FiberStore is a staple provider of optics and network gear in Europe. Although I’ve been buying opfics like SFP+ and QSFP+ from them for years, I rarely looked at the switch hardware they have on sale, until my buddy Arend suggested one of their switches as a good alternative for an Internet Exchange Point, one with Frysian roots no less!
Executive Summary

The FS.com S5860 switch is pretty great: 20x 10G SFP+ ports, 4x 25G SPF28 ports and 2x 40G QSFP ports, which can also be reconfigued to be 4x10G each. The switch has a Cisco-like CLI, and great performance. I loadtested a pair of them in L2, QinQ, and in L3 mode, and they handled all the packets I sent to and through them, with all of 10G, 25G and 40G ports in use. Considering the redundant power supply with relatively low power usage, silicon based switching of L2 and L3, I definitely appreciate the price/performance. The switch would be a better match if it allowed for MPLS based L2VPN services, but it doesn’t support that.
Detailed findings
Hardware

The switch is based on Broadcom’s BCM56170, codename Hurricane with 28x10GbE + 4x25GbE ports internally, for a total switching bandwidth of 380Gbps. I noticed that the FS website shows 760Gbps of nonblocking capacity, which I can explain: Broadcom has taken the per port ingress capacity, while FS.com is taking the ingress/egress port capacity and summing them up. Further, the sales pitch claims 565Mpps which I found curious: if we divide the available bandwidth of 380Gbps (the number from the Broadcom dataspec) by smallest possible frame of 84 bytes (672 bits), we’ll see 565Mpps. Why FS.com decided to seemingly arbitrarily double the switching capacity while reporting the nominal fowarding rate, is beyond me.
You can see more (hires) pictures in this Photo Album.
This Broadcom chip is an SOC (System-on-a-Chip) which comes with an Arm A9 and modest amount of TCAM on board and packs into a 31x31mm ball grid array formfactor. The switch chip is able to store 16k routes and ACLs - it did not become immediately obvious to me what the partitioning is (between IPv4 entries, IPv6 entries, L2/L3/L4 ACL entries). One can only assume that the total sum of TCAM based objects must not exceed 4K entries. This means that as a campus switch, the L3 functionalty will be great, including with routing protocols such as OSPF and ISIS. However, BGP with any amount of routing table activity will not be a good fit for this chip, so my dreams of porting DANOS to it are shot out of the box :-)
This Broadcom chip alone retails for €798,- apiece at Digikey, with a manufacturer lead time of 50 weeks as of Aug'21, which may be related to the ongoing foundry and supply chain crisis, I don’t know. But at that price point, the retail price of €1150,- per switch is really attractive.
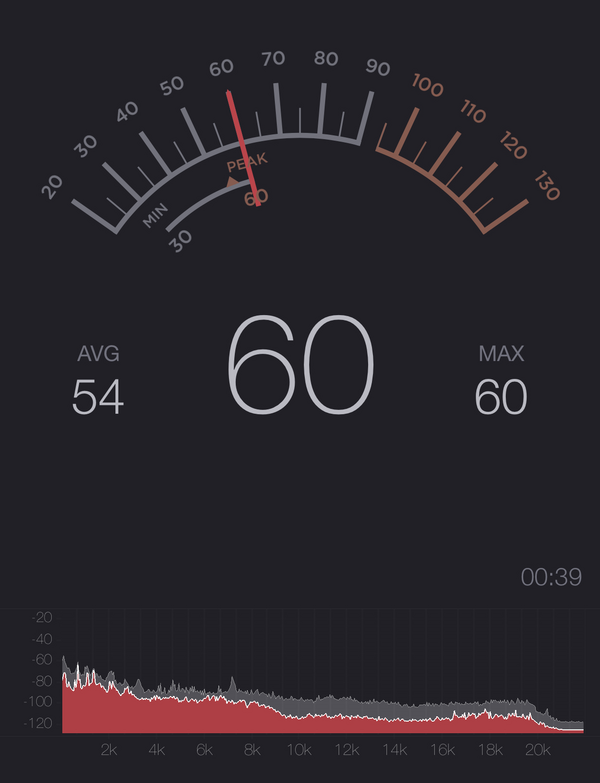
The switch comes with two modular and field-replaceble power supplies (rated at 150W each, delivering 12V at 12.5A, one fan installed), and with two modular and equally field replaceble fan trays installed with one fan each. Idle, without any optics installed and with all interfaces down, the switch draws about 18W of power, which is nice. The fans spin up only when needed, and by default the switch is quiet, but certainly not silent. I measured it after a tip from Michael, certainly nothing scientific, but in a silent room that measures a floor of ~30 dBA, the switch booted up and briefly burst the fans at 60dBA after which it stabilized at 54dBA or thereabouts. This is with both power supplies on, and with my cell phone microphone pointed directly towards the rear of the device, at 1 meter distance. Or something, IDK, I’m a network engineer, Jim, not an audio specialist!
Besides the 20x 1G/10G SFP+ ports, 4x 25G ports and 2x 40G ports (which, incidentally, can be
broken out into 4x 10G as well, bringing the Tengig port count to the datasheet specified 28),
the switch also comes with a USB port (which mounts a filesystem on a USB stick, handy to do
firmware upgrades and to copy files such as SSH keys back and forth), an RJ45 1G management
port, which does not participate in the switch at all, and an RJ45 serial port that uses a
standard Cisco cable for access and presents itself as 9600,8n1 to a console server, although
flow control must be disabled on the serial port.
Transceiver Compatibility
FS did not attempt any vendor locking or crippleware with the ports and optics, yaay for that. I successfully inserted Cisco optics, Arista optics, FS.com ‘Generic’ optics, and several DACs for 10G, 25G and 40G that I had lying around. The switch is happy to take all of them. The switch, as one would expect, supports diagnostics, which looks like this:
fsw0#show interfaces TFGigabitEthernet0/24 transceiver
Transceiver Type : 25GBASE-LR-SFP28
Connector Type : LC
Wavelength(nm) : 1310
Transfer Distance :
SMF fiber
-- 10km
Digital Diagnostic Monitoring : YES
Vendor Serial Number : G2006362849
Current diagnostic parameters[AP:Average Power]:
Temp(Celsius) Voltage(V) Bias(mA) RX power(dBm) TX power(dBm)
33(OK) 3.29(OK) 38.31(OK) -0.10(OK)[AP] -0.07(OK)
Transceiver current alarm information:
None
.. with a helpful shorthand show interfaces ... trans diag that only shows the optical budget.
Software
I bought a pair of switches, and they came delivered with a current firmware version. The devices
idenfity themselves as FS Campus Switch (S5860-20SQ) By FS.COM Inc with a hardware version of 1.00
and a software version of S5860_FSOS 12.4(1)B0101P1. Firmware updates can be downloaded from the
FS.com website directly. I’m not certain if there’s a viable ONIE firmware for this chip, although the
N8050 certainly can run ONIE, Cumulus and its own ICOS which is backed by Broadcom. Maybe
in the future I could take a better look at the open networking firmware aspects of this type of
hardware, but considering the CAM is tiny and the switch will do L2 in hardware, but L3 only up to
a certain amount of routes (I think 4K or 16K in the FIB, and only 1GB of ram on the SOC), this is
not the right platform to pour energy into trying to get DANOS to run on.
Taking a look at the CLI, it’s very Cisco IOS-esque; there’s a few small differences, but the look and feel is definitely familiar. Base configuration kind of looks like this:
fsw0#show running-config
hostname fsw0
!
sntp server oob 216.239.35.12
sntp enable
!
username pim privilege 15 secret 5 $1$<redacted>
!
ip name-server oob 8.8.8.8
!
service password-encryption
!
enable service ssh-server
no enable service telnet-server
!
interface Mgmt 0
ip address 192.168.1.10 255.255.255.0
gateway 192.168.1.1
!
snmp-server location Zurich, Switzerland
snmp-server contact noc@ipng.ch
snmp-server community 7 <redacted> ro
!
Configuration as well follows the familiar conf t (configure terminal) that many of us grew up
with, and show command allow for include and exclude modifiers, of course with all the
shortest-next abbriviations such as sh int | i Forty and the likes. VLANs are to be declared
up front, with one notable cool feature of supervlans, which are the equivalent of aggregating
VLANs together in the switch - a useful example might be an internet exchange platform which has
trunk ports towards resellers, who might resell VLAN 101, 102, 103 each to an individual customer,
but then all end up in the same peering lan VLAN 100.
A few of the services (SSH, SNMP, DNS, SNTP) can be bound to the management network, but for this
to work, the oob keyword has to be used. This likely because the mgmt port is a network interface
that is attached to the SOC, not to the switch fabric itself, and thus its route is not added to
the routing table. I like this, because it avoids the mgmt network to be picked up in OSPF, and
accidentally routed to/from. But it does show a bit more of an awkward config:
fsw1#show running-config | inc oob
sntp server oob 216.239.35.12
ip name-server oob 8.8.8.8
ip name-server oob 1.1.1.1
ip name-server oob 9.9.9.9
fsw1#copy ?
WORD Copy origin file from native
flash: Copy origin file from flash: file system
ftp: Copy origin file from ftp: file system
http: Copy origin file from http: file system
oob_ftp: Copy origin file from oob_ftp: file system
oob_http: Copy origin file from oob_http: file system
oob_tftp: Copy origin file from oob_tftp: file system
running-config Copy origin file from running config
startup-config Copy origin file from startup config
tftp: Copy origin file from tftp: file system
tmp: Copy origin file from tmp: file system
usb0: Copy origin file from usb0: file system
Note here the hack oob_ftp: and such; this would allow the switch to copy things from the
OOB (management) network by overriding the scheme. But that’s OK, I guess, not beautiful,
but it gets the job done and these types of commands will rarely be used.
A few configuration examples, notably QinQ, in which I configure a port to take usual dot1q traffic, say from a customer, and add it into our local VLAN 200. Therefore, untagged traffic on that port will turn into our VLAN 200, and tagged traffic will turn into our dot1ad stack of outer VLAN 200 and inner VLAN whatever the customer provided – in our case allowing only VLANs 1000-2000 and untagged traffic into VLAN 200:
fsw0#confifgure
fsw0(config)#vlan 200
fsw0(config-vlan)#name v-qinq-outer
fsw0(config-vlan)#exit
fsw0(config)#interface TenGigabitEthernet 0/3
fsw0(config-if-TenGigabitEthernet 0/3)#switchport mode dot1q-tunnel
fsw0(config-if-TenGigabitEthernet 0/3)#switchport dot1q-tunnel native vlan 200
fsw0(config-if-TenGigabitEthernet 0/3)#switchport dot1q-tunnel allowed vlan add untagged 200
fsw0(config-if-TenGigabitEthernet 0/3)#switchport dot1q-tunnel allowed vlan add tagged 1000-2000
The industry remains conflicted about the outer ethernet frame’s type – originally a tag
protocol identifier (TPID) of 0x9100 was suggested, and that’s what this switch uses. But
the first specification of Q-in-Q called 802.1ad specified that the TPID should be 0x88a8
instead of the VLAN tag that was 0x8100. This ugly reality can be reflected directly in the
switchport configuration by adding a frame-tag tpid 0xXXXX value to let the switch know
which TPID needs to be used for the outer tag.
If this type of historical thing interests you, I definitely recommend reading up on Wikipedia on 802.1q and 802.1ad as well.
Loadtests
For my loadtests, I used Cisco’s T-Rex (ref) in stateless mode,
with a custom Python controller that ramps up and down traffic from the loadtester to the device
under test (DUT) by sending traffic out port0 to the DUT, and expecting that traffic to be
presented back out from the DUT to its port1, and vice versa (out from port1 -> DUT -> back
in on port0). You can read a bit more about my setup in my Loadtesting at Coloclue
post.
To stress test the switch, several pairs at 10G and 25G were used, and since the specs boast line rate forwarding, I immediately ran T-Rex at maximum load with small frames. I found out, once again, that Intel’s X710 network cards aren’t line rate, something I’ll dive into in a bit more detail another day, for now, take a look at the T-Rex docs.
L2
First let’s test a straight forward configuration. I connect a DAC between a 40G port on each
switch, and connect a loadtester to port TenGigabitEthernet 0/1 and TenGigabitEthernet 0/2
on either switch, and leave everything simply in the default VLAN. This means packets from
Te0/1 and Te0/2 go out on Fo0/26, then through the DAC into Fo0/26 on the second switch, and
out on Te0/1 and Te0/2 there, to return to the loadtester. Configuration wise, rather boring:
fsw0#configure
fsw0(config)#vlan 1
fsw0(config-vlan)#name v-default
fsw0#show run int te0/1
interface TenGigabitEthernet 0/1
fsw0#show run int te0/2
interface TenGigabitEthernet 0/2
fsw0#show run int fo0/26
interface FortyGigabitEthernet 0/26
switchport mode trunk
switchport trunk allowed vlan only 1
fsw0#show vlan id 1
VLAN Name Status Ports
---------- -------------------------------- --------- -----------------------------------
1 v-default STATIC Te0/1, Te0/2, Te0/3, Te0/4
Te0/5, Te0/6, Te0/7, Te0/8
Te0/9, Te0/10, Te0/11, Te0/12
Te0/13, Te0/14, Te0/15, Te0/16
Te0/17, Te0/18, Te0/19, Te0/20
TF0/21, TF0/22, TF0/23, Fo0/25
Fo0/26
I set up T-Rex with unique MAC addresses for each of its ports, I find it useful to codify a few bits of information into the MAC, such as loadtester machine, PCI bus, port, so that when I try to find them on the switches in the forwarding table, and I have many loadtesters running at the same time, it’s easier to find what I’m looking for. My trex configuration for this loadtest:
pim@hippo:~$ cat /etc/trex_cfg.yaml
- version : 2
interfaces : ["42:00.0","42:00.1", "42:00.2", "42:00.3"]
port_limit : 4
port_info :
- dest_mac : [0x0,0x2,0x1,0x1,0x0,0x00] # port 0
src_mac : [0x0,0x2,0x1,0x2,0x0,0x00]
- dest_mac : [0x0,0x2,0x1,0x2,0x0,0x00] # port 1
src_mac : [0x0,0x2,0x1,0x1,0x0,0x00]
- dest_mac : [0x0,0x2,0x1,0x3,0x0,0x00] # port 2
src_mac : [0x0,0x2,0x1,0x4,0x0,0x00]
- dest_mac : [0x0,0x2,0x1,0x4,0x0,0x00] # port 3
src_mac : [0x0,0x2,0x1,0x3,0x0,0x00]
Here’s where I notice something I’ve noticed before: the Intel X710 network cards cannot actually fill 4x10G at line rate. They’re fine at larger frames, but they max out at about 32Mpps throughput – and we know that each 10G connection filled with small ethernet frames in one direction will consume 14.88Mpps. The same is true for the XXV710 cards, the chip used will really only source 30Mpps across all ports, which is sad but true.
So I have a choice to make: either I run small packets at a rate that’s acceptable for the
NIC (~7.5Mpps per port thus 30Mpps across the X710-DA4), or I run imix at line rate
but with slightly less packets/sec. I chose the latter for these tests, and will be reporting
the usage based on imix profile, which saturates 10G at 3.28Mpps in one direction, or
13.12Mpps per network card.
Of course, I can run two of these at the same time, pourquois pas, which looks like this:
fsw0#show mac
Vlan MAC Address Type Interface Live Time
---------- -------------------- -------- ------------------------------ -------------
1 0001.0101.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:16:11
1 0001.0102.0000 DYNAMIC TenGigabitEthernet 0/1 0d 00:16:11
1 0001.0103.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:16:11
1 0001.0104.0000 DYNAMIC TenGigabitEthernet 0/2 0d 00:16:10
1 0002.0101.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:15:51
1 0002.0102.0000 DYNAMIC TenGigabitEthernet 0/3 0d 00:15:51
1 0002.0103.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:15:51
1 0002.0104.0000 DYNAMIC TenGigabitEthernet 0/4 0d 00:15:50
fsw0#show int usage | exclude 0.00
Interface Bandwidth Average Usage Output Usage Input Usage
------------------------------------ ----------- ---------------- ---------------- ----------------
TenGigabitEthernet 0/1 10000 Mbit 94.66% 94.66% 94.66%
TenGigabitEthernet 0/2 10000 Mbit 94.66% 94.66% 94.66%
TenGigabitEthernet 0/3 10000 Mbit 94.65% 94.66% 94.66%
TenGigabitEthernet 0/4 10000 Mbit 94.66% 94.66% 94.66%
FortyGigabitEthernet 0/26 40000 Mbit 94.66% 94.66% 94.66%
fsw0#show cpu core
[Slot 0 : S5860-20SQ]
Core 5Sec 1Min 5Min
0 16.40% 12.00% 12.80%
This is the first time that I noticed that the switch usage (94.66%) somewhat confusingly lines up with the observed T-Rex statistics: what the switch reports, T-Rex considers L2 (ethernet) use, not L1 use. For an in-depth explanation of this, see below in the L3 section. But for now, let’s just say that when T-Rex says it’s sending 37.9Gbps of ethernet traffic (which is 40.00Gbps of bits on the line), that corresponds to the 94.75% we see the switch reporting.
So suffice to say, at 80Gbit actual throughput (40G from Te0/1-3 ingress and 40G to Te0/1-3 egress), the switch performs at line rate, with no noticable lag or jitter. The CLI is responsive and the fans aren’t spinning harder than at idle, even after 60min of packets. Good!
QinQ
Then, I reconfigured the switch to let each pair of ports (Te0/1-2 and Te0/3-4) each drop into a Q-in-Q VLAN, with tag 20 and tag 21 respectively. The configuration:
interface TenGigabitEthernet 0/1
switchport mode dot1q-tunnel
switchport dot1q-tunnel allowed vlan add untagged 20
switchport dot1q-tunnel native vlan 20
!
interface TenGigabitEthernet 0/3
switchport mode dot1q-tunnel
switchport dot1q-tunnel allowed vlan add untagged 21
switchport dot1q-tunnel native vlan 21
spanning-tree bpdufilter enable
!
interface FortyGigabitEthernet 0/26
switchport mode trunk
switchport trunk allowed vlan only 1,20-21
fsw0#show mac
Vlan MAC Address Type Interface Live Time
---------- -------------------- -------- ------------------------------ -------------
20 0001.0101.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 01:15:02
20 0001.0102.0000 DYNAMIC TenGigabitEthernet 0/1 0d 01:15:01
20 0001.0103.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 01:15:02
20 0001.0104.0000 DYNAMIC TenGigabitEthernet 0/2 0d 01:15:03
21 0002.0101.0000 DYNAMIC TenGigabitEthernet 0/4 0d 00:01:50
21 0002.0102.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:01:03
21 0002.0103.0000 DYNAMIC TenGigabitEthernet 0/3 0d 00:01:59
21 0002.0104.0000 DYNAMIC FortyGigabitEthernet 0/26 0d 00:01:02
Two things happen that require a bit of explanation. First of all, despite both loadtesters use the exact same configuration (in fact, I didn’t even stop them from emitting packets while reconfiguring the switch), I now have packetloss, the throughput per 10G port has reduced from 94.67% to 93.63% and at the same time, I observe that the 40G ports raised their usage from 94.66% to 94.81%.
fsw1#show int usage | e 0.00
Interface Bandwidth Average Usage Output Usage Input Usage
------------------------------------ ----------- ---------------- ---------------- ----------------
TenGigabitEthernet 0/1 10000 Mbit 94.20% 93.63% 94.67%
TenGigabitEthernet 0/2 10000 Mbit 94.21% 93.65% 94.67%
TenGigabitEthernet 0/3 10000 Mbit 91.05% 94.66% 94.66%
TenGigabitEthernet 0/4 10000 Mbit 90.80% 94.66% 94.66%
FortyGigabitEthernet 0/26 40000 Mbit 94.81% 94.81% 94.81%
The switches, however, are perfectly fine. The reason for this loss is that when I created
the dot1q-tunnel, the switch sticks another VLAN tag (4 bytes, or 32 bits) on each packet
before sending it out the 40G port between the switches, and at these packet rates, it adds
up. Each 10G switchport is receiving 3.28Mpps (for a total of 13.12Mpps) which, when the
switch needs to send it to its peer on the 40G trunk, adds 13.12Mpps * 32 bits = 419.8Mbps
on top of the 40G line rate, implying we’re going to be losing roughly 1.045% of our packets.
And indeed, the difference between 94.67 (inbound) and 93.63 (outbound) is 1.04% which lines
up.
Global Statistics
connection : localhost, Port 4501 total_tx_L2 : 37.92 Gbps
version : STL @ v2.91 total_tx_L1 : 40.02 Gbps
cpu_util. : 43.52% @ 8 cores (4 per dual port) total_rx : 37.92 Gbps
rx_cpu_util. : 0.0% / 0 pps total_pps : 13.12 Mpps
async_util. : 0% / 198.64 bps drop_rate : 0 bps
total_cps. : 0 cps queue_full : 0 pkts
Port Statistics
port | 0 | 1 | 2 | 3
-----------+-------------------+-------------------+-------------------+------------------
owner | pim | pim | pim | pim
link | UP | UP | UP | UP
state | TRANSMITTING | TRANSMITTING | TRANSMITTING | TRANSMITTING
speed | 10 Gb/s | 10 Gb/s | 10 Gb/s | 10 Gb/s
CPU util. | 46.29% | 46.29% | 40.76% | 40.76%
-- | | | |
Tx bps L2 | 9.48 Gbps | 9.48 Gbps | 9.48 Gbps | 9.48 Gbps
Tx bps L1 | 10 Gbps | 10 Gbps | 10 Gbps | 10 Gbps
Tx pps | 3.28 Mpps | 3.27 Mpps | 3.27 Mpps | 3.28 Mpps
Line Util. | 100.04 % | 100.04 % | 100.04 % | 100.04 %
--- | | | |
Rx bps | 9.48 Gbps | 9.48 Gbps | 9.48 Gbps | 9.48 Gbps
Rx pps | 3.24 Mpps | 3.24 Mpps | 3.23 Mpps | 3.24 Mpps
---- | | | |
opackets | 1891576526 | 1891577716 | 1891547042 | 1891548090
ipackets | 1891576643 | 1891577837 | 1891547158 | 1891548214
obytes | 684435443496 | 684435873418 | 684424773684 | 684425153614
ibytes | 684435484082 | 684435916902 | 684424817178 | 684425197948
tx-pkts | 1.89 Gpkts | 1.89 Gpkts | 1.89 Gpkts | 1.89 Gpkts
rx-pkts | 1.89 Gpkts | 1.89 Gpkts | 1.89 Gpkts | 1.89 Gpkts
tx-bytes | 684.44 GB | 684.44 GB | 684.42 GB | 684.43 GB
rx-bytes | 684.44 GB | 684.44 GB | 684.42 GB | 684.43 GB
----- | | | |
oerrors | 0 | 0 | 0 | 0
ierrors | 0 | 0 | 0 | 0
L3
For this test, I reconfigured the 25G ports to become routed rather than switched, and I put them under 80% load with T-Rex (where 80% here is of L1), thus the ports are emitting 20Gbps of traffic at a rate of 13.12Mpps. I left two of the 10G ports just continuing their ethernet loadtest at 100%, which is also 20Gbps of traffic and 13.12Mpps. In total, I observed 79.95Gbps of traffic between the two switches: an entirely saturated 40G port in both directions.
I then created a simple topology with OSPF, both switches configured a Loopback0 interface with
a /32 IPv4 and /128 IPv6 address, and a transit network between them in a VLAN100 interface.
OSPF and OSPFv3 both distribute connected and static routes, to keep things simple.
Finally, I added an IP address on the Tf0/24 interface, set a static IPv4 route for 16.0.0.0/8
and 48.0.0.0/8 towards that interface on each switch, and added VLAN 100 to the Fo0/26 trunk.
It looks like this for switch fsw0:
interface Loopback 0
ip address 100.64.0.0 255.255.255.255
ipv6 address 2001:DB8::/128
ipv6 enable
interface VLAN 100
ip address 100.65.2.1 255.255.255.252
ipv6 enable
ip ospf network point-to-point
ipv6 ospf network point-to-point
ipv6 ospf 1 area 0
interface TFGigabitEthernet 0/24
no switchport
ip address 100.65.1.1 255.255.255.0
ipv6 address 2001:DB8:1:1::1/64
interface FortyGigabitEthernet 0/26
switchport mode trunk
switchport trunk allowed vlan only 1,20,21,100
router ospf 1
graceful-restart
redistribute connected subnets
redistribute static subnets
area 0
network 100.65.2.0 0.0.0.3 area 0
!
ipv6 router ospf 1
graceful-restart
redistribute connected
redistribute static
area 0
!
ip route 16.0.0.0 255.0.0.0 100.65.1.2
ipv6 route 2001:db8:100::/40 2001:db8:1:1::2
With this topology, an L3 routing domain emerges between Tf0/24 on switch fsw0 and Tf0/24
on switch fsw1, and we can inspect this, taking a look at fsw1, I can see that both IPv4 and
IPv6 adjacencies have formed, and that the switches, néé routers, have learned
routes from one another:
fsw1#show ip ospf neighbor
OSPF process 1, 1 Neighbors, 1 is Full:
Neighbor ID Pri State BFD State Dead Time Address Interface
100.65.2.1 1 Full/ - - 00:00:31 100.65.2.1 VLAN 100
fsw1#show ipv6 ospf neighbor
OSPFv3 Process (1), 1 Neighbors, 1 is Full:
Neighbor ID Pri State BFD State Dead Time Instance ID Interface
100.65.2.1 1 Full/ - - 00:00:31 0 VLAN 100
fsw1#show ip route
Codes: C - Connected, L - Local, S - Static
R - RIP, O - OSPF, B - BGP, I - IS-IS, V - Overflow route
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
SU - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
IA - Inter area, EV - BGP EVPN, A - Arp to host
* - candidate default
Gateway of last resort is no set
O E2 16.0.0.0/8 [110/20] via 100.65.2.1, 12:42:13, VLAN 100
S 48.0.0.0/8 [1/0] via 100.65.0.2
O E2 100.64.0.0/32 [110/20] via 100.65.2.1, 00:05:23, VLAN 100
C 100.64.0.1/32 is local host.
C 100.65.0.0/24 is directly connected, TFGigabitEthernet 0/24
C 100.65.0.1/32 is local host.
O E2 100.65.1.0/24 [110/20] via 100.65.2.1, 12:44:57, VLAN 100
C 100.65.2.0/30 is directly connected, VLAN 100
C 100.65.2.2/32 is local host.
fsw1#show ipv6 route
IPv6 routing table name - Default - 12 entries
Codes: C - Connected, L - Local, S - Static
R - RIP, O - OSPF, B - BGP, I - IS-IS, V - Overflow route
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
SU - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
IA - Inter area, EV - BGP EVPN, N - Nd to host
O E2 2001:DB8::/128 [110/20] via FE80::669D:99FF:FED0:A054, VLAN 100
LC 2001:DB8::1/128 via Loopback 0, local host
C 2001:DB8:1::/64 via TFGigabitEthernet 0/24, directly connected
L 2001:DB8:1::1/128 via TFGigabitEthernet 0/24, local host
O E2 2001:DB8:1:1::/64 [110/20] via FE80::669D:99FF:FED0:A054, VLAN 100
O E2 2001:DB8:100::/40 [110/20] via FE80::669D:99FF:FED0:A054, VLAN 100
C FE80::/10 via ::1, Null0
C FE80::/64 via Loopback 0, directly connected
L FE80::669D:99FF:FED0:A076/128 via Loopback 0, local host
C FE80::/64 via TFGigabitEthernet 0/24, directly connected
L FE80::669D:99FF:FED0:A076/128 via TFGigabitEthernet 0/24, local host
C FE80::/64 via VLAN 100, directly connected
L FE80::669D:99FF:FED0:A076/128 via VLAN 100, local host
Great success! I can see from the fsw1 output above, its OSPF process has learned
routes for the IPv4 and IPv6 loopbacks (100.64.0.0/32 and 2001:DB8::1/128 respectively),
the connected routes (100.65.1.0/24 and 2001:DB8:1:1::/64 respectively), and the
static routes (16.0.0.0/8 and 2001:db8:100::/40).
So let’s make use of this topology and change one of the two loadtesters to switch to L3 mode instead:
pim@hippo:~$ cat /etc/trex_cfg.yaml
- version : 2
interfaces : ["0e:00.0", "0e:00.1" ]
port_bandwidth_gb: 25
port_limit : 2
port_info :
- ip : 100.65.0.2
default_gw : 100.65.0.1
- ip : 100.65.1.2
default_gw : 100.65.1.1
I left the loadtest running for 12hrs or so, and observed the results to be squeaky clean. The loadtester machine was generating ~96Gb/core at 20% utilization, so lazily generating 40.00Gbit of traffic at 25.98Mpps (remember, this was setting the load to 80% on the 25G port, and 99% on the 10G ports). Looking at the switch and again being surprised about the discrepancy, I decided to fully explore the curiosity in this switch’s utilization reporting.
fsw1#show interfaces usage | exclude 0.00
Interface Bandwidth Average Usage Output Usage Input Usage
------------------------------------ ----------- -------------- -------------- -----------
TenGigabitEthernet 0/1 10000 Mbit 93.80% 93.79% 93.81%
TenGigabitEthernet 0/2 10000 Mbit 93.80% 93.79% 93.81%
TFGigabitEthernet 0/24 25000 Mbit 75.80% 75.79% 75.81%
FortyGigabitEthernet 0/26 40000 Mbit 94.79% 94.79% 94.79%
fsw1#show int te0/1 | inc packets/sec
10 seconds input rate 9381044793 bits/sec, 3240802 packets/sec
10 seconds output rate 9378930906 bits/sec, 3240123 packets/sec
fsw1#show int tf0/24 | inc packets/sec
10 seconds input rate 18952369793 bits/sec, 6547299 packets/sec
10 seconds output rate 18948317049 bits/sec, 6545915 packets/sec
fsw1#show int fo0/26 | inc packets/sec
10 seconds input rate 37915517884 bits/sec, 13032078 packets/sec
10 seconds output rate 37915335102 bits/sec, 13026051 packets/sec
Looking at that number, 75.80% was not the 80% that I had asked for, and actually the usage of the 10G ports (which I put at 99% load) and 40G port are also lower than I had anticipated. What’s going on there? It’s quite simple after doing some math: the switch is reporting L2 bits/sec, not L1 bits/sec!
On the L3 loadtest and using the imix profile, T-Rex is sending 13.02Mpps of load, which,
according to its own observation is 37.8Gbit of L2 and 40.00Gbps of L1 bandwidth. On the L2
loadtest, again using imix profile, T-Rex is sending 4x 3.24Mpps as well, which it claims
is 37.6Gbps of L2 and 39.66Gbps of L1 bandwidth (note: I put the loadtester here at 99% of
line rate, this is to ensure I would not end up losing packets due to congestion on the 40G
port).
So according to T-Rex, I am sending 75.4Gbps of traffic (37.8Gbps in the L2 test and 37.6Gbps in the simultenous L3 loadtest), yet I’m seeing 37.9Gbps on the switchport. Oh my!
Here’s how all of these numbers relate to one another:
- First off, we are sending 99% linerate at 3.24Mpps into Te0/1 and Te0/2 on each switch.
- Then, we are sending 80% linerate at 6.55Mpps into Tf0/24 on each switch.
- The Te0/1 and Te0/2 are both in the default VLAN on either side.
- But, the Tf0/24 is sending its IP traffic through VLAN 100 interconnect, which means all of that traffic gets a dot1q VLAN tag added. That’s 4 bytes for each packet.
- Sending 6.55Mpps * 32bits extra, equals 209600000 bits/sec (0.21Gbps)
- Loadtester claims 37.70Gbps, but the switch sees 37.91Gbps which is exactly the difference we calculated above (0.21Gbps), and equals the overhead created by adding the VLAN tag on the 25G stream that is in VLAN tag 100.
Now we are ready to explain the difference between the switch reported port usage and the loadtester reported port usage:
- The loadtester is sending an
imixtraffic mix, which consts of a ratio of 28:16:4 of packets that are 64:590:1514 bytes. - We already know that to create a packet on the wire, we have to add a 7 byte preamble a 1 byte start frame delimiter, and end with a 12 byte interpacket gap, so each ethernet frame is 20 bytes longer, making 84 bytes the on-the-wire smallest possible frame.
- We know we’re sending 3.24Mpps on a 10G port at 99% T-Rex (L1) usage:
- Each packet needs 20 bytes or 160 bits of overhead, which is 518400000 bits/sec
- We are seeing 9381044793 bits/sec on a 10G port (corresponding switch 93.80% usage)
- Adding these two numbers up gives us 9899444793 bits/sec (corresponding T-Rex 98.99% usage)
- Conversely, the whole system is sending 37.9Gbps on the 40G port (corresponding switch 37.9/40 == 94.79% usage)
- We know this is 2x 10G streams at 99% utilization and 1x25G stream at 80% utilization
- This is 13.03Mpps, which generate 2084800000 bits/sec of overhead
- Adding these two numbers up gives us 40.00 Gbps of usage (which is the expected L1 line rate)
I find it very fulfilling to see these numbers meaningfully add up! Oh, and by the way, the switches that are now switching and routing all of this with with 0.00% packet loss, and the chassis doesn’t even get warm :-)
Global Statistics
connection : localhost, Port 4501 total_tx_L2 : 38.02 Gbps
version : STL @ v2.91 total_tx_L1 : 40.02 Gbps
cpu_util. : 21.88% @ 4 cores (4 per dual port) total_rx : 38.02 Gbps
rx_cpu_util. : 0.0% / 0 pps total_pps : 13.13 Mpps
async_util. : 0% / 39.16 bps drop_rate : 0 bps
total_cps. : 0 cps queue_full : 0 pkts
Port Statistics
port | 0 | 1 | total
-----------+-------------------+-------------------+------------------
owner | pim | pim |
link | UP | UP |
state | TRANSMITTING | TRANSMITTING |
speed | 25 Gb/s | 25 Gb/s |
CPU util. | 21.88% | 21.88% |
-- | | |
Tx bps L2 | 19.01 Gbps | 19.01 Gbps | 38.02 Gbps
Tx bps L1 | 20.06 Gbps | 20.06 Gbps | 40.12 Gbps
Tx pps | 6.57 Mpps | 6.57 Mpps | 13.13 Mpps
Line Util. | 80.23 % | 80.23 % |
--- | | |
Rx bps | 19 Gbps | 19 Gbps | 38.01 Gbps
Rx pps | 6.56 Mpps | 6.56 Mpps | 13.13 Mpps
---- | | |
opackets | 292215661081 | 292215652102 | 584431313183
ipackets | 292152912155 | 292153677482 | 584306589637
obytes | 105733412810506 | 105733412001676 | 211466824812182
ibytes | 105710857873526 | 105711223651650 | 211422081525176
tx-pkts | 292.22 Gpkts | 292.22 Gpkts | 584.43 Gpkts
rx-pkts | 292.15 Gpkts | 292.15 Gpkts | 584.31 Gpkts
tx-bytes | 105.73 TB | 105.73 TB | 211.47 TB
rx-bytes | 105.71 TB | 105.71 TB | 211.42 TB
----- | | |
oerrors | 0 | 0 | 0
ierrors | 0 | 0 | 0
Conclusions
It’s just super cool to see a switch like this work as expected. I did not manage to overload it at all, neither with IPv4 loadtest at 20Mpps and 50Gbit of traffic, nor with L2 loadtest at 26Mpps and 80Gbit of traffic, with QinQ demonstrably done in hardware as well as IPv4 route lookups. I will be putting these switches into production soon on the IPng Networks links between Glattbrugg and Rümlang in Zurich, thereby upgrading our backbone from 10G to 25G CWDM. It seems to me, that using these switches as L3 devices given a smaller OSPF routing domain (currently, we have ~300 prefixes in our OSPF at AS50869), would definitely work well, as would pushing and popping QinQ trunks for our customers (for example on Solnet or Init7 or Openfactory).
Approved. A+, will buy again.