About this series
I have seen companies achieve great successes in the space of consumer internet and entertainment industry. I’ve been feeling less enthusiastic about the stronghold that these corporations have over my digital presence. I am the first to admit that using “free” services is convenient, but these companies are sometimes taking away my autonomy and exerting control over society. To each their own of course, but for me it’s time to take back a little bit of responsibility for my online social presence, away from centrally hosted services and to privately operated ones.
In my [first post], I shared some thoughts on how I installed a Mastodon instance for myself. In a [followup post] I talked about its overall architecture and how one might use Prometheus to monitor vital backends like Redis, Postgres and Elastic. But Mastodon itself is also an application which can provide a wealth of telemetry using a protocol called [StatsD].
In this post, I’ll show how I tie these all together in a custom Grafana Mastodon dashboard!
Mastodon Statistics
I noticed in the [Mastodon docs], that there’s a one-liner breadcrumb that might be easy to overlook, as it doesn’t give many details:
STATSD_ADDR: If set, Mastodon will log some events and metrics into a StatsD instance identified by its hostname and port.
Interesting, but what is this statsd, precisely? It’s a simple text-only protocol that allows applications to send key-value pairs in
the form of <metricname>:<value>|<type> strings, that carry statistics of certain type across the network, using either TCP or UDP.
Cool! To make use of these stats, I first add this STATSD_ADDR environment variable from the docs to my .env.production file, pointing
it at localhost:9125. This should make Mastodon apps emit some statistics of sorts.
I decide to a look at those packets, instructing tcpdump to show the contents of the packets (using the -A flag). Considering my
destination is localhost, I also know which interface to tcpdump on (using the -i lo flag). My first attempt is a little bit noisy,
because the packet dump contains the [IPv4 header] (20 bytes) and [UDP
header] (8 bytes) as well, but sure enough, if I start reading from the 28th byte
onwards, I get human-readable data, in a bunch of strings that start with Mastodon:
pim@ublog:~$ sudo tcpdump -Ani lo port 9125 | grep 'Mastodon.production.' | sed -e 's,.*Mas,Mas,'
Mastodon.production.sidekiq.ActivityPub..ProcessingWorker.processing_time:16272|ms
Mastodon.production.sidekiq.ActivityPub..ProcessingWorker.success:1|c
Mastodon.production.sidekiq.scheduled_size:25|g
Mastodon.production.db.tables.accounts.queries.select.duration:1.8323479999999999|ms
Mastodon.production.web.ActivityPub.InboxesController.create.json.total_duration:33.856679|ms
Mastodon.production.web.ActivityPub.InboxesController.create.json.db_time:2.3943890118971467|ms
Mastodon.production.web.ActivityPub.InboxesController.create.json.view_time:1|ms
Mastodon.production.web.ActivityPub.InboxesController.create.json.status.202:1|c
...
statsd organizes its variable names in a dot-delimited tree hierarchy. I can clearly see some patterns in here, but why guess when you’re working with Open Source? Mastodon turns out to be using a popular Ruby library called the [National Statsd Agency], a wordplay that I don’t necessarily find all that funny. Naming aside though, this library collects application level statistics in four main categories:
- :action_controller: listens to the ActionController class that is extended into ApplicationControllers in Mastodon
- :active_record: listens to any database (SQL) queries and emits timing information for them
- :active_support_cache: records information regarding caching (Redis) queries, and emits timing information for them
- :sidekiq: listens to Sidekiq middleware and emits information about queues, workers and their jobs
Using the library’s [docs], I can clearly see the patterns described, for example in the SQL
recorder, the format will be {ns}.{prefix}.tables.{table_name}.queries.{operation}.duration where operation here means one of the
classic SQL query types, SELECT, INSERT, UPDATE, and DELETE. Similarly, in the cache recorder, the format will be
{ns}.{prefix}.{operation}.duration where operation denotes one of read_hit, read_miss, generate, delete, and so on.
Reading a bit more of the Mastodon and statsd library code, I learn that all variables emitted, the namespace {ns} is always a
combination of the application name and Ruby Rails environment, ie. Mastodon.production, and the {prefix} is the collector name,
one-of web, db, cache or sidekiq. If you’re curious, the Mastodon code that initializes the statsd collectors lives
in config/initializers/statsd.rb. Alright, I conclude that this is all I need to know about the naming schema.
Moving along, statsd gives each variable name a [metric type], which can be counters c, timers ms and gauges g. In the packet dump above you can see examples of each of these. The counter type in particular is a little bit different – applications emit increments here - in the case of the ActivityPub.InboxesController, it merely signaled to increment the counter by 1, not the absolute value of the counter. This is actually pretty smart, because now any number of workers/servers can all contribute to a global counter, by each just sending incrementals which are aggregated by the receiver.
As a small critique, I happened to notice that in the sidekiq datastream, some of what I think are counters are actually modeled as gauges (notably the processed and failed jobs from the workers). I will have to remember that, but after observing for a few minutes, I think I can see lots of nifty data in here.
Prometheus
At IPng Networks, we use Prometheus as a monitoring observability tool. It’s worth pointing out that statsd has a few options itself to
visualise data, but considering I already have lots of telemetry in Prometheus and Grafana (see my [previous post]), I’m going to take a bit of a detour, and convert these metrics into the Prometheus exposition format, so that
they can be scraped on a /metrics endpoint just like the others. This way, I have all monitoring in one place and using one tool.
Monitoring is hard enough as it is, and having to learn multiple tools is no bueno :)
Statsd Exporter: overview
The community maintains a Prometheus [Statsd Exporter] on GitHub. This tool, like many others in the exporter family, will connect to a local source of telemetry, and convert these into the required format for consumption by Prometheus. If left completely unconfigured, it will simply receive the statsd UDP packets on the Mastodon side, and export them verbatim on the Prometheus side. This will have a few downsides, notably when new operations or controllers come into existence, I would have to explicitly make Prometheus aware of them.
I think we can do better, specifically because of the patterns noted above, I can condense the many metricnames from statsd into a few carefully chosen Prometheus metrics, and add their variability into labels in those time series. Taking SQL queries as an example, I see that there’s a metricname for each known SQL table in Mastodon (and there are many) and then for each table, a unique metric is created for each of the four operations:
Mastodon.production.tables.{table_name}.queries.select.duration
Mastodon.production.tables.{table_name}.queries.insert.duration
Mastodon.production.tables.{table_name}.queries.update.duration
Mastodon.production.tables.{table_name}.queries.delete.duration
What if I could rewrite these by capturing the {table_name} label, and further observing that there are four query types (SELECT, INSERT,
UPDATE, DELETE), so possibly capturing those into a {operation} label, like so:
mastodon_db_operation_sum{operation="select",table="users"} 85.910
mastodon_db_operation_sum{operation="insert",table="accounts"} 112.70
mastodon_db_operation_sum{operation="update",table="web_push_subscriptions"} 6.55
mastodon_db_operation_sum{operation="delete",table="web_settings"} 9.668
mastodon_db_operation_count{operation="select",table="users"} 28790
mastodon_db_operation_count{operation="insert",table="accounts"} 610
mastodon_db_operation_count{operation="update",table="web_push_subscriptions"} 380
mastodon_db_operation_count{operation="delete",table="web_settings"} 4)
This way, there are only two Prometheus metric names mastodon_db_operation_sum and mastodon_db_operation_count. The first one counts the cumulative time spent performing operations of that type on the table, and the second one counts the total amount of queries of that type on the table. If I take the rate() of the count variable, I will have queries-per-second, and if I divide the rate() of the time spent by the rate() of the count, I will have a running average time spent per query over that time interval.
Statsd Exporter: configuration
The Prometheus folks also thought of this, quelle surprise, and the exporter provides incredibly powerful transformation functionality between the hierarchical tree-form of statsd and the multi-dimensional labeling format of Prometheus. This is called the [Mapping Configuration], and it allows either globbing or regular expression matching of the input metricnames, turning them into labeled output metrics. Building further on our example for SQL queries, I can create a mapping like so:
pim@ublog:~$ cat << EOF | sudo tee /etc/prometheus/statsd-mapping.yaml
mappings:
- match: Mastodon\.production\.db\.tables\.(.+)\.queries\.(.+)\.duration
match_type: regex
name: "mastodon_db_operation"
labels:
table: "$1"
operation: "$2"
This snippet will use a regular expression to match input metricnames, carefully escaping the dot-delimiters. Within the input, I will match
two groups, the segment following tables. holds the variable SQL Table name and the segment following queries. captures the SQL Operation.
Once this matches, the exporter will give the resulting variable in Prometheus simply the name mastodon_db_operation and add two labels
with the results of the regexp capture groups.
This one mapping I showed above will take care of all of the metrics from the database collector, but are three other collectors in Mastodon’s Ruby world. In the interest of brevity, I’ll not bore you with them in this article, as this is mostly a rinse-and-repeat jobbie. But I have attached a copy of the complete mapping configuration at the end of this article. With all of that hard work on mapping completed, I can now start the statsd exporter and see its beautifully formed and labeled timeseries show up on port 9102, the default [assigned port] for this exporter type.
Grafana
First let me start by saying I’m incredibly grateful to all the folks who have contributed to existing exporters and Grafana dashboards, notably for [Node Exporter], [Postgres Exporter], [Redis Exporter], [NGINX Exporter], and [ElasticSearch Exporter]. I’m ready to make a modest contribution back to this wonderful community of monitoring dashboards, in the form of a Grafana dashboard for Mastodon!
Writing these is pretty rewarding. I’ll take some time to explain a few Grafana concepts, although this is not meant to be a tutorial at all and honestly, I’m not that good at this anyway. A good dashboard design goes from a 30'000ft overview of the most vital stats (not necessarily graphs, but using visual clues like colors), and gives more information in so-called drill-down dashboards that allow a much finer grained / higher resolution picture of a specific part of the monitored application.
Seeing as the collectors are emitting four main parts of the application (remember, the {prefix} is one of web, db, cache, or
sidekiq), so I will give the dashboard the same structure. Also, I will try my best not to invent new terminology, as the application
developers have given their telemetry certain names, I will stick to these as well. Building a dashboard this way, application developers as
well as application operators will more likely be talking about the same things.
Mastodon Overview
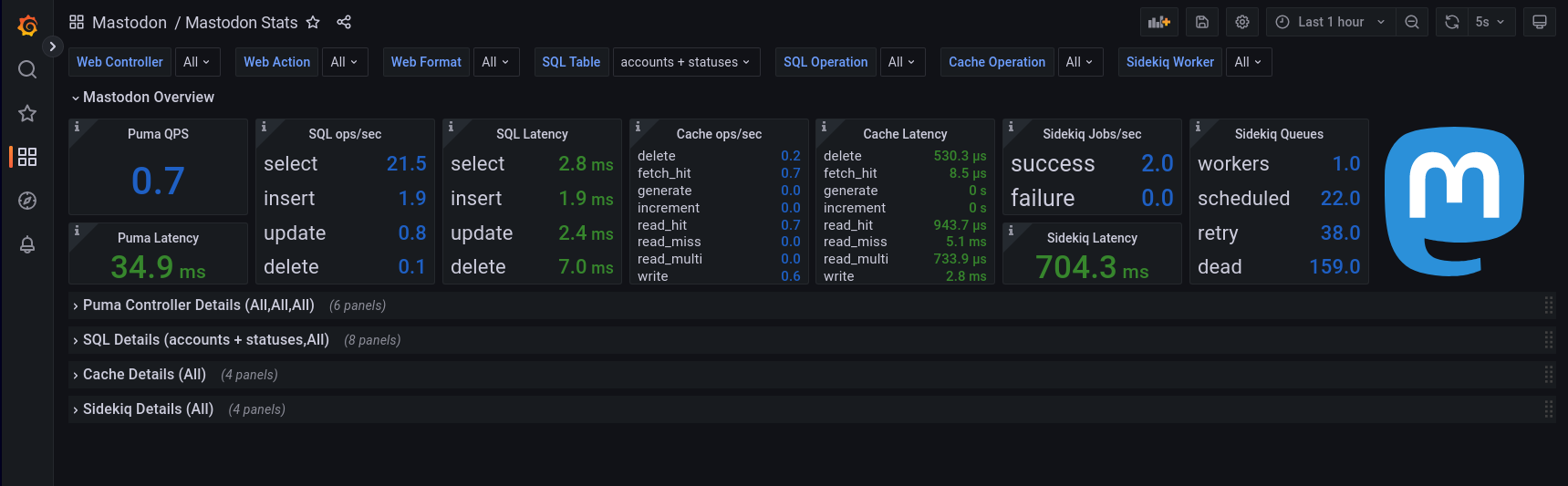
In the Mastodon Overview, each of the four collectors gets one or two stats-chips to present their highest level vitalsigns on. For a web application, this will largely be requests per second, latency and possibly errors served. For a SQL database, this is typically the issued queries and their latency. For a cache, the types of operation and again the latency observed in those operations. For Sidekiq (the background worker pool that performs certain tasks in a queue on behalf of the system or user), I decide to focus on units of work, latency and queue sizes.
Setting up the Prometheus queries in Grafana that fetch the data I need for these is typically going to be one of two things:
QPS: This is a rate of the monotonic increasing _count, over say one minute, I will see the average queries-per-second. Considering the counters I created have labels that tell me what they are counting (for example in Puma, which API endpoint is being queried, and what format that request is using), I can now elegantly aggregate those application-wide, like so:
sum by (mastodon)(rate(mastodon_controller_duration_count[1m]))
Latency: The metrics in Prometheus aggregate a runtime monotonic increasing _sum which tells me about the total time spent doing those things. It’s pretty easy to calculate the running average latency over the last minute, by simply dividing the rate of time spent by the rate of requests served, like so:
sum by (mastodon)(rate(mastodon_controller_duration_sum[1m])) / sum by (mastodon)(rate(mastodon_controller_duration_count[1m]))
To avoid clutter, I will leave the detailed full resolution view (like which controller exactly, and what format was queried, and which action was taken in the API) to a drilldown below. These two patterns are continud throughout the overview panel. Each QPS value is rendered in dark blue, while the latency gets a special treatment on colors: I define a threshold which I consider “unacceptable”, and then create a few thresholds in Grafana to change the color as I approach that unacceptable max limit. By means of example, the Puma Latency element I described above, will have a maximum acceptable latency of 250ms. If the latency is above 40% of that, the color will turn yellow; above 60% it’ll turn orange and above 80% it’ll turn red. This provides a visual queue that something may be wrong.
Puma Controllers
The APIs that Mastodon offers are served by a component called [Puma], a simple, fast, multi-threaded, and highly parallel HTTP 1.1 server for Ruby/Rack applications. The application running in Puma typically defines endpoints as so-called ActionControllers, which Mastodon expands on in a derived concept called ApplicationControllers which each have a unique controller name (for example ActivityPub.InboxesController), an action performed on them (for example create, show or destroy), and a format in which the data is handled (for example html or json). For each cardinal combination, a set of timeseries (counter, time spent and latency quantiles) will exist. At the moment, there are about 53 API controllers, 8 actions, and 4 formats, which means there are 1'696 interesting metrics to inspect.
Drawing all of these in one graph quickly turns into an unmanageable mess, but there’s a neat trick in Grafana: what if I could make these variables selectable, and maybe pin them to exactly one value (for example, all information with a specific controller), that would greatly reduce the amount of data we have to show. To implement this, the dashboard can pre-populate a variable based on a Prometheus query. By means of example, to find the possible values of controller, I might take a look at all Prometheus metrics with name mastodon_controller_duration_count and search for labels within them with a regular expression, for example /controller="([^"]+)"/.
What this will do is select all values in the group "([^"]+)" which may seem a little bit cryptic at first. The logic behind it is first
create a group between parenthesis (...) and then within that group match a set of characters [...] where the set is all characters
except the double-quote [^"] and that is repeated one-or-more times with the + suffix. So this will precisely select the string between
the double-quotes in the label: controller="whatever" will return whatever with this expression.
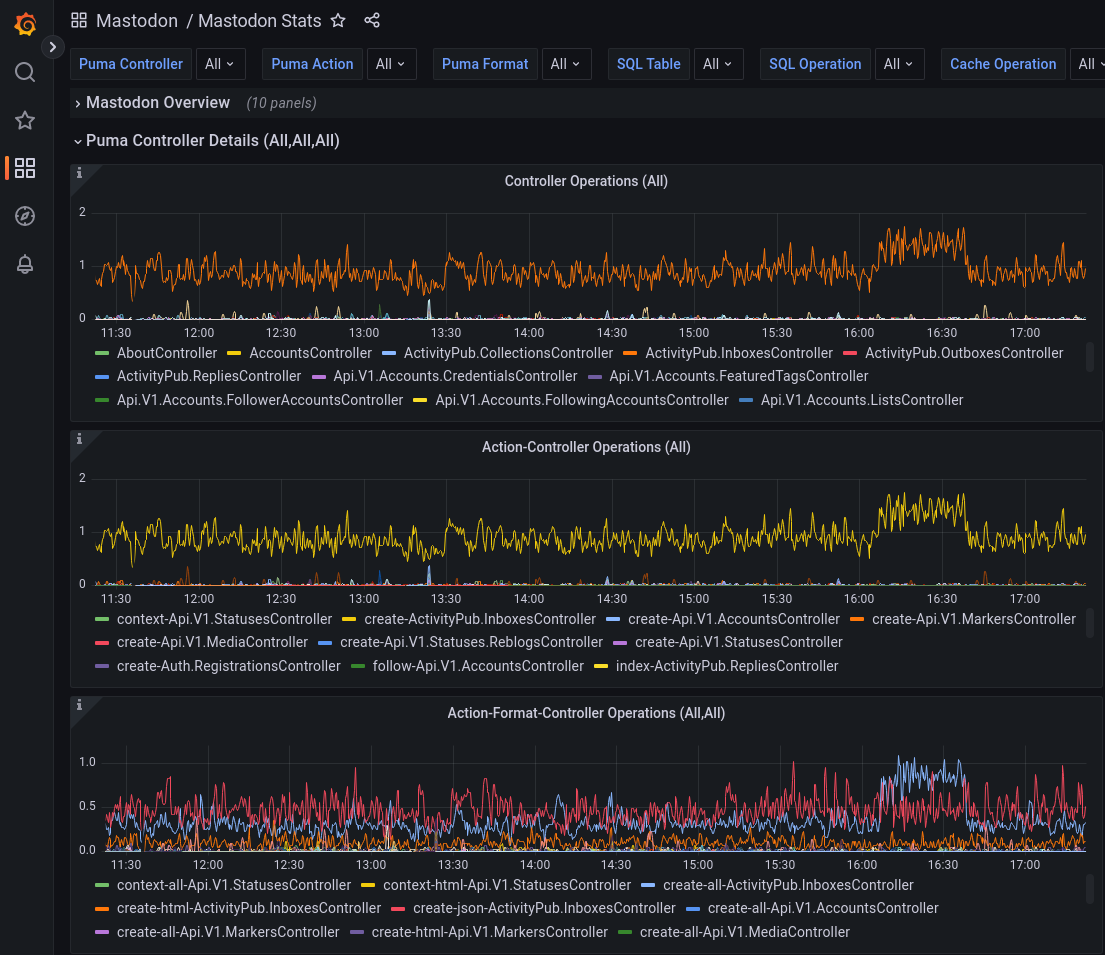
After creating three of these, one for controller, action and format, three new dropdown selectors appear at the top of my dashboard. I will allow any combination of selections, including “All” of them (the default). Then, if I wish to drill down, I can pin one or more of these variables to narrow down the total amount of timeseries to draw.
Shown to the right are two examples, one with “All” timeseries in the graph, which shows at least which one(s) are outliers. In this case, the orange trace in the top graph showing more than average operations is the so-called ActivityPub.InboxesController.
I can find this out by hovering over the orange trace, the tooltip will show me the current name and value. Then, selecting this in the top navigation dropdown Puma Controller, Grafana will narrow down the data for me to only those relevant to this controller, which is super cool.
Drilldown in Grafana
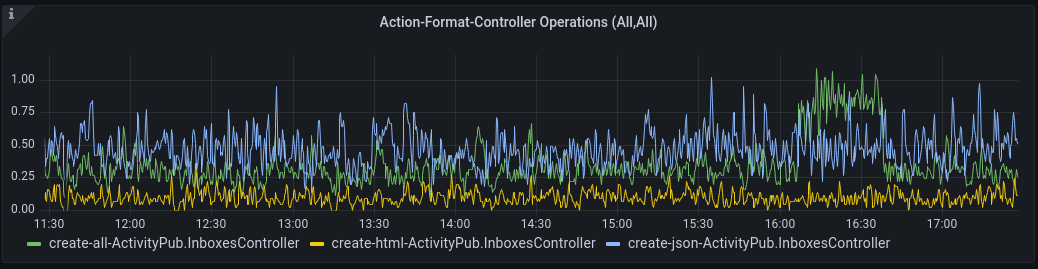
Where the graph down below (called Action Format Controller Operations) showed all 1'600 or so timeseries, selecting the one controller I’m interested in, shows me a much cleaner graph with only three timeseries, take a look to the right. Just by playing around with this data, I’m learning a lot about the architecture of this application!
For example, I know that the only action on this particular controller seems to be create, and there are three available formats in which
this create action can be performed: all, html and json. And using the graph above that got me started on this little journey, I now
know that the traffic spike was for controller=ActivityPub.InboxesController, action=create, format=all. Dope!
SQL Details
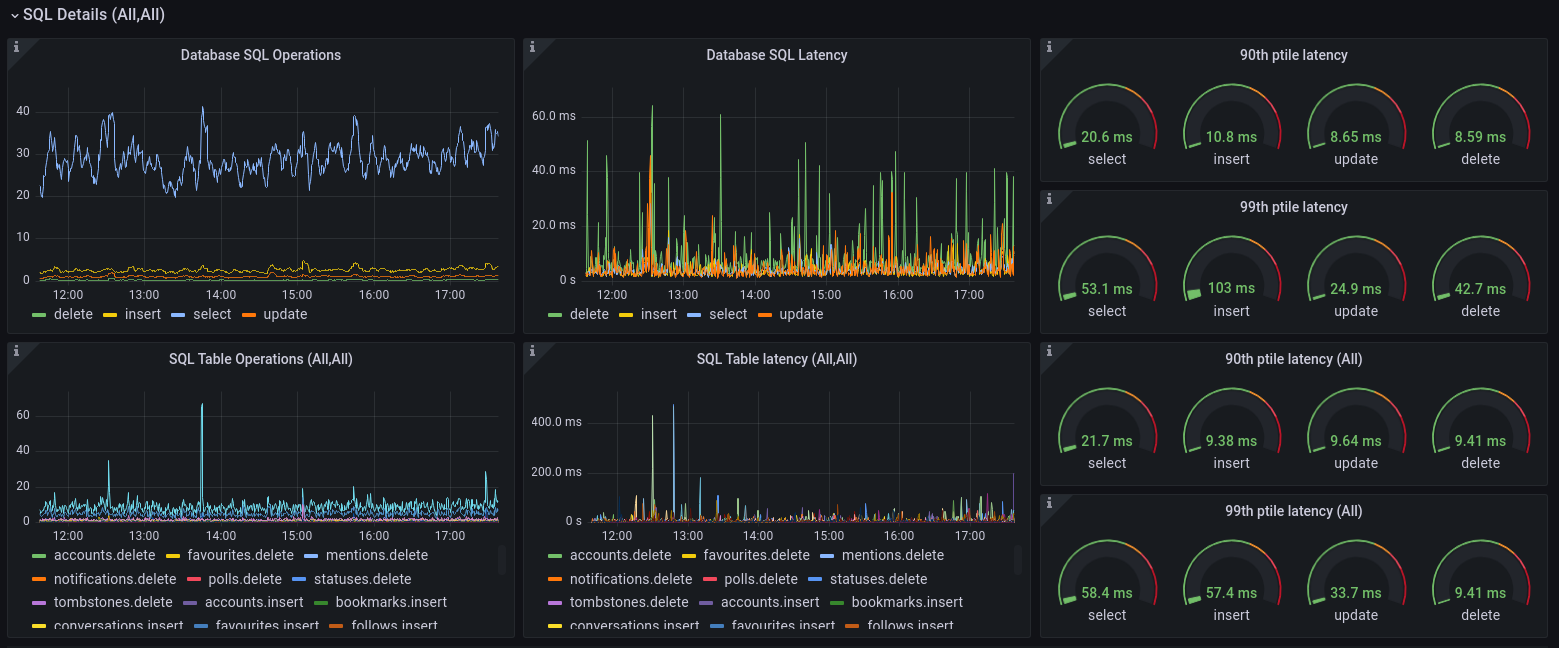
While I already have a really great [Postgres Dashboard] (the one that
came with Postgres server), it is also good to be able to see what the client is experiencing. Here, we can drill down on two variables,
called $sql_table and $sql_operation. For each {table,operation}-tuple, the average, median and 90th/99th percentile latency are
available. So I end up with the following graphs and dials for tail latency: the top left graph shows me something interesting – most
queries are SELECT, but the bottom graph shows me lots of tables (at the time of this article, Mastodon has 73 unique SQL tables). If I
wanted to answer the question “which table gets most SELECTs”, I can drill down first by selecting the SQL Operation to be select,
after which I see decidedly less traces in the SQL Table Operations graph. Further analysis shows that the two places that are mostly read
from are the tables called statuses and accounts. When I drill down using the selectors at the top of Grafana’s dashboard UI, the tail
latency is automatically filtered to only that which is selected. If I were to see very slow queries at some point in the future, it’ll be
very easy to narrow down exactly which table and which operation is the culprit.
Cache Details
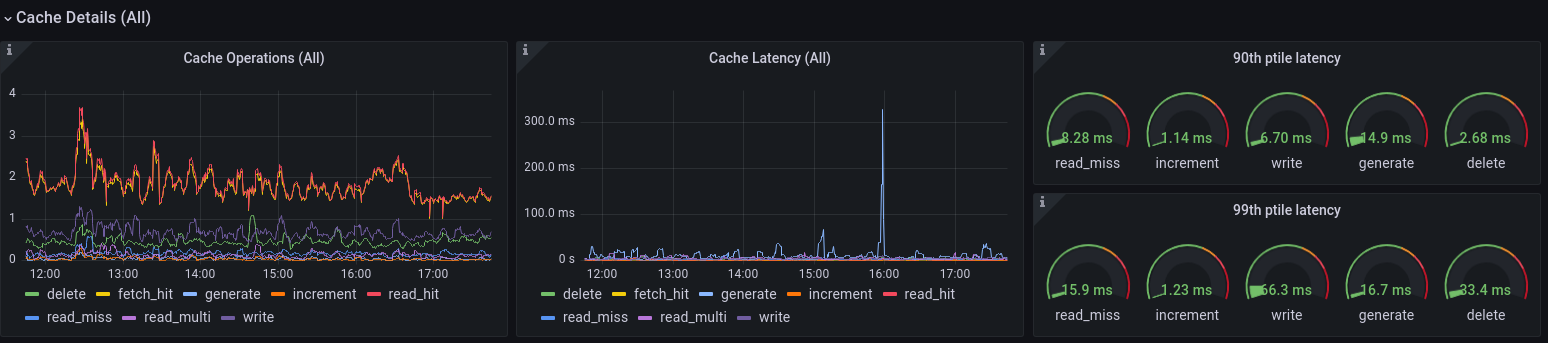
For the cache statistics collector, I learn there are a few different operators. Similar to Postgres, I already have a really cool [Redis Dashboard], for which I can see the Redis server view. But in Mastodon, I can now also see the client view, and see when any of these operations spike in either queries/sec (left graph), latency (middle graph), or tail latency for common operations (the dials on the right). This is bound to come in handy at some point – I already saw one or two spikes in the generate operation (see the blue spike in the screenshot above), which is something to keep an eye on.
Sidekiq Details
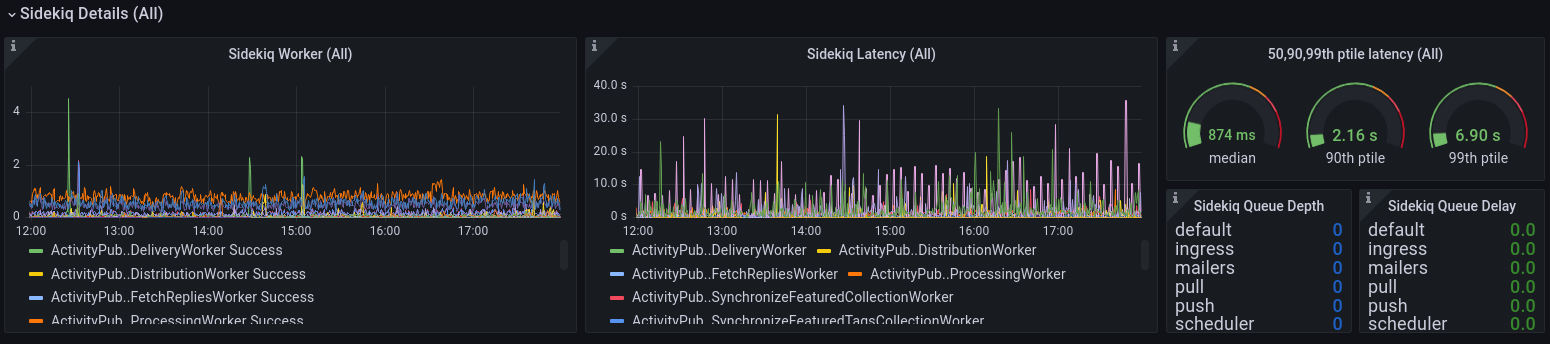
The single most interesting thing in the Mastodon application is undoubtedly its Sidekiq workers, the ones that do all sorts of system- and user-triggered work such as distributing the posts to federated servers, prefetch links and media, and calculate trending tags, posts and links. Sidekiq is a [producer-consumer] system where new units of work (called jobs) are written to a queue in Redis by a producer (typically Mastodon’s webserver Puma, or another Sidekiq task that needs something to happen at some point in the future), and then consumed by one or more pools which execute the worker jobs.
There are several queues defined in Mastodon, and each worker has a name, a failure and success rate, and a running tally of how much processing_time they’ve spent executing this type of work. Sidekiq workers will consume jobs in [FIFO] order, and it has a finite amount of workers (by default on a small instance it runs one worker with 25 threads). If you’re interested in this type of provisioning, [Nora Tindall] wrote a great article about it.
This drill-down dashboard shows all of the Sidekiq worker types known to Prometheus, and can be selected at the top of the dashboard in the dropdown called Sidekiq Worker. A total amount of worker jobs/second, as well as the running average time spent performing those jobs is shown in the first two graphs. The three dials show the median, 90th percentile and 99th percentile latency of the work being performed.
If all threads are busy, new work is left in the queue, until a worker thread is available to execute the job. This will lead to a queue delay on a busy server that is underprovisioned. For jobs that had to wait for an available thread to pick them up, the number of jobs per queue, and the time in seconds that the jobs were waiting to be picked up by a worker, are shown in the two lists at bottom right.
And with that, as [North of the Border] would say: “We’re on to the glamour shots!”.
What’s next
I made a promise on two references that will be needed to successfully hook up Prometheus and Grafana to the STATSD_ADDR configuration for
Mastodon’s Rails environment, and here they are:
- The Statsd Exporter mapping configuration file: [/etc/prometheus/statsd-mapping.yaml]
- The Grafana Dashboard: [grafana.com/dashboards/]
As a call to action: if you are running a larger instance and would allow me to take a look and learn from you, I’d be very grateful.
I’m going to monitor my own instance for a little while, so that I can start to get a feeling for where the edges of performance cliffs are, in other words: How slow is too slow? How much load is too much? In an upcoming post, I will take a closer look at alerting in Prometheus, so that I can catch these performance cliffs and make human operators aware of them by means of alerts, delivered via Telegram or Slack.
By the way: If you’re looking for a home, feel free to sign up at https://ublog.tech/ as I’m sure that having a bit more load / traffic on this instance will allow me to learn (and in turn, to share with others)!