
About this series
Ever since I first saw VPP - the Vector Packet Processor - I have been deeply impressed with its performance and versatility. For those of us who have used Cisco IOS/XR devices, like the classic ASR (aggregation services router), VPP will look and feel quite familiar as many of the approaches are shared between the two.
After completing the Linux CP plugin, interfaces and their attributes such as addresses and routes can be shared between VPP and the Linux kernel in a clever way, so running software like FRR or Bird on top of VPP and achieving >100Mpps and >100Gbps forwarding rates are easily in reach!
If you’ve read my previous articles (thank you!), you will have noticed that I have done a lot of work on making VPP work well in an ISP (BGP/OSPF) environment with Linux CP. However, there’s many other cool things about VPP that make it a very competent advanced services router. One that that has always been super interesting to me, is being able to offer L2 connectivity over wide-area-network. For example, a virtual leased line from our Colo in Zurich to Amsterdam NIKHEF. This article explores this space.
NOTE: If you’re only interested in results, scroll all the way down to the markdown table and graph for performance stats.
Introduction
ISPs can offer ethernet services, often called Virtual Leased Lines (VLLs), Layer2 VPN (L2VPN) or Ethernet Backhaul. They mean the same thing: imagine a switchport in location A that appears to be transparently and directly connected to a switchport in location B, with the ISP (layer3, so IPv4 and IPv6) network in between. The “simple” old-school setup would be to have switches which define VLANs and are all interconnected. But we collectively learned that it’s a bad idea for several reasons:
- Large broadcast domains tend to encouter L2 forwarding loops sooner rather than later
- Spanning-Tree and its kin are a stopgap, but they often disable an entire port from forwarding, which can be expensive if that port is connected to a dark fiber into another datacenter far away.
- Large VLAN setups that are intended to interconnect with other operators run into overlapping VLAN tags, which means switches have to do tag rewriting and filtering and such.
- Traffic engineering is all but non-existent in L2-only networking domains, while L3 has all sorts of smart TE extensions, ECMP, and so on.
The canonical solution is for ISPs to encapsulate the ethernet traffic of their customers in some tunneling mechanism, for example in MPLS or in some IP tunneling protocol. Fundamentally, these are the same, except for the chosen protocol and overhead/cost of forwarding. MPLS is a very thin layer under the packet, but other IP based tunneling mechanisms exist, commonly used are GRE, VXLAN and GENEVE but many others exist.
They all work roughly the same:
- An IP packet has a maximum transmission unit (MTU) of 1500 bytes, while the ethernet header is
typically an additional 14 bytes: a 6 byte source MAC, 6 byte destination MAC, and 2 byte ethernet
type, which is 0x0800 for an IPv4 datagram, 0x0806 for ARP, and 0x86dd for IPv6, and many others
[ref].
- If VLANs are used, an additional 4 bytes are needed [ref] making the ethernet frame at most 1518 bytes long, with an ethertype of 0x8100.
- If QinQ or QinAD are used, yet again 4 bytes are needed [ref], making the ethernet frame at most 1522 bytes long, with an ethertype of either 0x8100 or 0x9100, depending on the implementation.
- We can take such an ethernet frame, and make it the payload of another IP packet, encapsulating the original ethernet frame in a new IPv4 or IPv6 packet. We can then route it over an IP network to a remote site.
- Upon receipt of such a packet, by looking at the headers the remote router can determine that this packet represents an encapsulated ethernet frame, unpack it all, and forward the original frame onto a given interface.
IP Tunneling Protocols
First let’s get some theory out of the way – I’ll discuss three common IP tunneling protocols here, and then move on to demonstrate how they are configured in VPP and perhaps more importantly, how they perform in VPP. Each tunneling protocol has its own advantages and disadvantages, but I’ll stick to the basics first:
GRE: Generic Routing Encapsulation
Generic Routing Encapsulation (GRE, described in RFC2784) is a very old and well known tunneling protocol. The packet is an IP datagram with protocol number 47, consisting of a header with 4 bits of flags, 8 reserved bits, 3 bits for the version (normally set to all-zeros), and 16 bits for the inner protocol (ether)type, so 0x0800 for IPv4, 0x8100 for 802.1q and so on. It’s a very small header of only 4 bytes and an optional key (4 bytes) and sequence number (also 4 bytes) whieah means that to be able to transport any ethernet frame (including the fancy QinQ and QinAD ones), the underlay must have an end to end MTU of at least 1522 + 20(IPv4)+12(GRE) = 1554 bytes for IPv4 and 1574 bytes for IPv6.
VXLAN: Virtual Extensible LAN
Virtual Extensible LAN (VXLAN, described in RFC7348) is a UDP datagram which has a header consisting of 8 bits worth of flags, 24 bits reserved for future expansion, 24 bits of Virtual Network Identifier (VNI) and an additional 8 bits or reserved space at the end. It uses UDP port 4789 as assigned by IANA. VXLAN encapsulation adds 20(IPv4)+8(UDP)+8(VXLAN) = 36 bytes, and considering IPv6 is 40 bytes, there it adds 56 bytes. This means that to be able to transport any ethernet frame, the underlay network must have an end to end MTU of at least 1522+36 = 1558 bytes for IPv4 and 1578 bytes for IPv6.
GENEVE: Generic Network Virtualization Encapsulation
GEneric NEtwork Virtualization Encapsulation (GENEVE, described in RFC8926) is somewhat similar to VXLAN although it was an attempt to stop the wild growth of tunneling protocols, I’m sure there is an XKCD out there specifically for this approach. The packet is also a UDP datagram with destination port 6081, followed by an 8 byte GENEVE specific header, containing 2 bits of version, 8 bits for flags, a 16 bit inner ethertype, a 24 bit Virtual Network Identifier (VNI), and 8 bits of reserved space. With GENEVE, several options are available and will be tacked onto the GENEVE header, but they are typically not used. If they are though, the options can add an additional 16 bytes which means that to be able to transport any ethernet frame, the underlay network must have an end to end MTU of at least 1522+52 = 1574 bytes for IPv4 and 1594 bytes for IPv6.
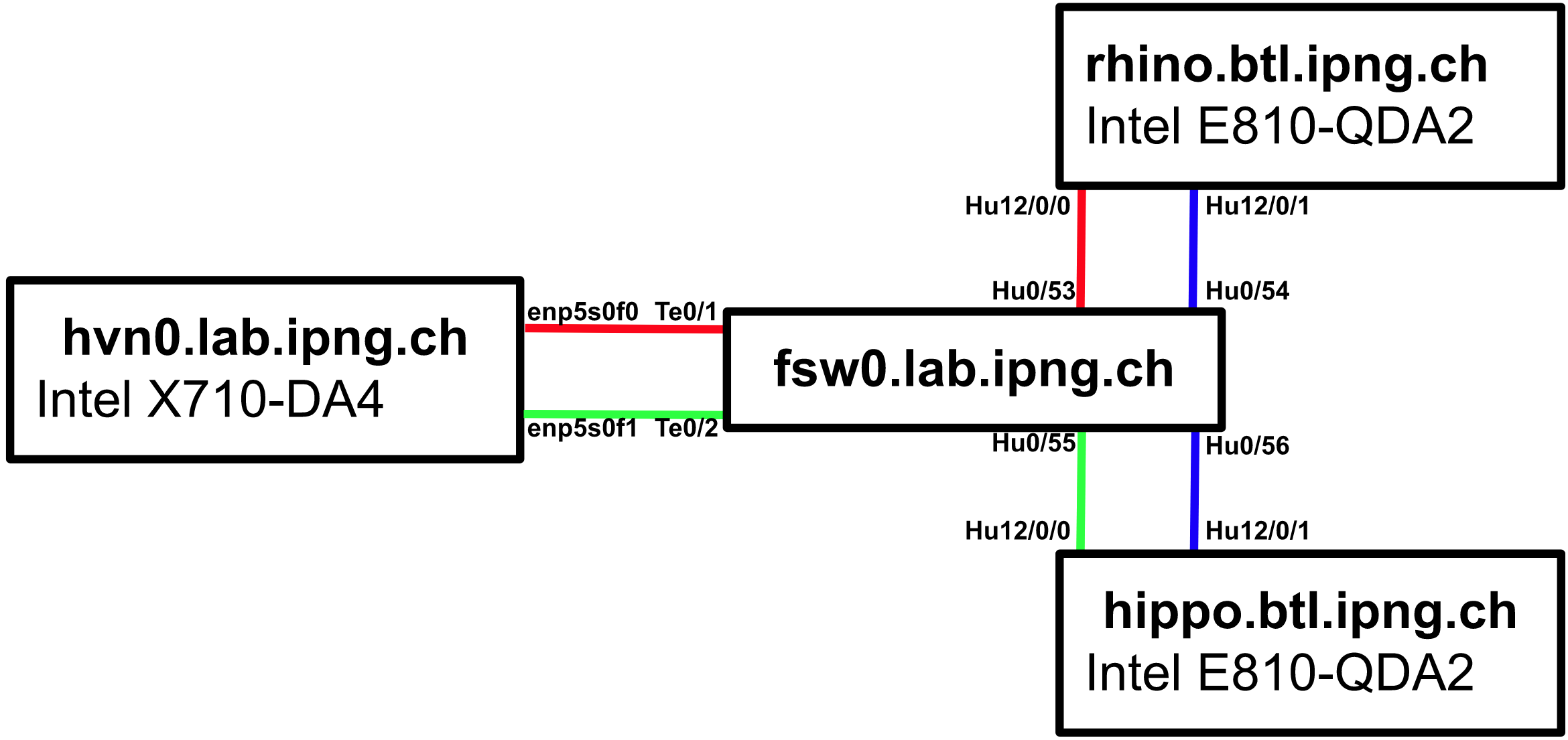
Hardware setup
First let’s take a look at the physical setup. I’m using three servers and a switch in the IPng Networks lab:
hvn0: Dell R720xd, load generator- Dual E5-2620, 24 CPUs, 2 threads per core, 2 numa nodes
- 64GB DDR3 at 1333MT/s
- Intel X710 4-port 10G, Speed 8.0GT/s Width x8 (64 Gbit/s)
HippoandRhino: VPP routers- ASRock B550 Taichi
- Ryzen 5950X 32 CPUs, 2 threads per core, 1 numa node
- 64GB DDR4 at 2133 MT/s
- Intel 810C 2-port 100G, Speed 16.0 GT/s Width x16 (256 Gbit/s)
fsw0: FS.com switch S5860-48SC, 8x 100G, 48x 10G- VLAN 4 (blue) connects Rhino’s
Hu12/0/1to Hippo’sHu12/0/1 - VLAN 5 (red) connects hvn0’s
enp5s0f0to Rhino’sHu12/0/0 - VLAN 6 (green) connects hvn0’s
enp5s0f1to Hippo’sHu12/0/0 - All switchports have jumbo frames enabled and are set to 9216 bytes.
- VLAN 4 (blue) connects Rhino’s
Further, Hippo and Rhino are running VPP at head vpp v22.02-rc0~490-gde3648db0, and hvn0 is running
T-Rex v2.93 in L2 mode, with MAC address 00:00:00:01:01:00 on the first port, and MAC address
00:00:00:02:01:00 on the second port. This machine can saturate 10G in both directions with small
packets even when using only one flow, as can be seen, if the ports are just looped back onto one
another, for example by physically crossconnecting them with an SFP+ or DAC; or in my case by putting
fsw0 port Te0/1 and Te0/2 in the same VLAN together:
Now that I have shared all the context and hardware, I’m ready to actually dive in to what I wanted to talk about: how does all this virtual leased line business look like, for VPP. Ready? Here we go!
Direct L2 CrossConnect
The simplest thing I can show in VPP, is to configure a layer2 cross-connect (l2 xconnect) between two ports. In this case, VPP doesn’t even need to have an IP address, all I do is bring up the ports, set their MTU to be able to carry the 1522 bytes frames (ethernet at 1514, dot1q at 1518, and QinQ at 1522 bytes). The configuration is identical on both Rhino and Hippo:
set interface state HundredGigabitEthernet12/0/0 up
set interface state HundredGigabitEthernet12/0/1 up
set interface mtu packet 1522 HundredGigabitEthernet12/0/0
set interface mtu packet 1522 HundredGigabitEthernet12/0/1
set interface l2 xconnect HundredGigabitEthernet12/0/0 HundredGigabitEthernet12/0/1
set interface l2 xconnect HundredGigabitEthernet12/0/1 HundredGigabitEthernet12/0/0
I’d say the only thing to keep in mind here, is that the cross-connect commands only
link in one direction (receive in A, forward to B), and that’s why I have to type them twice (receive in B,
forward to A). Of course, this must be really cheap on VPP – because all it has to do now is receive
from DPDK and immediately schedule for transmit on the other port. Looking at show runtime I can
see how much CPU time is spent in each of VPP’s nodes:
Time 1241.5, 10 sec internal node vector rate 28.70 loops/sec 475009.85
vector rates in 1.4879e7, out 1.4879e7, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/1-o 650727833 18472218801 7.49e0 28.39
HundredGigabitEthernet12/0/1-t 650727833 18472218801 4.12e1 28.39
ethernet-input 650727833 18472218801 5.55e1 28.39
l2-input 650727833 18472218801 1.52e1 28.39
l2-output 650727833 18472218801 1.32e1 28.39
In this simple cross connect mode, the only thing VPP has to do is receive the ethernet, funnel it
into l2-input, and immediately send it straight through l2-output back out, which does not cost
much in terms of CPU cycles at all. In total, this CPU thread is forwarding 14.88Mpps (line rate 10G
at 64 bytes), at an average of 133 cycles per packet (not counting the time spent in DPDK). The CPU
has room to spare in this mode, in other words even one CPU thread can handle this workload at
line rate, impressive!
Although cool, doing an L2 crossconnect like this isn’t super useful. Usually, the customer leased line has to be transported to another location, and for that we’ll need some form of encapsulation …
Crossconnect over IPv6 VXLAN
Let’s start with VXLAN. The concept is pretty straight forward in VPP. Based on the configuration
I put in Rhino and Hippo above, I first will have to bring Hu12/0/1 out of L2 mode, give both interfaces an
IPv6 address, create a tunnel with a given VNI, and then crossconnect the customer side Hu12/0/0
into the vxlan_tunnel0 and vice-versa. Piece of cake:
## On Rhino
set interface mtu packet 1600 HundredGigabitEthernet12/0/1
set interface l3 HundredGigabitEthernet12/0/1
set interface ip address HundredGigabitEthernet12/0/1 2001:db8::1/64
create vxlan tunnel instance 0 src 2001:db8::1 dst 2001:db8::2 vni 8298
set interface state vxlan_tunnel0 up
set interface mtu packet 1522 vxlan_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 vxlan_tunnel0
set interface l2 xconnect vxlan_tunnel0 HundredGigabitEthernet12/0/0
## On Hippo
set interface mtu packet 1600 HundredGigabitEthernet12/0/1
set interface l3 HundredGigabitEthernet12/0/1
set interface ip address HundredGigabitEthernet12/0/1 2001:db8::2/64
create vxlan tunnel instance 0 src 2001:db8::2 dst 2001:db8::1 vni 8298
set interface state vxlan_tunnel0 up
set interface mtu packet 1522 vxlan_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 vxlan_tunnel0
set interface l2 xconnect vxlan_tunnel0 HundredGigabitEthernet12/0/0
Of course, now we’re actually beginning to make VPP do some work, and the exciting thing is, if there would be an (opaque) ISP network between Rhino and Hippo, this would work just fine considering the encapsulation is ‘just’ IPv6 UDP. Under the covers, for each received frame, VPP has to encapsulate it into VXLAN, and route the resulting L3 packet by doing an IPv6 routing table lookup:
Time 10.0, 10 sec internal node vector rate 256.00 loops/sec 32132.74
vector rates in 8.5423e6, out 8.5423e6, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 333777 85445944 2.74e0 255.99
HundredGigabitEthernet12/0/0-t 333777 85445944 5.28e1 255.99
ethernet-input 333777 85445944 4.25e1 255.99
ip6-input 333777 85445944 1.25e1 255.99
ip6-lookup 333777 85445944 2.41e1 255.99
ip6-receive 333777 85445944 1.71e2 255.99
ip6-udp-lookup 333777 85445944 1.55e1 255.99
l2-input 333777 85445944 8.94e0 255.99
l2-output 333777 85445944 4.44e0 255.99
vxlan6-input 333777 85445944 2.12e1 255.99
I can definitely see a lot more action here. In this mode, VPP is handlnig 8.54Mpps on this CPU thread
before saturating. At full load, VPP is spending 356 CPU cycles per packet, of which almost half is in
node ip6-receive.
Crossconnect over IPv4 VXLAN
Seeing ip6-receive being such a big part of the cost (almost half!), I wonder what it might look like if
I change the tunnel to use IPv4. So I’ll give Rhino and Hippo an IPv4 address as well, delete the vxlan tunnel I made
before (the IPv6 one), and create a new one with IPv4:
set interface ip address HundredGigabitEthernet12/0/1 10.0.0.0/31
create vxlan tunnel instance 0 src 2001:db8::1 dst 2001:db8::2 vni 8298 del
create vxlan tunnel instance 0 src 10.0.0.0 dst 10.0.0.1 vni 8298
set interface state vxlan_tunnel0 up
set interface mtu packet 1522 vxlan_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 vxlan_tunnel0
set interface l2 xconnect vxlan_tunnel0 HundredGigabitEthernet12/0/0
set interface ip address HundredGigabitEthernet12/0/1 10.0.0.1/31
create vxlan tunnel instance 0 src 2001:db8::2 dst 2001:db8::1 vni 8298 del
create vxlan tunnel instance 0 src 10.0.0.1 dst 10.0.0.0 vni 8298
set interface state vxlan_tunnel0 up
set interface mtu packet 1522 vxlan_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 vxlan_tunnel0
set interface l2 xconnect vxlan_tunnel0 HundredGigabitEthernet12/0/0
And after letting this run for a few seconds, I can take a look and see how the ip4-* version of
the VPP code performs:
Time 10.0, 10 sec internal node vector rate 256.00 loops/sec 53309.71
vector rates in 1.4151e7, out 1.4151e7, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 552890 141539600 2.76e0 255.99
HundredGigabitEthernet12/0/0-t 552890 141539600 5.30e1 255.99
ethernet-input 552890 141539600 4.13e1 255.99
ip4-input-no-checksum 552890 141539600 1.18e1 255.99
ip4-lookup 552890 141539600 1.68e1 255.99
ip4-receive 552890 141539600 2.74e1 255.99
ip4-udp-lookup 552890 141539600 1.79e1 255.99
l2-input 552890 141539600 8.68e0 255.99
l2-output 552890 141539600 4.41e0 255.99
vxlan4-input 552890 141539600 1.76e1 255.99
Throughput is now quite a bit higher, clocking a cool 14.2Mpps (just short of line rate!) at 202 CPU cycles per packet, considerably less time spent than in IPv6, but keep in mind that VPP has an ~empty routing table in all of these tests.
Crossconnect over IPv6 GENEVE
Another popular cross connect type, also based on IPv4 and IPv6 UDP packets, is GENEVE. The configuration is almost identical, so I delete the IPv4 VXLAN and create an IPv6 GENEVE tunnel instead:
create vxlan tunnel instance 0 src 10.0.0.0 dst 10.0.0.1 vni 8298 del
create geneve tunnel local 2001:db8::1 remote 2001:db8::2 vni 8298
set interface state geneve_tunnel0 up
set interface mtu packet 1522 geneve_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 geneve_tunnel0
set interface l2 xconnect geneve_tunnel0 HundredGigabitEthernet12/0/0
create vxlan tunnel instance 0 src 10.0.0.1 dst 10.0.0.0 vni 8298 del
create geneve tunnel local 2001:db8::2 remote 2001:db8::1 vni 8298
set interface state geneve_tunnel0 up
set interface mtu packet 1522 geneve_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 geneve_tunnel0
set interface l2 xconnect geneve_tunnel0 HundredGigabitEthernet12/0/0
All the while, the TRex on the customer machine hvn0, is sending 14.88Mpps in both directions, and
after just a short (second or so) interruption, the GENEVE tunnel comes up, cross-connects into the
customer Hu12/0/0 interfaces, and starts to carry traffic:
Thread 8 vpp_wk_7 (lcore 8)
Time 10.0, 10 sec internal node vector rate 256.00 loops/sec 29688.03
vector rates in 8.3179e6, out 8.3179e6, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 324981 83194664 2.74e0 255.99
HundredGigabitEthernet12/0/0-t 324981 83194664 5.18e1 255.99
ethernet-input 324981 83194664 4.26e1 255.99
geneve6-input 324981 83194664 3.87e1 255.99
ip6-input 324981 83194664 1.22e1 255.99
ip6-lookup 324981 83194664 2.39e1 255.99
ip6-receive 324981 83194664 1.67e2 255.99
ip6-udp-lookup 324981 83194664 1.54e1 255.99
l2-input 324981 83194664 9.28e0 255.99
l2-output 324981 83194664 4.47e0 255.99
Similar to VXLAN when using IPv6 the total for GENEVE-v6 is also comparatively slow (I say comparatively
because you should not expect anything like this performance when using Linux or BSD kernel routing!).
The lower throughput is again due to the ip6-receive node being costly. It is just slightly worse of a
performer at 8.32Mpps per core and 368 CPU cycles per packet.
Crossconnect over IPv4 GENEVE
I am now suspecting that GENEVE over IPv4 would have similar gains to when I switched from VXLAN IPv6 to IPv4 above. So I remove the IPv6 tunnel, create a new IPv4 tunnel instead, and hook it back up to the customer port on both Rhino and Hippo, like so:
create geneve tunnel local 2001:db8::1 remote 2001:db8::2 vni 8298 del
create geneve tunnel local 10.0.0.0 remote 10.0.0.1 vni 8298
set interface state geneve_tunnel0 up
set interface mtu packet 1522 geneve_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 geneve_tunnel0
set interface l2 xconnect geneve_tunnel0 HundredGigabitEthernet12/0/0
create geneve tunnel local 2001:db8::2 remote 2001:db8::1 vni 8298 del
create geneve tunnel local 10.0.0.1 remote 10.0.0.0 vni 8298
set interface state geneve_tunnel0 up
set interface mtu packet 1522 geneve_tunnel0
set interface l2 xconnect HundredGigabitEthernet12/0/0 geneve_tunnel0
set interface l2 xconnect geneve_tunnel0 HundredGigabitEthernet12/0/0
And the results, indeed a significant improvement:
Time 10.0, 10 sec internal node vector rate 256.00 loops/sec 48639.97
vector rates in 1.3737e7, out 1.3737e7, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 536763 137409904 2.76e0 255.99
HundredGigabitEthernet12/0/0-t 536763 137409904 5.19e1 255.99
ethernet-input 536763 137409904 4.19e1 255.99
geneve4-input 536763 137409904 2.39e1 255.99
ip4-input-no-checksum 536763 137409904 1.18e1 255.99
ip4-lookup 536763 137409904 1.69e1 255.99
ip4-receive 536763 137409904 2.71e1 255.99
ip4-udp-lookup 536763 137409904 1.79e1 255.99
l2-input 536763 137409904 8.81e0 255.99
l2-output 536763 137409904 4.47e0 255.99
So, close to line rate again! Performance of GENEVE-v4 clocks in at 13.7Mpps per core or 207 CPU cycles per packet.
Crossconnect over IPv6 GRE
Now I can’t help but wonder, that if those ip4|6-udp-lookup nodes burn valuable CPU cycles,
GRE will possibly do better, because it’s an L3 protocol (proto number 47) and will never have to
inspect beyond the IP header, so I delete the GENEVE tunnel and give GRE a go too:
create geneve tunnel local 10.0.0.0 remote 10.0.0.1 vni 8298 del
create gre tunnel src 2001:db8::1 dst 2001:db8::2 teb
set interface state gre0 up
set interface mtu packet 1522 gre0
set interface l2 xconnect HundredGigabitEthernet12/0/0 gre0
set interface l2 xconnect gre0 HundredGigabitEthernet12/0/0
create geneve tunnel local 10.0.0.1 remote 10.0.0.0 vni 8298 del
create gre tunnel src 2001:db8::2 dst 2001:db8::1 teb
set interface state gre0 up
set interface mtu packet 1522 gre0
set interface l2 xconnect HundredGigabitEthernet12/0/0 gre0
set interface l2 xconnect gre0 HundredGigabitEthernet12/0/0
Results:
Time 10.0, 10 sec internal node vector rate 255.99 loops/sec 37129.87
vector rates in 9.9254e6, out 9.9254e6, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 387881 99297464 2.80e0 255.99
HundredGigabitEthernet12/0/0-t 387881 99297464 5.21e1 255.99
ethernet-input 775762 198594928 5.97e1 255.99
gre6-input 387881 99297464 2.81e1 255.99
ip6-input 387881 99297464 1.21e1 255.99
ip6-lookup 387881 99297464 2.39e1 255.99
ip6-receive 387881 99297464 5.09e1 255.99
l2-input 387881 99297464 9.35e0 255.99
l2-output 387881 99297464 4.40e0 255.99
The performance of GRE-v6 (in transparent ethernet bridge aka TEB mode) is 9.9Mpps per core or
243 CPU cycles per packet, and I’ll also note that while the ip6-receive node in all the
UDP based tunneling were in the 170 clocks/packet arena, now we’re down to only 51 or so, so
indeed a huge improvement.
Crossconnect over IPv4 GRE
To round off the set, I’ll remove the IPv6 GRE tunnel and put an IPv4 GRE tunnel in place:
create gre tunnel src 2001:db8::1 dst 2001:db8::2 teb del
create gre tunnel src 10.0.0.0 dst 10.0.0.1 teb
set interface state gre0 up
set interface mtu packet 1522 gre0
set interface l2 xconnect HundredGigabitEthernet12/0/0 gre0
set interface l2 xconnect gre0 HundredGigabitEthernet12/0/0
create gre tunnel src 2001:db8::2 dst 2001:db8::1 teb del
create gre tunnel src 10.0.0.1 dst 10.0.0.0 teb
set interface state gre0 up
set interface mtu packet 1522 gre0
set interface l2 xconnect HundredGigabitEthernet12/0/0 gre0
set interface l2 xconnect gre0 HundredGigabitEthernet12/0/0
And without further ado:
Time 10.0, 10 sec internal node vector rate 255.87 loops/sec 52898.61
vector rates in 1.4039e7, out 1.4039e7, drop 0.0000e0, punt 0.0000e0
Name Calls Vectors Clocks Vectors/Call
HundredGigabitEthernet12/0/0-o 548684 140435080 2.80e0 255.95
HundredGigabitEthernet12/0/0-t 548684 140435080 5.22e1 255.95
ethernet-input 1097368 280870160 2.92e1 255.95
gre4-input 548684 140435080 2.51e1 255.95
ip4-input-no-checksum 548684 140435080 1.19e1 255.95
ip4-lookup 548684 140435080 1.68e1 255.95
ip4-receive 548684 140435080 2.03e1 255.95
l2-input 548684 140435080 8.72e0 255.95
l2-output 548684 140435080 4.43e0 255.95
The performance of GRE-v4 (in transparent ethernet bridge aka TEB mode) is 14.0Mpps per core or 171 CPU cycles per packet. This is really very low, the best of all the tunneling protocols, but (for obvious reasons) will not outperform a direct L2 crossconnect, as that cuts out the L3 (and L4) middleperson entirely. Whohoo!
Conclusions
First, let me give a recap of the tests I did, from left to right the better to worse performer.
| Test | L2XC | GRE-v4 | VXLAN-v4 | GENEVE-v4 | GRE-v6 | VXLAN-v6 | GENEVE-v6 |
|---|---|---|---|---|---|---|---|
| pps/core | >14.88M | 14.34M | 14.15M | 13.74M | 9.93M | 8.54M | 8.32M |
| cycles/packet | 132.59 | 171.45 | 201.65 | 207.44 | 243.35 | 355.72 | 368.09 |
(!) Achtung! Because in the L2XC mode the CPU was not fully consumed (VPP was consuming only ~28 frames per vector), it did not yet achieve its optimum CPU performance. Under full load, the cycles/packet will be somewhat lower than what is shown here.
Taking a closer look at the VPP nodes in use, below I draw a graph of CPU cycles spent in each VPP node, for each type of cross connect, where the lower the stack is, the faster cross connect will be:
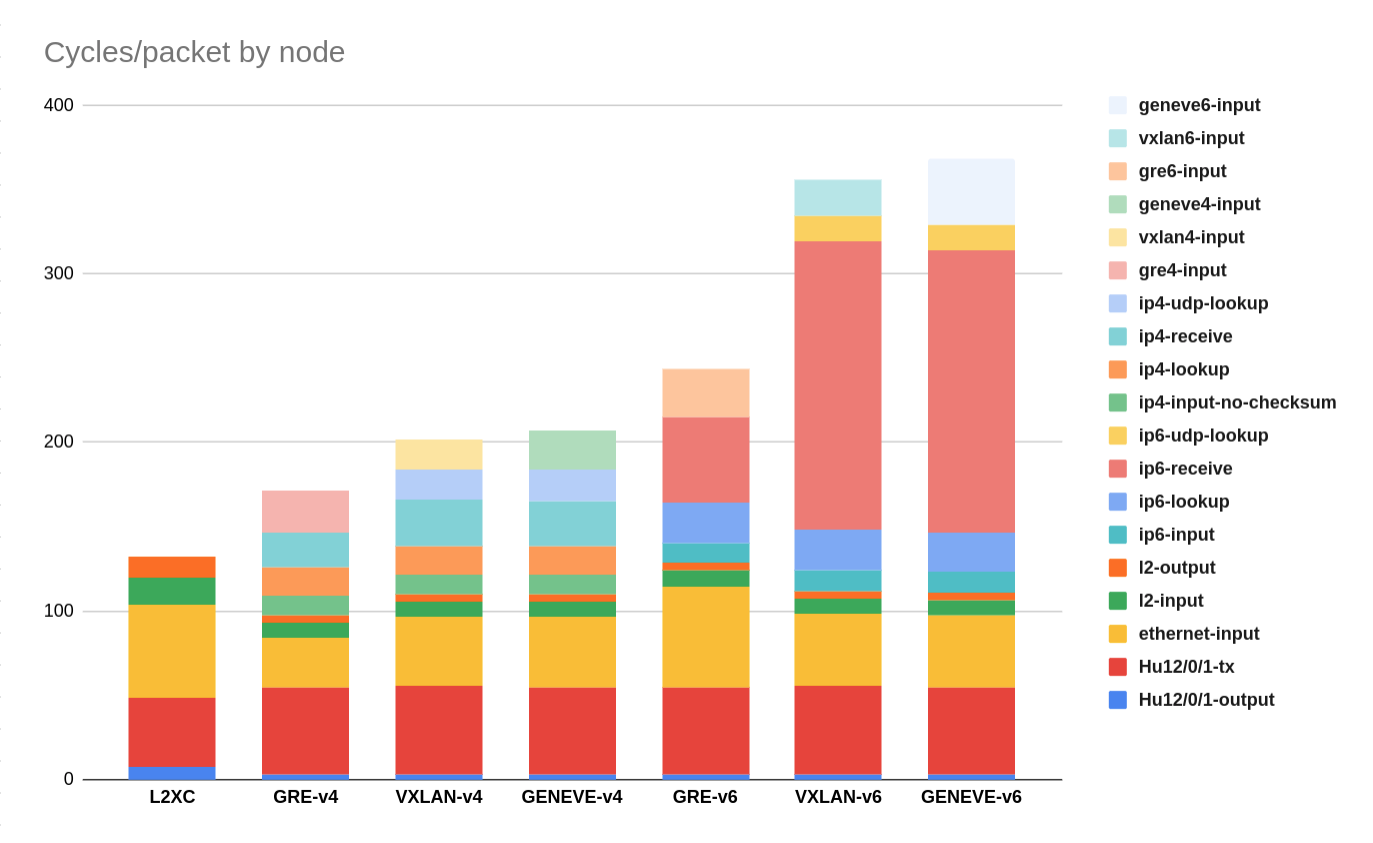
Although clearly GREv4 is the winner, I still would not use it for the following reason: VPP does not support GRE keys, and considering it is an L3 protocol, I will have to use unique IPv4 or IPv6 addresses for each tunnel src/dst pair, otherwise VPP will not know upon receipt of a GRE packet, which tunnel it belongs to. For IPv6 this is not a huge deal (I can bind a whole /64 to a loopback and just be done with it), but GREv6 does not perform as well as VXLAN-v4 or GENEVE-v4.
VXLAN and GENEVE are equal performers, both in IPv4 and in IPv6. In both cases, IPv4 is significantly faster than IPv6. But due to the use of VNI fields in the header, contrary to GRE, both VXLAN and GENEVE can have the same src/dst IP for any number of tunnels, which is a huge benefit.
Multithreading
Usually, the customer facing side is an ethernet port (or sub-interface with tag popping) that will be receiving IPv4 or IPv6 traffic (either tagged or untagged) and this allows the NIC to use RSS to assign this inbound traffic to multiple queues, and thus multiple CPU threads. That’s great, it means linear encapsulation performance.
Once the traffic is encapsulated, it risks becoming single flow with respect to the remote host, if
Rhino would be sending from 10.0.0.0:4789 to Hippo’s 10.0.0.1:4789. However, the VPP VXLAN and GENEVE
implementation both inspect the inner payload, and uses it to scramble the source port (thanks to
Neale for pointing this out, it’s in vxlan/encap.c:246). Deterministically changing the source port
based on the inner-flow will allow Hippo to use RSS on the receiving end, which allows these tunneling
protocols to scale linearly. I proved this for myself by attaching a port-mirror to the switch and
copying all traffic between Hippo and Rhino to a spare machine in the rack:
pim@hvn1:~$ sudo tcpdump -ni enp5s0f3 port 4789
11:19:54.887763 IP 10.0.0.1.4452 > 10.0.0.0.4789: VXLAN, flags [I] (0x08), vni 8298
11:19:54.888283 IP 10.0.0.1.42537 > 10.0.0.0.4789: VXLAN, flags [I] (0x08), vni 8298
11:19:54.888285 IP 10.0.0.0.17895 > 10.0.0.1.4789: VXLAN, flags [I] (0x08), vni 8298
11:19:54.899353 IP 10.0.0.1.40751 > 10.0.0.0.4789: VXLAN, flags [I] (0x08), vni 8298
11:19:54.899355 IP 10.0.0.0.35475 > 10.0.0.1.4789: VXLAN, flags [I] (0x08), vni 8298
11:19:54.904642 IP 10.0.0.0.60633 > 10.0.0.1.4789: VXLAN, flags [I] (0x08), vni 8298
pim@hvn1:~$ sudo tcpdump -ni enp5s0f3 port 6081
11:22:55.802406 IP 10.0.0.0.32299 > 10.0.0.1.6081: Geneve, Flags [none], vni 0x206a:
11:22:55.802409 IP 10.0.0.1.44011 > 10.0.0.0.6081: Geneve, Flags [none], vni 0x206a:
11:22:55.807711 IP 10.0.0.1.45503 > 10.0.0.0.6081: Geneve, Flags [none], vni 0x206a:
11:22:55.807712 IP 10.0.0.0.45532 > 10.0.0.1.6081: Geneve, Flags [none], vni 0x206a:
11:22:55.841495 IP 10.0.0.0.61694 > 10.0.0.1.6081: Geneve, Flags [none], vni 0x206a:
11:22:55.851719 IP 10.0.0.1.47581 > 10.0.0.0.6081: Geneve, Flags [none], vni 0x206a:
Considering I was sending the T-Rex profile bench.py with tunables vm=var2,size=64, the latter
of which chooses randomized source and destination (inner) IP addresses in the loadtester, I can
conclude that the outer source port is chosen based on a hash of the inner packet. Slick!!
Final conclusion
The most important practical conclusion to draw is that I can feel safe to offer L2VPN services at IPng Networks using VPP and a VXLAN or GENEVE IPv4 underlay – our backbone is 9000 bytes everywhere, so it will be possible to provide up to 8942 bytes of customer payload taking into account the VXLAN-v4 overhead. At least gigabit symmetric VLLs filled with 64b packets will not be a problem for the routers we have, as they forward approximately 10.2Mpps per core and 35Mpps per chassis when fully loaded. Even considering the overhead and CPU consumption that VXLAN encap/decap brings with it, due to the use of multiple transmit and receive threads, the router would have plenty of room to spare.
Appendix
The backing data for the graph in this article are captured in this Google Sheet.
VPP Configuration
For completeness, the startup.conf used on both Rhino and Hippo:
unix {
nodaemon
log /var/log/vpp/vpp.log
full-coredump
cli-listen /run/vpp/cli.sock
cli-prompt rhino#
gid vpp
}
api-trace { on }
api-segment { gid vpp }
socksvr { default }
memory {
main-heap-size 1536M
main-heap-page-size default-hugepage
}
cpu {
main-core 0
corelist-workers 1-15
}
buffers {
buffers-per-numa 300000
default data-size 2048
page-size default-hugepage
}
statseg {
size 1G
page-size default-hugepage
per-node-counters off
}
dpdk {
dev default {
num-rx-queues 7
}
decimal-interface-names
dev 0000:0c:00.0
dev 0000:0c:00.1
}
plugins {
plugin lcpng_nl_plugin.so { enable }
plugin lcpng_if_plugin.so { enable }
}
logging {
default-log-level info
default-syslog-log-level crit
class linux-cp/if { rate-limit 10000 level debug syslog-level debug }
class linux-cp/nl { rate-limit 10000 level debug syslog-level debug }
}
lcpng {
default netns dataplane
lcp-sync
lcp-auto-subint
}
Other Details
For posterity, some other stats on the VPP deployment. First of all, a confirmation that PCIe 4.0 x16 slots were used, and that the Comms DDP was loaded:
[ 0.433903] pci 0000:0c:00.0: [8086:1592] type 00 class 0x020000
[ 0.433924] pci 0000:0c:00.0: reg 0x10: [mem 0xea000000-0xebffffff 64bit pref]
[ 0.433946] pci 0000:0c:00.0: reg 0x1c: [mem 0xee010000-0xee01ffff 64bit pref]
[ 0.433964] pci 0000:0c:00.0: reg 0x30: [mem 0xfcf00000-0xfcffffff pref]
[ 0.434104] pci 0000:0c:00.0: reg 0x184: [mem 0xed000000-0xed01ffff 64bit pref]
[ 0.434106] pci 0000:0c:00.0: VF(n) BAR0 space: [mem 0xed000000-0xedffffff 64bit pref] (contains BAR0 for 128 VFs)
[ 0.434128] pci 0000:0c:00.0: reg 0x190: [mem 0xee220000-0xee223fff 64bit pref]
[ 0.434129] pci 0000:0c:00.0: VF(n) BAR3 space: [mem 0xee220000-0xee41ffff 64bit pref] (contains BAR3 for 128 VFs)
[ 11.216343] ice 0000:0c:00.0: The DDP package was successfully loaded: ICE COMMS Package version 1.3.30.0
[ 11.280567] ice 0000:0c:00.0: PTP init successful
[ 11.317826] ice 0000:0c:00.0: DCB is enabled in the hardware, max number of TCs supported on this port are 8
[ 11.317828] ice 0000:0c:00.0: FW LLDP is disabled, DCBx/LLDP in SW mode.
[ 11.317829] ice 0000:0c:00.0: Commit DCB Configuration to the hardware
[ 11.320608] ice 0000:0c:00.0: 252.048 Gb/s available PCIe bandwidth (16.0 GT/s PCIe x16 link)
And how the NIC shows up in VPP, in particular the rx/tx burst modes and functions are interesting:
hippo# show hardware-interfaces
Name Idx Link Hardware
HundredGigabitEthernet12/0/0 1 up HundredGigabitEthernet12/0/0
Link speed: 100 Gbps
RX Queues:
queue thread mode
0 vpp_wk_0 (1) polling
1 vpp_wk_1 (2) polling
2 vpp_wk_2 (3) polling
3 vpp_wk_3 (4) polling
4 vpp_wk_4 (5) polling
5 vpp_wk_5 (6) polling
6 vpp_wk_6 (7) polling
Ethernet address b4:96:91:b3:b1:10
Intel E810 Family
carrier up full duplex mtu 9190 promisc
flags: admin-up promisc maybe-multiseg tx-offload intel-phdr-cksum rx-ip4-cksum int-supported
Devargs:
rx: queues 7 (max 64), desc 1024 (min 64 max 4096 align 32)
tx: queues 16 (max 64), desc 1024 (min 64 max 4096 align 32)
pci: device 8086:1592 subsystem 8086:0002 address 0000:0c:00.00 numa 0
max rx packet len: 9728
promiscuous: unicast on all-multicast on
vlan offload: strip off filter off qinq off
rx offload avail: vlan-strip ipv4-cksum udp-cksum tcp-cksum qinq-strip
outer-ipv4-cksum vlan-filter vlan-extend jumbo-frame
scatter keep-crc rss-hash
rx offload active: ipv4-cksum jumbo-frame scatter
tx offload avail: vlan-insert ipv4-cksum udp-cksum tcp-cksum sctp-cksum
tcp-tso outer-ipv4-cksum qinq-insert multi-segs mbuf-fast-free
outer-udp-cksum
tx offload active: ipv4-cksum udp-cksum tcp-cksum multi-segs
rss avail: ipv4-frag ipv4-tcp ipv4-udp ipv4-sctp ipv4-other ipv4
ipv6-frag ipv6-tcp ipv6-udp ipv6-sctp ipv6-other ipv6
l2-payload
rss active: ipv4-frag ipv4-tcp ipv4-udp ipv4 ipv6-frag ipv6-tcp
ipv6-udp ipv6
tx burst mode: Scalar
tx burst function: ice_recv_scattered_pkts_vec_avx2_offload
rx burst mode: Offload Vector AVX2 Scattered
rx burst function: ice_xmit_pkts
Finally, in case it’s interesting, an output of lscpu, lspci and dmidecode as run on Hippo (Rhino is an identical machine).