb7fe00000) not respected!
2021/03/28 15:57:09:184 notice dpdk EAL: This may cause issues with mapping memory into secondary processes
2021/03/28 15:57:09:184 notice dpdk EAL: WARNING! Base virtual address hint (0xec18c2000 != 0x7ef77fc00000) not respected!
2021/03/28 15:57:09:184 notice dpdk EAL: This may cause issues with mapping memory into secondary processes
2021/03/28 15:57:09:184 notice dpdk EAL: WARNING! Base virtual address hint (0xec2523000 != 0x7ef37fa00000) not respected!
2021/03/28 15:57:09:184 notice dpdk EAL: This may cause issues with mapping memory into secondary processes
2021/03/28 15:57:09:184 notice dpdk EAL: Invalid NUMA socket, default to 0
2021/03/28 15:57:09:184 notice dpdk EAL: Probe PCI driver: net_i40e (8086:1572) device: 0000:01:00.0 (socket 0)
2021/03/28 15:57:09:184 notice dpdk EAL: Invalid NUMA socket, default to 0
2021/03/28 15:57:09:184 notice dpdk EAL: Probe PCI driver: net_i40e (8086:1572) device: 0000:01:00.1 (socket 0)
2021/03/28 15:57:09:184 notice dpdk EAL: Invalid NUMA socket, default to 0
2021/03/28 15:57:09:184 notice dpdk EAL: Probe PCI driver: net_i40e (8086:1572) device: 0000:01:00.2 (socket 0)
2021/03/28 15:57:09:184 notice dpdk EAL: Invalid NUMA socket, default to 0
2021/03/28 15:57:09:184 notice dpdk EAL: Probe PCI driver: net_i40e (8086:1572) device: 0000:01:00.3 (socket 0)
2021/03/28 15:57:09:184 notice dpdk i40e_init_fdir_filter_list(): Failed to allocate memory for fdir filter array!
2021/03/28 15:57:09:184 notice dpdk ethdev initialisation failed
2021/03/28 15:57:09:184 notice dpdk EAL: Requested device 0000:01:00.3 cannot be used
2021/03/28 15:57:09:184 notice dpdk EAL: VFIO support not initialized
2021/03/28 15:57:09:184 notice dpdk EAL: Couldn't map new region for DMA
root@dcg-1:/etc/vpp# vppctl show pci
Address Sock VID:PID Link Speed Driver Product Name Vital Product Data
0000:01:00.0 0 8086:1572 8.0 GT/s x8 igb_uio
0000:01:00.1 0 8086:1572 8.0 GT/s x8 igb_uio
0000:01:00.2 0 8086:1572 8.0 GT/s x8 igb_uio
0000:01:00.3 0 8086:1572 8.0 GT/s x8 igb_uio
0000:06:00.0 0 8086:1533 2.5 GT/s x1 igb_uio
0000:07:00.0 0 8086:1533 2.5 GT/s x1 igb_uio
root@dcg-1:/etc/vpp# ip ro
94.142.242.96/27 dev bond0.205 proto kernel scope link src 94.142.242.98
94.142.242.128/28 dev bond0.202 proto kernel scope link src 94.142.242.140
94.142.244.0/24 dev bond0.100 proto kernel scope link src 94.142.244.252
94.142.246.0/24 dev bond0.201 proto kernel scope link src 94.142.246.252
94.142.247.40/29 dev bond0.102 proto kernel scope link src 94.142.247.44
94.142.247.80/29 dev bond0.2481 proto kernel scope link src 94.142.247.82
94.142.247.224/31 dev eno1 proto kernel scope link src 94.142.247.224
94.142.247.236/31 dev bond0.120 proto kernel scope link src 94.142.247.236
172.28.0.0/24 dev bond0.101 proto kernel scope link src 172.28.0.252
185.52.224.80/28 dev bond0.206 proto kernel scope link src 185.52.224.92
193.239.116.0/22 dev enp1s0f2.7 proto kernel scope link src 193.239.117.111
213.207.10.0/26 dev enp1s0f2.26 proto kernel scope link src 213.207.10.53
root@dcg-1:/etc/vpp# birdc6 show ospf neighbors
BIRD 1.6.6 ready.
ospf1:
Router ID Pri State DTime Interface Router IP
94.142.247.2 1 Full/PtP 00:35 eno1 fe80::ae1f:6bff:feeb:858c
94.142.247.7 128 Full/PtP 00:35 bond0.120 fe80::9ecc:8300:78b2:8b62
root@dcg-1:/etc/vpp# birdc show ospf neighbors
BIRD 1.6.6 ready.
ospf1:
Router ID Pri State DTime Interface Router IP
94.142.247.2 1 Exchange/PtP 00:37 eno1 94.142.247.225
94.142.247.7 128 Exchange/PtP 00:39 bond0.120 94.142.247.237
root@dcg-1:/etc/vpp# vppctl show bond details
BondEthernet0
mode: lacp
load balance: l2
number of active members: 2
TenGigabitEthernet1/0/0
TenGigabitEthernet1/0/1
number of members: 2
TenGigabitEthernet1/0/0
TenGigabitEthernet1/0/1
device instance: 0
interface id: 0
sw_if_index: 6
hw_if_index: 6
root@dcg-1:/etc/vpp# ping 193.239.116.1
PING 193.239.116.1 (193.239.116.1) 56(84) bytes of data.
64 bytes from 193.239.116.1: icmp_seq=1 ttl=64 time=2.24 ms
64 bytes from 193.239.116.1: icmp_seq=2 ttl=64 time=0.571 ms
64 bytes from 193.239.116.1: icmp_seq=3 ttl=64 time=0.625 ms
^C
--- 193.239.116.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 5ms
rtt min/avg/max/mdev = 0.571/1.146/2.244/0.777 ms
root@dcg-1:/etc/vpp# ping 94.142.244.85
PING 94.142.244.85 (94.142.244.85) 56(84) bytes of data.
64 bytes from 94.142.244.85: icmp_seq=1 ttl=64 time=0.226 ms
64 bytes from 94.142.244.85: icmp_seq=2 ttl=64 time=0.207 ms
64 bytes from 94.142.244.85: icmp_seq=3 ttl=64 time=0.200 ms
64 bytes from 94.142.244.85: icmp_seq=4 ttl=64 time=0.204 ms
^C
--- 94.142.244.85 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 66ms
rtt min/avg/max/mdev = 0.200/0.209/0.226/0.014 ms
Cleaning up
apt purge dpdk* vpp*
apt autoremove
rm -rf /etc/vpp
rm /etc/sysctl.d/*vpp*.conf
cp /etc/network/interfaces.2021-03-28 /etc/network/interfaces
cp /root/.ssh/authorized_keys.2021-03-28 /root/.ssh/authorized_keys
systemctl enable bird
systemctl enable bird6
systemctl enable keepalived
reboot
Next steps
Taking another look at IOMMU and PT redhat thread and in particular the part about allow_unsafe_interrupts in the kernel module. Find some ways to get the NICs (1x Intel x710 and 2x Intel i210) to detect in VPP. By then, probably the Linux CP (Interface mirroring and Netlink listener) will be submitted.