Introduction

If you’ve read up on my articles, you’ll know that I have deployed a European Ring, which was reformatted late last year into AS8298 and upgraded to run VPP Routers with 10G between each city. IPng Networks rents these 10G point to point virtual leased lines between each of our locations. It’s a really great network, and it performs so well because it’s built on an EoMPLS underlay provided by IP-Max. They, in turn, run carrier grade hardware in the form of Cisco ASR9k. In part, we’re such a good match together, because my choice of VPP on the IPng Networks routers fits very well with Fred’s choice of IOS/XR on the IP-Max routers.
And if you follow us on Twitter (I post as @IPngNetworks), you may have seen a recent post where I upgraded an aging ASR9006 with a significantly larger ASR9010. The ASR9006 was initially deployed at Equinix Zurich ZH05 in Oberenstringen near Zurich, Switzerland in 2015, which is seven years ago. It has hauled countless packets from Zurich to Paris, Frankfurt and Lausanne. When it was deployed, it came with a A9K-RSP-4G route switch processor, which in 2019 was upgraded to the A9K-RSP-8G, and after so many hours^W years of runtime needed a replacement. Also, IP-Max was starting to run out of ports for the chassis, hence the upgrade.

If you’re interested in the line-up, there’s this epic reference guide from Cisco Live! that shows a deep dive of the ASR9k architecture. The chassis and power supplies can host several generations of silicon, and even mix-and-match generations. So IP-Max ordered a few new RSPs, and after deploying the ASR9010 at ZH05, we made plans to redeploy this ASR9006 at NTT Zurich in Rümlang next to the airport, to replace an even older Cisco 7600 at that location. Seeing as we have to order XFP optics (IP-Max has some DWDM/CWDM links in service at NTT), we have to park the chassis in and around Zurich. What better place to park it, than in my lab ? :-)
The IPng Networks laboratory is where I do most of my work on VPP. The rack you see to the left here holds my coveted Rhino and Hippo (two beefy AMD Ryzen 5950X machines with 100G network cards), and a few Dells that comprise my VPP lab. There was not enough room, so I gave this little fridge a place just adjacent to the rack, connected with 10x 10Gbps and serial and management ports.
I immediately had a little giggle when booting up the machine. It comes with 4x 3kW power supply slots (3 are installed), and when booting the machine, I was happy that there was no debris laying on the side or back of the router, as its fans create a veritable vortex of airflow. Also, overnight the temperature in my basement lab + office room raised a few degrees. It’s now nice and toasty in my office, no need for the heater in the winter. Yet the machine stays quite cool at 26C intake, consuming 2.2KW idle with each of the two route processor (RSP440) drawing 240 Watts, each of the three 8x TenGigE blades drawing 575W each, and the 40x GigE blade drawing a respectable 320 Watts.
RP/0/RSP0/CPU0:fridge(admin)#show environment power-supply
R/S/I Power Supply Voltage Current
(W) (V) (A)
0/PS0/M1/* 741.1 54.9 13.5
0/PS0/M2/* 712.4 54.8 13.0
0/PS0/M3/* 765.8 55.1 13.9
--------------
Total: 2219.3
For reference, Rhino and Hippo draw approximately 265W each, but they come with 4x1G, 4x10G, 2x100G and forward ~300Mpps when fully loaded. By the end of this article, I hope you’ll see why this is a funny juxtaposition to me.
Installing the ASR9006
The Cisco RSPs came to me new-in-refurbished-box. When booting, I had no idea what username/password was used for the
preinstall, and none of the standard passwords worked. So the first order of business is to take ownership of the
machine. I do this by putting both RSPs in rommon (which is done by sending Break after powercycling the machine –
my choice of tio(1) has Ctrl-t b as the magic incantation). The first RSP (in slot 0) is then set to a different
confreg 0x142, while the other is kept in rommon so it doesn’t boot and take over the machine. After booting, I’m
then presented with a root user setup dialog. I create a user pim with some temporary password, set back the configuration
register, and reload. When the RSP is about to boot, I release the standby RSP to catch up, and voila: I’m In like Flynn.
Wiring this up - I connect Te0/0/0/0 to IPng’s office switch on port sfp-sfpplus9, and I assign the router an IPv4 and IPv6 address. Then, I connect four Tengig ports to the lab switch, so that I can play around with loadtests a little bit. After turning on LLDP, I can see the following physical view:
RP/0/RSP0/CPU0:fridge#show lldp neighbors
Sun Feb 20 19:14:21.775 UTC
Capability codes:
(R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device
(W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
xsw1-btl Te0/0/0/0 120 B,R bridge/sfp-sfpplus9
fsw0 Te0/1/0/0 41 P,B,R TenGigabitEthernet 0/9
fsw0 Te0/1/0/1 41 P,B,R TenGigabitEthernet 0/10
fsw0 Te0/2/0/0 41 P,B,R TenGigabitEthernet 0/7
fsw0 Te0/2/0/1 41 P,B,R TenGigabitEthernet 0/8
Total entries displayed: 5
First, I decide to hook up basic connectivity behind port Te0/0/0/0. I establish OSPF, OSPFv3 and this gives me visibility to the route-reflectors at IPng’s AS8298. Next, I also establish three IPv4 and IPv6 iBGP sessions, so the machine enters the Default Free Zone (also, daaayum, that table keeps on growing at 903K IPv4 prefixes and 143K IPv6 prefixes).
RP/0/RSP0/CPU0:fridge#show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
194.1.163.3 1 2WAY/DROTHER 00:00:35 194.1.163.66 TenGigE0/0/0/0.101
Neighbor is up for 00:11:14
194.1.163.4 1 FULL/BDR 00:00:38 194.1.163.67 TenGigE0/0/0/0.101
Neighbor is up for 00:11:11
194.1.163.87 1 FULL/DR 00:00:37 194.1.163.87 TenGigE0/0/0/0.101
Neighbor is up for 00:11:12
RP/0/RSP0/CPU0:fridge#show ospfv3 neighbor
Neighbor ID Pri State Dead Time Interface ID Interface
194.1.163.87 1 FULL/DR 00:00:35 2 TenGigE0/0/0/0.101
Neighbor is up for 00:12:14
194.1.163.3 1 2WAY/DROTHER 00:00:33 16 TenGigE0/0/0/0.101
Neighbor is up for 00:12:16
194.1.163.4 1 FULL/BDR 00:00:36 20 TenGigE0/0/0/0.101
Neighbor is up for 00:12:12
RP/0/RSP0/CPU0:fridge#show bgp ipv4 uni sum
Process RcvTblVer bRIB/RIB LabelVer ImportVer SendTblVer StandbyVer
Speaker 915517 915517 915517 915517 915517 915517
Neighbor Spk AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down St/PfxRcd
194.1.163.87 0 8298 172514 9 915517 0 0 00:04:47 903406
194.1.163.140 0 8298 171853 9 915517 0 0 00:04:56 903406
194.1.163.148 0 8298 176244 9 915517 0 0 00:04:49 903406
RP/0/RSP0/CPU0:fridge#show bgp ipv6 uni sum
Process RcvTblVer bRIB/RIB LabelVer ImportVer SendTblVer StandbyVer
Speaker 151597 151597 151597 151597 151597 151597
Neighbor Spk AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down St/PfxRcd
2001:678:d78:3::87
0 8298 54763 10 151597 0 0 00:05:19 142542
2001:678:d78:6::140
0 8298 51350 10 151597 0 0 00:05:23 142542
2001:678:d78:7::148
0 8298 54572 10 151597 0 0 00:05:25 142542
One of the acceptance tests of new hardware at AS25091 IP-Max is to ensure that it takes a full table to help ensure memory is present, accounted for, and working. These route switch processor boards come with 12GB of ECC memory, and can scale the routing table for a small while to come. If/when they are at the end of their useful life, they will be replaced with A9K-RSP-880’s, which will also give us access to 40G and 100G and 24x10G SFP+ line cards. At that point, the upgrade path is much easier as the chassis will already be installed. It’s a matter of popping in new RSPs and replacing the line cards one by one.
Loadtesting the ASR9006/RSP440-SE
Now that this router has some basic connectivity, I’ll do something that I always wanted to do: loadtest an ASR9k! I have mad amounts of respect for Cisco’s ASR9k series, but as we’ll soon see, their stability is their most redeeming quality, not their performance. Nowadays, many flashy 100G machines are around, which do indeed have the performance, but not the stability! I’ve seen routers with an uptime of 7 years, and BGP sessions and OSPF adjacencies with an uptime of 5 years+. It’s just .. I’ve not seen that type of stability beyond Cisco and maybe Juniper. So if you want Rock Solid Internet, this is definitely the way to go.
I have written a word or two on how VPP (an open source dataplane very similar to these industrial machines) works. A great example is my recent VPP VLAN Gymnastics article. There’s a lot I can learn from comparing the performance between VPP and Cisco ASR9k, so I will focus on the following set of practical questions:
- See if unidirectional versus bidirectional traffic impacts performance.
- See if there is a performance penalty of using Bundle-Ether (LACP controlled link aggregation).
- Of course, replay my standard issue 1514b large packets, internet mix (imix) packets, small 64b packets from random source/destination addresses (ie. multiple flows); and finally the killer test of small 64b packets from a static source/destination address (ie. single flow).
This is in total 2 (uni/bi) x2 (lag/plain) x4 (packet mix) or 16 loadtest runs, for three forwarding types …
- See performance of L2VPN (Point-to-Point), similar to what VPP would call “l2 xconnect”. I’ll create an L2 crossconnect between port Te0/1/0/0 and Te0/2/0/0; this is the simplest form computationally: it forwards any frame received on the first interface directly out on the second interface.
- Take a look at performance of L2VPN (Bridge Domain), what VPP would call “bridge-domain”. I’ll create a Bridge Domain between port Te0/1/0/0 and Te0/2/0/0; this includes layer2 learning and FIB, and can tie together any number of interfaces into a layer2 broadcast domain.
- And of course, tablestakes, see performance of IPv4 forwarding, with Te0/1/0/0 as 100.64.0.1/30 and Te0/2/0/0 as 100.64.1.1/30 and setting a static for 48.0.0.0/8 and 16.0.0.0/8 back to the loadtester.
… making a grand total of 48 loadtests. I have my work cut out for me! So I boot up Rhino, which has a Mellanox ConnectX5-Ex (PCIe v4.0 x16) network card sporting two 100G interfaces, and it can easily keep up with this 2x10G single interface, and 2x20G LAG, even with 64 byte packets. I am continually amazed that a full line rate loadtest of small 64 byte packets at a rate of 40Gbps boils down to 59.52Mpps!
For each loadtest, I ramp up the traffic using a T-Rex loadtester that I wrote. It starts with a low-pps warmup duration of 30s, then it ramps up from 0% to a certain line rate (in this case, alternating to 10GbpsL1 for the single TenGig tests, or 20GbpsL1 for the LACP tests), with a rampup duration of 120s and finally it holds for duration of 30s.
The following sections describe the methodology and the configuration statements on the ASR9k, with a quick table of results per test, and a longer set of thoughts all the way at the bottom of this document. I so encourage you to not skip ahead. Instead, read on and learn a bit (as I did!) from the configuration itself.
The question to answer: Can this beasty mini-fridge sustain line rate? Let’s go take a look!
Test 1 - 2x 10G
In this test, I configure a very simple physical environment (this is a good time to take another look at the LLDP table above). The Cisco is connected with 4x 10G to the switch, Rhino and Hippo are connected with 2x 100G to the switch and I have a Dell connected as well with 2x 10G to the switch (this can be very useful to take a look at what’s going on on the wire). The switch is an FS S5860-48SC (with 48x10G SFP+ ports, and 8x100G QSFP ports), which is a piece of kit that I highly recommend by the way.
Its configuration:
interface TenGigabitEthernet 0/1
description Infra: Dell R720xd hvn0:enp5s0f0
no switchport
mtu 9216
!
interface TenGigabitEthernet 0/2
description Infra: Dell R720xd hvn0:enp5s0f1
no switchport
mtu 9216
!
interface TenGigabitEthernet 0/7
description Cust: Fridge Te0/2/0/0
mtu 9216
switchport access vlan 20
!
interface TenGigabitEthernet 0/9
description Cust: Fridge Te0/1/0/0
mtu 9216
switchport access vlan 10
!
interface HundredGigabitEthernet 0/53
description Cust: Rhino HundredGigabitEthernet15/0/1
mtu 9216
switchport access vlan 10
!
interface HundredGigabitEthernet 0/54
description Cust: Rhino HundredGigabitEthernet15/0/0
mtu 9216
switchport access vlan 20
!
monitor session 1 destination interface TenGigabitEthernet 0/1
monitor session 1 source vlan 10 rx
monitor session 2 destination interface TenGigabitEthernet 0/2
monitor session 2 source vlan 20 rx
What this does is connect Rhino’s Hu15/0/1 and Fridge’s Te0/1/0/0 in VLAN 10, and sends a readonly copy of all
traffic to the Dell’s enp5s0f0 interface. Similarly, Rhino’s Hu15/0/0 and Fridge’s Te0/2/0/0 in VLAN 20 with a copy
of traffic to the Dell’s enp5s0f1 interface. I can now run tcpdump on the Dell to see what’s going back and forth.
In case you’re curious: the monitor on Te0/1 and Te0/2 ports will saturate in case both machines are transmitting at
a combined rate of over 10Gbps. If this is the case, the traffic that doesn’t fit is simply dropped from the monitor
port, but it’s of course forwarded correctly between the original Hu0/53 and Te0/9 ports. In other words: the monitor
session has no performance penalty. It’s merely a convenience to be able to take a look on ports where tcpdump is
not easily available (ie. both VPP as well as the ASR9k in this case!)
Test 1.1: 10G L2 Cross Connect
A simple matter of virtually patching one interface into the other, I choose the first port on blade 1 and 2, and
tie them together in a p2p cross connect. In my VLAN Gymnastics post, I
called this a l2 xconnect, and although the configuration statements are a bit different, the purpose and expected
semantics are identical:
interface TenGigE0/1/0/0
l2transport
!
!
interface TenGigE0/2/0/0
l2transport
!
!
l2vpn
xconnect group loadtest
p2p xc01
interface TenGigE0/1/0/0
interface TenGigE0/2/0/0
!
!
The results of this loadtest look promising - although I can already see that the port will not sustain line rate at 64 byte packets, which I find somewhat surprising. Both when using multiple flows (ie. random source and destination IP addresses), as well as when using a single flow (repeating the same src/dst packet), the machine tops out at around 20 Mpps which is 68% of line rate (29.76 Mpps). Fascinating!
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 810 kpps | 9.94 Gbps | 1.61 Mpps | 19.77 Gbps |
| imix | 3.25 Mpps | 9.94 Gbps | 6.46 Mpps | 19.78 Gbps |
| 64b Multi | 14.66 Mpps | 9.86 Gbps | 20.3 Mpps | 13.64 Gbps |
| 64b Single | 14.28 Mpps | 9.60 Gbps | 20.3 Mpps | 13.62 Gbps |
Test 1.2: 10G L2 Bridge Domain
I then keep the two physical interfaces in l2transport mode, but change the type of l2vpn into a
bridge-domain, which I described in my VLAN Gymnastics post
as well. VPP and Cisco IOS/XR semantics look very similar indeed, they differ really only in the way
in which the configuration is expressed:
interface TenGigE0/1/0/0
l2transport
!
!
interface TenGigE0/2/0/0
l2transport
!
!
l2vpn
xconnect group loadtest
!
bridge group loadtest
bridge-domain bd01
interface TenGigE0/1/0/0
!
interface TenGigE0/2/0/0
!
!
!
!
Here, I find that performance in one direction is line rate, and with 64b packets ever so slightly better than the L2 crossconnect test above. In both directions though, the router struggles to obtain line rate in small packets, delivering 64% (or 19.0 Mpps) of the total offered 29.76 Mpps back to the loadtester.
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 807 kpps | 9.91 Gbps | 1.63 Mpps | 19.96 Gbps |
| imix | 3.24 Mpps | 9.92 Gbps | 6.47 Mpps | 19.81 Gbps |
| 64b Multi | 14.82 Mpps | 9.96 Gbps | 19.0 Mpps | 12.79 Gbps |
| 64b Single | 14.86 Mpps | 9.98 Gbps | 19.0 Mpps | 12.81 Gbps |
I would say that in practice, the performance of a bridge-domain is comparable to that of an L2XC.
Test 1.3: 10G L3 IPv4 Routing
This is the most straight forward test: the T-Rex loadtester in this case is sourcing traffic from 100.64.0.2 on its first interface, and 100.64.1.2 on its second interface. It will send ARP for the nexthop (100.64.0.1 and 100.64.1.1, the Cisco), but the Cisco will not maintain an ARP table for the loadtester, so I have to add static ARP entries for it. Otherwise, this is a simple test, which stress tests the IPv4 forwarding path:
interface TenGigE0/1/0/0
ipv4 address 100.64.0.1 255.255.255.252
!
interface TenGigE0/2/0/0
ipv4 address 100.64.1.1 255.255.255.252
!
router static
address-family ipv4 unicast
16.0.0.0/8 100.64.1.2
48.0.0.0/8 100.64.0.2
!
!
arp vrf default 100.64.0.2 043f.72c3.d048 ARPA
arp vrf default 100.64.1.2 043f.72c3.d049 ARPA
!
Alright, so the cracks definitely show on this loadtest. The performance of small routed packets is quite
poor, weighing in at 35% of line rate in the unidirectional test, and 43% in the bidirectional test. It seems
that the ASR9k (at least in this hardware profile of l3xl) is not happy forwarding traffic at line rate,
and the routing performance is indeed significantly lower than the L2VPN performance. That’s good to know!
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 815 kpps | 10.0 Gbps | 1.63 Mpps | 19.98 Gbps |
| imix | 3.27 Mpps | 9.99 Gbps | 6.52 Mpps | 19.96 Gbps |
| 64b Multi | 5.14 Mpps | 3.45 Gbps | 12.3 Mpps | 8.28 Gbps |
| 64b Single | 5.25 Mpps | 3.53 Gbps | 12.6 Mpps | 8.51 Gbps |
Test 2 - LACP 2x 20G
Link aggregation (ref) means combining or aggregating multiple network connections in parallel by any of several methods, in order to increase throughput beyond what a single connection could sustain, to provide redundancy in case one of the links should fail, or both. A link aggregation group (LAG) is the combined collection of physical ports. Other umbrella terms used to describe the concept include trunking, bundling, bonding, channeling or teaming. Bundling ports together on a Cisco IOS/XR platform like the ASR9k can be done by creating a Bundle-Ether or BE. For reference, the same concept on VPP is called a BondEthernet and in Linux it’ll often be referred to as simply a bond. They all refer to the same concept.
One thing that immediately comes to mind when thinking about LAGs is: how will the member port be selected on outgoing traffic? A sensible approach will be to either hash on the L2 source and/or destination (ie. the ethernet host on either side of the LAG), but in the case of a router and as is the case in our loadtest here, there is only one MAC address on either side of the LAG. So a different hashing algorithm has to be chosen, preferably of the source and/or destination L3 (IPv4 or IPv6) address. Luckily, both the FS switch as well as the Cisco ASR9006 support this.
First I’ll reconfigure the switch, and then reconfigure the router to use the newly created 2x 20G LAG ports.
interface TenGigabitEthernet 0/7
description Cust: Fridge Te0/2/0/0
port-group 2 mode active
!
interface TenGigabitEthernet 0/8
description Cust: Fridge Te0/2/0/1
port-group 2 mode active
!
interface TenGigabitEthernet 0/9
description Cust: Fridge Te0/1/0/0
port-group 1 mode active
!
interface TenGigabitEthernet 0/10
description Cust: Fridge Te0/1/0/1
port-group 1 mode active
!
interface AggregatePort 1
mtu 9216
aggregateport load-balance dst-ip
switchport access vlan 10
!
interface AggregatePort 2
mtu 9216
aggregateport load-balance dst-ip
switchport access vlan 20
!
And after the Cisco is converted to use Bundle-Ether as well, the link status looks like this:
fsw0#show int ag1
...
Aggregate Port Informations:
Aggregate Number: 1
Name: "AggregatePort 1"
Members: (count=2)
Lower Limit: 1
TenGigabitEthernet 0/9 Link Status: Up Lacp Status: bndl
TenGigabitEthernet 0/10 Link Status: Up Lacp Status: bndl
Load Balance by: Destination IP
fsw0#show int usage up
Interface Bandwidth Average Usage Output Usage Input Usage
-------------------------------- ----------- ---------------- ---------------- ----------------
TenGigabitEthernet 0/1 10000 Mbit 0.0000018300% 0.0000013100% 0.0000023500%
TenGigabitEthernet 0/2 10000 Mbit 0.0000003450% 0.0000004700% 0.0000002200%
TenGigabitEthernet 0/7 10000 Mbit 0.0000012350% 0.0000022900% 0.0000001800%
TenGigabitEthernet 0/8 10000 Mbit 0.0000011450% 0.0000021800% 0.0000001100%
TenGigabitEthernet 0/9 10000 Mbit 0.0000011350% 0.0000022300% 0.0000000400%
TenGigabitEthernet 0/10 10000 Mbit 0.0000016700% 0.0000022500% 0.0000010900%
HundredGigabitEthernet 0/53 100000 Mbit 0.00000011900% 0.00000023800% 0.00000000000%
HundredGigabitEthernet 0/54 100000 Mbit 0.00000012500% 0.00000025000% 0.00000000000%
AggregatePort 1 20000 Mbit 0.0000014600% 0.0000023400% 0.0000005799%
AggregatePort 2 20000 Mbit 0.0000019575% 0.0000023950% 0.0000015200%
It’s clear that both AggregatePort interfaces have 20Gbps of capacity and are using an L3
loadbalancing policy. Cool beans!
If you recall my loadtest theory in for example my Netgate 6100 review, it can sometimes be useful to operate a single-flow loadtest, in which the source and destination IP:Port stay the same. As I’ll demonstrate, it’s not only relevant for PC based routers like ones built on VPP, it can also be very relevant in silicon vendors and high-end routers!
Test 2.1 - 2x 20G LAG L2 Cross Connect
I scratched my head a little while (and with a little while I mean more like an hour or so!), because usually
I come across Bundle-Ether interfaces which have hashing turned on in the interface stanza, but in my
first loadtest run I did not see any traffic on the second member port. I then found out that I need L2VPN
setting l2vpn load-balancing flow src-dst-ip applied rather than the Interface setting:
interface Bundle-Ether1
description LAG1
l2transport
!
!
interface TenGigE0/1/0/0
bundle id 1 mode active
!
interface TenGigE0/1/0/1
bundle id 1 mode active
!
interface Bundle-Ether2
description LAG2
l2transport
!
!
interface TenGigE0/2/0/0
bundle id 2 mode active
!
interface TenGigE0/2/0/1
bundle id 2 mode active
!
l2vpn
load-balancing flow src-dst-ip
xconnect group loadtest
p2p xc01
interface Bundle-Ether1
interface Bundle-Ether2
!
!
!
Overall, the router performs as well as can be expected. In the single-flow 64 byte test, however, due to the hashing over the available members in the LAG being on L3 information, the router is forced to always choose the same member and effectively perform at 10G throughput, so it’ll get a pass from me on the 64b single test. In the multi-flow test, I can see that it does indeed forward over both LAG members, however it reaches only 34.9Mpps which is 59% of line rate.
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 1.61 Mpps | 19.8 Gbps | 3.23 Mpps | 39.64 Gbps |
| imix | 6.40 Mpps | 19.8 Gbps | 12.8 Mpps | 39.53 Gbps |
| 64b Multi | 29.44 Mpps | 19.8 Gbps | 34.9 Mpps | 23.48 Gbps |
| 64b Single | 14.86 Mpps | 9.99 Gbps | 29.8 Mpps | 20.0 Gbps |
Test 2.2 - 2x 20G LAG Bridge Domain
Just like with Test 1.2 above, I can now transform this service from a Cross Connect into a fully formed
L2 bridge, by simply putting the two Bundle-Ether interfaces in a bridge-domain together, again
being careful to apply the L3 load-balancing policy on the l2vpn scope rather than the interface
scope:
l2vpn
load-balancing flow src-dst-ip
no xconnect group loadtest
bridge group loadtest
bridge-domain bd01
interface Bundle-Ether1
!
interface Bundle-Ether2
!
!
!
!
The results for this test show that indeed L2XC is computationally cheaper than bridge-domain work. With imix and 1514b packets, the router is fine and forwards 20G and 40G respectively. When the bridge is slammed with 64 byte packets, its performance reaches only 65% with multiple flows in the unidirectional, and 47% in the bidirectional loadtest. I found the performance difference with the L2 crossconnect above remarkable.
The single-flow loadtest cannot meaningfully stress both members of the LAG due to the src/dst being identical: the best I can expect here, is 10G performance regardless how many LAG members there are.
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 1.61 Mpps | 19.8 Gbps | 3.22 Mpps | 39.56 Gbps |
| imix | 6.39 Mpps | 19.8 Gbps | 12.8 Mpps | 39.58 Gbps |
| 64b Multi | 20.12 Mpps | 13.5 Gbps | 28.2 Mpps | 18.93 Gbps |
| 64b Single | 9.49 Mpps | 6.38 Gbps | 19.0 Mpps | 12.78 Gbps |
Test 2.3 - 2x 20G LAG L3 IPv4 Routing
And finally I turn my attention to the usual suspect: IPv4 routing. Here, I simply remove the l2vpn
stanza alltogether, and remember to put the load-balancing policy on the Bundle-Ether interfaces.
This ensures that upon transmission, both members of the LAG are used. That is, if and only if the
IP src/dst addresses differ, which is the case in most, but not all of my loadtests :-)
no l2vpn
interface Bundle-Ether1
description LAG1
ipv4 address 100.64.1.1 255.255.255.252
bundle load-balancing hash src-ip
!
interface TenGigE0/1/0/0
bundle id 1 mode active
!
interface TenGigE0/1/0/1
bundle id 1 mode active
!
interface Bundle-Ether2
description LAG2
ipv4 address 100.64.0.1 255.255.255.252
bundle load-balancing hash src-ip
!
interface TenGigE0/2/0/0
bundle id 2 mode active
!
interface TenGigE0/2/0/1
bundle id 2 mode active
!
The LAG is fine at forwarding IPv4 traffic in 1514b and imix - full line rate and 40Gbps of traffic is passed in the bidirectional test. With the 64b frames though, the forwarding performance is not line rate but rather 84% of line in one direction, and 76% of line rate in the bidirectional test.
And once again, the single-flow loadtest cannot make use of more than one member port in the LAG, so it will be constrained to 10G throughput – that said, it performs at 42.6% of line rate only.
| Loadtest | Unidirectional (pps) | L1 Unidirectional (bps) | Bidirectional (pps) | L1 Bidirectional (bps) |
|---|---|---|---|---|
| 1514b | 1.63 Mpps | 20.0 Gbps | 3.25 Mpps | 39.92 Gbps |
| imix | 6.51 Mpps | 19.9 Gbps | 13.04 Mpps | 39.91 Gbps |
| 64b Multi | 12.52 Mpps | 8.41 Gbps | 22.49 Mpps | 15.11 Gbps |
| 64b Single | 6.49 Mpps | 4.36 Gbps | 11.62 Mpps | 7.81 Gbps |
Bonus - ASR9k linear scaling

As I’ve shown above, the loadtests often topped out at well under line rate for tests with small packet sizes, but I can also see that the LAG tests offered a higher performance, although not quite double that of single ports. I can’t help but wonder: is this perhaps a per-port limit rather than a router-wide limit?
To answer this question, I decide to pull out the stops and populate the ASR9k with as many XFPs as I have in my stash, which is 9 pieces. One (Te0/0/0/0) still goes to uplink, because the machine should be carrying IGP and full BGP tables at all times; which leaves me with 8x 10G XFPs, which I decide it might be nice to combine all three scenarios in one test:
- Test 1.1 with Te0/1/0/2 cross connected to Te0/2/0/2, with a loadtest at 20Gbps.
- Test 1.2 with Te0/1/0/3 in a bridge-domain with Te0/2/0/3, also with a loadtest at 20Gbps.
- Test 2.3 with Te0/1/0/0+Te0/2/0/0 on one end, and Te0/1/0/1+Te0/2/0/1 on the other end, with an IPv4 loadtest at 40Gbps.
64 byte packets
It would be unfair to use single-flow on the LAG, considering the hashing is on L3 source and/or destination IPv4
addresses, so really only one member port would be used. To avoid this pitfall, I run with vm=var2. On the other
two tests, however, I do run the most stringent of traffic pattern with single-flow loadtests. So off I go, firing
up three T-Rex instances.
First, the 10G L2 Cross Connect test (approximately 17.7Mpps):
Tx bps L2 | 7.64 Gbps | 7.64 Gbps | 15.27 Gbps
Tx bps L1 | 10.02 Gbps | 10.02 Gbps | 20.05 Gbps
Tx pps | 14.92 Mpps | 14.92 Mpps | 29.83 Mpps
Line Util. | 100.24 % | 100.24 % |
--- | | |
Rx bps | 4.52 Gbps | 4.52 Gbps | 9.05 Gbps
Rx pps | 8.84 Mpps | 8.84 Mpps | 17.67 Mpps
Then, the 10G Bridge Domain test (approximately 17.0Mpps):
Tx bps L2 | 7.61 Gbps | 7.61 Gbps | 15.22 Gbps
Tx bps L1 | 9.99 Gbps | 9.99 Gbps | 19.97 Gbps
Tx pps | 14.86 Mpps | 14.86 Mpps | 29.72 Mpps
Line Util. | 99.87 % | 99.87 % |
--- | | |
Rx bps | 4.36 Gbps | 4.36 Gbps | 8.72 Gbps
Rx pps | 8.51 Mpps | 8.51 Mpps | 17.02 Mpps
Finally, the 20G LAG IPv4 forwarding test (approximately 24.4Mpps), noting that the Line Util. here is of the 100G loadtester ports, so 20% is expected:
Tx bps L2 | 15.22 Gbps | 15.23 Gbps | 30.45 Gbps
Tx bps L1 | 19.97 Gbps | 19.99 Gbps | 39.96 Gbps
Tx pps | 29.72 Mpps | 29.74 Mpps | 59.46 Mpps
Line Util. | 19.97 % | 19.99 % |
--- | | |
Rx bps | 5.68 Gbps | 6.82 Gbps | 12.51 Gbps
Rx pps | 11.1 Mpps | 13.33 Mpps | 24.43 Mpps
To summarize, in the above tests I am pumping 80Gbit (which is 8x 10Gbit full linerate at 64 byte packets, in other words 119Mpps) into the machine, and it’s returning 30.28Gbps (or 59.2Mpps which is 38%) of that traffic back to the loadtesters. Features: yes; linerate: nope!
256 byte packets
Seeing the lowest performance of the router coming in at 8.5Mpps (or 57% of linerate), it stands to reason that sending 256 byte packets will stay under the per-port observed packets/sec limits, so I decide to restart the loadtesters with 256b packets. The expected ethernet frame is now 256 + 20 byte overhead, or 2208 bits, of which ~4.53Mpps can fit into a 10G link. Immediately all ports go up entirely to full capacity. As seen from the Cisco’s commandline:
RP/0/RSP0/CPU0:fridge#show interfaces | utility egrep 'output.*packets/sec' | exclude 0 packets
Mon Feb 21 22:14:02.250 UTC
5 minute output rate 18390237000 bits/sec, 9075919 packets/sec
5 minute output rate 18391127000 bits/sec, 9056714 packets/sec
5 minute output rate 9278278000 bits/sec, 4547012 packets/sec
5 minute output rate 9242023000 bits/sec, 4528937 packets/sec
5 minute output rate 9287749000 bits/sec, 4563507 packets/sec
5 minute output rate 9273688000 bits/sec, 4537368 packets/sec
5 minute output rate 9237466000 bits/sec, 4519367 packets/sec
5 minute output rate 9289136000 bits/sec, 4562365 packets/sec
5 minute output rate 9290096000 bits/sec, 4554872 packets/sec
The first two ports there are Bundle-Ether interface BE1 and BE2, and the other eight are the TenGigE ports. You can see that each one is forwarding the expected 4.53Mpps, and this lines up perfectly with T-Rex which is sending 10Gbps of L1, and 9.28Gbps of L2 (the difference here is the ethernet overhead of 20 bytes per frame, or 4.53 * 160 bits = 724Mbps), and it’s receiving all of that traffic back on the other side, which is good.
This clearly demonstrates the hypothesis that the machine is per-port pps-bound.
So the conclusion is that, the A9K-RSP440-SE typically will forward maybe only 8Mpps on a single TenGigE port, and 13Mpps on a two-member LAG. However, it will do this for every port, and with at least 8x 10G ports saturated, it remained fully responsive, OSPF and iBGP adjacencies stayed up, and ping times on the regular (Te0/0/0/0) uplink port were smooth.
Results
1514b and imix: OK!
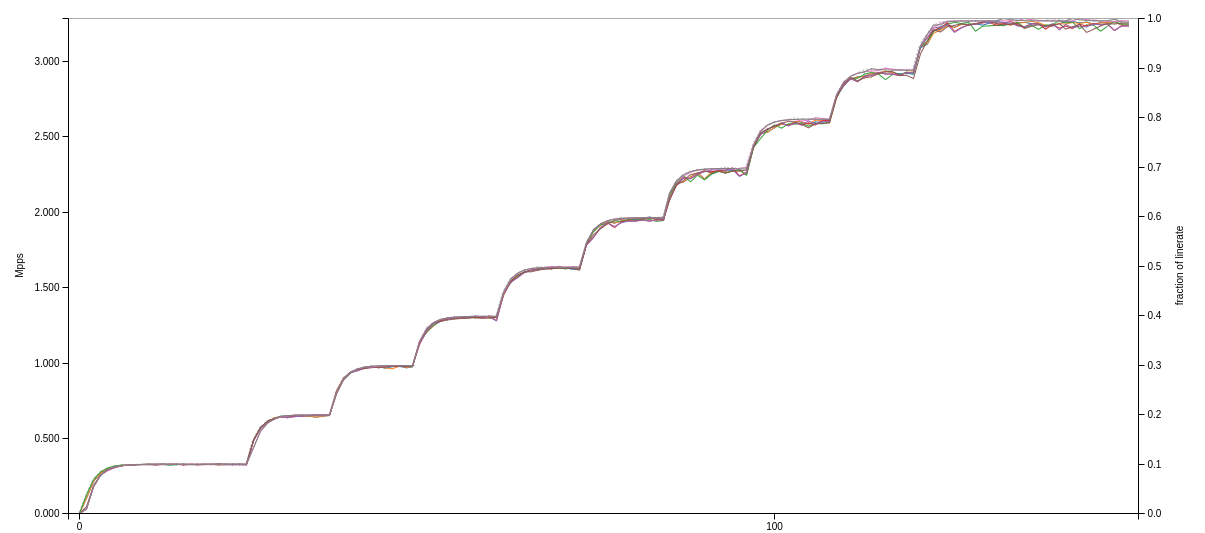
Let me start by showing a side-by-side comparison of the imix tests in all scenarios in the graph above. The graph for 1514b tests looks very similar, differing only in the left-Y axis: imix is a 3.2Mpps stream, while 1514b saturates the 10G port already at 810Kpps. But obviously, the router can do this just fine, even if used on 8 ports, it doesn’t mind at all. As I later learned, any traffic mix larger than than 256b packets, or 4.5Mpps per port, forwards fine in any configuration.
64b: Not so much :)
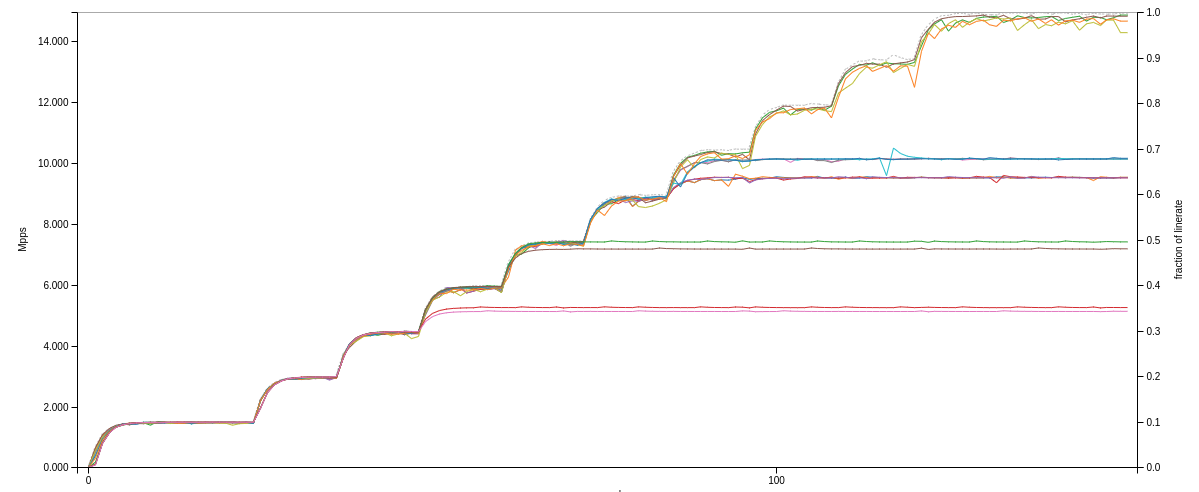
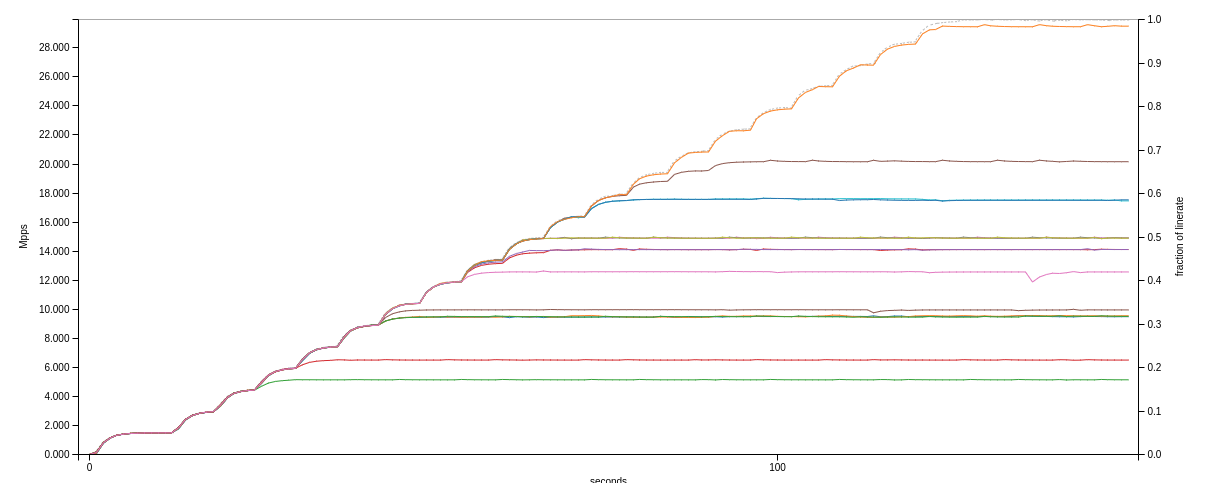
These graphs show the throughput of the ASR9006 with a pair of A9K-RSP440-SE route switch processors. They are rated at 440Gbps per slot, but their packets/sec rates are significantly lower than line rate. The top graph shows the tests with 10G ports, and the bottom graph shows the same tests but with a 2x10G ports in Bundle-Ether LAG.
In an ideal situation, each test would follow the loadtester up to completion, and there would be no horizontal lines breaking out partway through. As I showed, some of the loadtests really performed poorly in terms of packets/sec forwarded. Understandably, the 20G LAG with single-flow can only utilize one member port (which is logical) but then managed to push through only 6Mpps or so. Other tests did better, but overall I must say, the results were lower than I had expected.
That juxtaposition
At the very top of this article I alluded to what I think is a cool juxtaposition. On the one hand, we have these beasty ASR9k routers, running idle at 2.2kW for 24x10G and 40x1G ports (as is the case for the IP-Max router that I took out for a spin here). They are large (10U of rackspace), heavy (40kg loaded), expensive (who cares about list price, the street price is easily $10'000,- apiece).
On the other hand, we have these PC based machines with Vector Packet Processing, operating as low as 19W for 2x10G, 2x1G and 4x2.5G ports (like the Netgate 6100) and offering roughly equal performance per port, except having to drop only $700,- apiece. The VPP machines come with ~infinite RAM, even a 16GB machine will run much larger routing tables, including full BGP and so on - there is no (need for) TCAM, and yet routing performance scales out with CPUs and larger CPU instruction/data-cache. Looking at my Ryzen 5950X based Hippo/Rhino VPP machines, they can sustain line rate 64b packets on their 10G ports, due to each CPU being able to process around 22.3Mpps, and the machine has 15 usable CPU cores. Intel or Mellanox 100G network cards are affordable, the whole machine with 2x100G, 4x10G and 4x1G will set me back about $3'000,- in 1U and run 265 Watts when fully loaded.
See an extended rationale with backing data in my FOSDEM'22 talk.
Conclusion
I set out to answer three questions in this article, and I’m ready to opine now:
- Unidirectional vs Bidirectional: there is an impact - bidirectional tests (stressing both ingress and egress of each individual router port) have lower performance, notably in packets smaller than 256b.
- LACP performance penalty: there is an impact - 64b multiflow loadtest on LAG obtained 59%, 47% and 42% (for Test 2.1-3) while for single ports, they obtained 68%, 64% and 43% (for Test 1.1-3). So while aggregate throughput grows with the LACP Bundle-Ether ports, individual port throughput is reduced.
- The router performs line rate 1514b, imix, and anything beyond 256b packets really. However, it does not sustain line rate at 64b packets. Some tests passed with a unidirectional loadtest, but all tests failed with bidirectional loadtests.
After all of these tests, I have to say I am still a huge fan of the ASR9k. I had kind of expected that it would perform at line rate for any/all of my tests, but the theme became clear after a few - the ports will only forward between 8Mpps and 11Mpps (out of the needed 14.88Mpps), but every port will do that, which means the machine will still scale up significantly in practice. But for business internet, colocation, and non-residential purposes, I would argue that routing stability is most important, and with regards to performance, I would argue that aggregate bandwidth is more important than pure packets/sec performance. Finally, the ASR in Cisco ASR9k stands for Advanced Services Router, and being able to mix-and-match MPLS, L2VPN, Bridges, encapsulation, tunneling, and have an expectation of 8-10Mpps per 10G port is absolutely reasonable. The ASR9k is a very competent machine.
Loadtest data
I’ve dropped all loadtest data here and if you’d like to play around with the data, take a look at the HTML files in this directory, they were built with Michal’s trex-loadtest-viz scripts.
Acknowledgements
I wanted to give a shout-out to Fred and the crew at IP-Max for allowing me to play with their router during these loadtests. I’ll be configuring it to replace their router at NTT in March, so if you have a connection to SwissIX via IP-Max, you will be notified for maintenance ahead of time as we plan the maintenance window.
We call these things Fridges in the IP-Max world, because they emit so much cool air when they start :) The ASR9001 is the microfridge, this ASR9006 is the minifridge, and the ASR9010 is the regular fridge.