
About this series
Ever since I first saw VPP - the Vector Packet Processor - I have been deeply impressed with its performance and versatility. For those of us who have used Cisco IOS/XR devices, like the classic ASR (aggregation service router), VPP will look and feel quite familiar as many of the approaches are shared between the two.
I’ve deployed an MPLS core for IPng Networks, which allows me to provide L2VPN services, and at the same time keep an IPng Site Local network with IPv4 and IPv6 that is separate from the internet, based on hardware/silicon based forwarding at line rate and high availability. You can read all about my Centec MPLS shenanigans in [this article].
In the last article, I explored VPP’s MPLS implementation a little bit. All the while, @vifino has been tinkering with the Linux Control Plane and adding MPLS support to it, and together we learned a lot about how VPP does MPLS forwarding and how it sometimes differs to other implementations. During the process, we talked a bit about implicit-null and explicit-null. When my buddy Fred read the [previous article], he also talked about a feature called penultimate-hop-popping which maybe deserves a bit more explanation. At the same time, I could not help but wonder what the performance is of VPP as a P-Router and PE-Router, compared to say IPv4 forwarding.
Lab Setup: VMs

For this article, I’m going to boot up instance LAB1 with no changes (for posterity, using image
vpp-proto-disk0@20230403-release), and it will be in the same state it was at the end of my
previous [MPLS article]. To recap, there are four routers
daisychained in a string, and they are called vpp1-0 through vpp1-3. I’ve then connected a
Debian virtual machine on both sides of the string. host1-0.enp16s0f3 connects to vpp1-3.e2
and host1-1.enp16s0f0 connects to vpp1-0.e3. Finally, recall that all of the links between these
routers and hosts can be inspected with the machine tap1-0 which is connected to a mirror port on
the underlying Open vSwitch fabric. I bound some RFC1918 addresses on host1-0 and host1-1 and
can ping between the machines, using the VPP routers as MPLS transport.
MPLS: Simple LSP
In this mode, I can plumb two label switched paths (LSPs), the first one westbound from vpp1-3
to vpp1-0, and it wraps the packet destined to 10.0.1.1 into an MPLS packet with a single label
100:
vpp1-3# ip route add 10.0.1.1/32 via 192.168.11.10 GigabitEthernet10/0/0 out-labels 100
vpp1-2# mpls local-label add 100 eos via 192.168.11.8 GigabitEthernet10/0/0 out-labels 100
vpp1-1# mpls local-label add 100 eos via 192.168.11.6 GigabitEthernet10/0/0 out-labels 100
vpp1-0# mpls local-label add 100 eos via ip4-lookup-in-table 0
vpp1-0# ip route add 10.0.1.1/32 via 192.0.2.2
The second is eastbound from vpp1-0 to vpp1-3, and it is using MPLS label 103. Remember:
LSPs are unidirectional!
vpp1-0# ip route add 10.0.1.0/32 via 192.168.11.7 GigabitEthernet10/0/1 out-labels 103
vpp1-1# mpls local-label add 103 eos via 192.168.11.9 GigabitEthernet10/0/1 out-labels 103
vpp1-2# mpls local-label add 103 eos via 192.168.11.11 GigabitEthernet10/0/1 out-labels 103
vpp1-3# mpls local-label add 103 eos via ip4-lookup-in-table 0
vpp1-3# ip route add 10.0.1.0/32 via 192.0.2.0
With these two LSPs established, the ICMP echo request and subsequent ICMP echo reply can be seen traveling through the network entirely as MPLS:
root@tap1-0:~# tcpdump -c 10 -eni enp16s0f0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on enp16s0f0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
14:41:07.526861 52:54:00:20:10:03 > 52:54:00:13:10:02, ethertype 802.1Q (0x8100), length 102: vlan 33
p 0, ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 51470, seq 20, length 64
14:41:07.528103 52:54:00:13:10:00 > 52:54:00:12:10:01, ethertype 802.1Q (0x8100), length 106: vlan 22
p 0, ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 64)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 51470, seq 20, length 64
14:41:07.529342 52:54:00:12:10:00 > 52:54:00:11:10:01, ethertype 802.1Q (0x8100), length 106: vlan 21
p 0, ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 63)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 51470, seq 20, length 64
14:41:07.530421 52:54:00:11:10:00 > 52:54:00:10:10:01, ethertype 802.1Q (0x8100), length 106: vlan 20
p 0, ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 62)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 51470, seq 20, length 64
14:41:07.531160 52:54:00:10:10:03 > 52:54:00:21:10:00, ethertype 802.1Q (0x8100), length 102: vlan 40
p 0, ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 51470, seq 20, length 64
14:41:07.531455 52:54:00:21:10:00 > 52:54:00:10:10:03, ethertype 802.1Q (0x8100), length 102: vlan 40
p 0, ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 51470, seq 20, length 64
14:41:07.532245 52:54:00:10:10:01 > 52:54:00:11:10:00, ethertype 802.1Q (0x8100), length 106: vlan 20
p 0, ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 64)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 51470, seq 20, length 64
14:41:07.532732 52:54:00:11:10:01 > 52:54:00:12:10:00, ethertype 802.1Q (0x8100), length 106: vlan 21
p 0, ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 63)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 51470, seq 20, length 64
14:41:07.533923 52:54:00:12:10:01 > 52:54:00:13:10:00, ethertype 802.1Q (0x8100), length 106: vlan 22
p 0, ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 62)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 51470, seq 20, length 64
14:41:07.535040 52:54:00:13:10:02 > 52:54:00:20:10:03, ethertype 802.1Q (0x8100), length 102: vlan 33
p 0, ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 51470, seq 20, length 64
10 packets captured
10 packets received by filter
When vpp1-0 receives the MPLS frame with label 100,S=1, it looks up in the FIB to figure out what
operation to perform with this packet is to POP the label, revealing the inner payload, which it
must look in the IPv4 FIB, and forward as per normal. This is a bit more expensive than it could be,
and the folks who established MPLS protocols found a few clever ways to cut down on cost!
MPLS: Wellknown Label Values
I didn’t know this until I started tinkering with MPLS on VPP, and as an operator it’s easy to overlook these things. As it so turns out, there are a few MPLS label values that have a very specific meaning. Taking a read on [RFC3032], label values 0-15 are reserved and they each serve a specific purpose:
- Value 0: IPv4 Explicit NULL Label
- Value 1: Router Alert Label
- Value 2: IPv6 Explicit NULL Label
- Value 3: Implicit NULL Label
There’s a few other label values, 4-15, and if you’re curious you could take a look at the [Iana List] for them. For my purposes, though, I’m only going to look at these weird little NULL labels. What do they do?
MPLS: Explicit Null
RFC3032 discusses the IPv4 explicit NULL label, value 0 (and the IPv6 variant with value 2):
This label value is only legal at the bottom of the label stack. It indicates that the label stack must be popped, and the forwarding of the packet must then be based on the IPv4 header.
What this means in practice is that we can allow MPLS PE-Routers to take a little shortcut. If the MPLS label in the last hop is just telling the router to POP the label and take a look in its IPv4 forwarding table, I can also set the label to 0 in the router just preceding it. This way, when the last router sees label value 0, it knows already what to do, saving it one FIB lookup.
I can reconfigure both LSPs to make use of this feature, by changing the MPLS FIB entries on
vpp1-1 that points the LSP towards vpp1-0, removing what I configured before (mpls local-label del ...) and replacing that with an out-label value of 0 (mpls local-label add ...):
vpp1-1# mpls local-label del 100 eos via 192.168.11.6 GigabitEthernet10/0/0 out-labels 100
vpp1-1# mpls local-label add 100 eos via 192.168.11.6 GigabitEthernet10/0/0 out-labels 0
vpp1-2# mpls local-label del 103 eos via 192.168.11.11 GigabitEthernet10/0/1 out-labels 103
vpp1-2# mpls local-label add 103 eos via 192.168.11.11 GigabitEthernet10/0/1 out-labels 0
Due to this, the last routers in the LSP now already know what to do, so I can clean these up:
vpp1-0# mpls local-label del 100 eos via ip4-lookup-in-table 0
vpp1-3# mpls local-label del 103 eos via ip4-lookup-in-table 0
If I ping from host1-0 to host1-1 again, I can see a subtle but important difference in the
packets on the wire:
17:49:23.770119 52:54:00:20:10:03 > 52:54:00:13:10:02, ethertype 802.1Q (0x8100), length 102: vlan 33, p 0,
ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 524, length 64
17:49:23.770403 52:54:00:13:10:00 > 52:54:00:12:10:01, ethertype 802.1Q (0x8100), length 106: vlan 22, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 64)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 524, length 64
17:49:23.771184 52:54:00:12:10:00 > 52:54:00:11:10:01, ethertype 802.1Q (0x8100), length 106: vlan 21, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 63)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 524, length 64
17:49:23.772503 52:54:00:11:10:00 > 52:54:00:10:10:01, ethertype 802.1Q (0x8100), length 106: vlan 20, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 0, exp 0, [S], ttl 62)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 524, length 64
17:49:23.773392 52:54:00:10:10:03 > 52:54:00:21:10:00, ethertype 802.1Q (0x8100), length 102: vlan 40, p 0,
ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 524, length 64
17:49:23.773602 52:54:00:21:10:00 > 52:54:00:10:10:03, ethertype 802.1Q (0x8100), length 102: vlan 40, p 0,
ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 524, length 64
17:49:23.774592 52:54:00:10:10:01 > 52:54:00:11:10:00, ethertype 802.1Q (0x8100), length 106: vlan 20, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 64)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 524, length 64
17:49:23.775804 52:54:00:11:10:01 > 52:54:00:12:10:00, ethertype 802.1Q (0x8100), length 106: vlan 21, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 63)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 524, length 64
17:49:23.776973 52:54:00:12:10:01 > 52:54:00:13:10:00, ethertype 802.1Q (0x8100), length 106: vlan 22, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 0, exp 0, [S], ttl 62)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 524, length 64
17:49:23.778255 52:54:00:13:10:02 > 52:54:00:20:10:03, ethertype 802.1Q (0x8100), length 102: vlan 33, p 0,
ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 524, length 64
Did you spot it? :) If your eyes are spinning, don’t worry! I have configured the routers vpp1-1
towards vpp1-0 in vlan 20 to use IPv4 Explicit NULL (label 0). You can spot it on the fourth
packet in the tcpdump above. On the way back, vpp1-2 towards vpp1-3 in vlan 22 also sets IPv4
Explicit NULL for the echo-reply. But, I do notice that end to end, the packet is still traversing
the network entirely as MPLS packets. The optimization here is that vpp1-0 knows that label value
0 at the end of the label-stack just means ‘what follows is an IPv4 packet, route it.’.
MPLS: Implicit Null
Did that really help that much? I think I can answer the question by loadtesting, but first let me take a closer look at what RFC3032 has to say about the Implicit NULL Label:
A value of 3 represents the “Implicit NULL Label”. This is a label that an LSR may assign and distribute, but which never actually appears in the encapsulation. When an LSR would otherwise replace the label at the top of the stack with a new label, but the new label is “Implicit NULL”, the LSR will pop the stack instead of doing the replacement. Although this value may never appear in the encapsulation, it needs to be specified in the Label Distribution Protocol, so a value is reserved.
Oh, groovy! What this tells me is that I can take one further shortcut: if I set the label value 0 (Explicit NULL IPv4), or 2 (Explicit NULL IPV6), my last router in the chain will know to look up the FIB entry automatically, saving one MPLS FIB lookup. But in this case, label value 3 (Implicit NULL) is telling the router to just unwrap the MPLS parts (it’s looking at them anyway!) and just forward the bare inner payload which is an IPv4 or IPv6 packet, directy onto the last router. This is what all the real geeks call Penultimate Hop Popping or PHP, none of that website programming language rubbish!
Let me replace the FIB entries in the penultimate routers with this magic label value (3):
vpp1-1# mpls local-label del 100 eos via 192.168.11.6 GigabitEthernet10/0/0 out-labels 0
vpp1-1# mpls local-label add 100 eos via 192.168.11.6 GigabitEthernet10/0/0 out-labels 3
vpp1-2# mpls local-label del 103 eos via 192.168.11.11 GigabitEthernet10/0/1 out-labels 0
vpp1-2# mpls local-label add 103 eos via 192.168.11.11 GigabitEthernet10/0/1 out-labels 3
Now I would expect this penultimate hop popping to yield an IPv4 packet between vpp1-1 and
vpp1-0 on the ICMP echo-request, and as well an IPv4 packet between vpp1-2 and vpp1-3 on the ICMP
echo-reply way back, and would you look at that:
17:45:35.783214 52:54:00:20:10:03 > 52:54:00:13:10:02, ethertype 802.1Q (0x8100), length 102: vlan 33, p 0,
ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 298, length 64
17:45:35.783879 52:54:00:13:10:00 > 52:54:00:12:10:01, ethertype 802.1Q (0x8100), length 106: vlan 22, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 64)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 298, length 64
17:45:35.784222 52:54:00:12:10:00 > 52:54:00:11:10:01, ethertype 802.1Q (0x8100), length 106: vlan 21, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 100, exp 0, [S], ttl 63)
10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 298, length 64
17:45:35.785123 52:54:00:11:10:00 > 52:54:00:10:10:01, ethertype 802.1Q (0x8100), length 102: vlan 20, p 0,
ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 298, length 64
17:45:35.785311 52:54:00:10:10:03 > 52:54:00:21:10:00, ethertype 802.1Q (0x8100), length 102: vlan 40, p 0,
ethertype IPv4 (0x0800), 10.0.1.0 > 10.0.1.1: ICMP echo request, id 6172, seq 298, length 64
17:45:35.785533 52:54:00:21:10:00 > 52:54:00:10:10:03, ethertype 802.1Q (0x8100), length 102: vlan 40, p 0,
ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 298, length 64
17:45:35.786465 52:54:00:10:10:01 > 52:54:00:11:10:00, ethertype 802.1Q (0x8100), length 106: vlan 20, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 64)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 298, length 64
17:45:35.787354 52:54:00:11:10:01 > 52:54:00:12:10:00, ethertype 802.1Q (0x8100), length 106: vlan 21, p 0,
ethertype MPLS unicast (0x8847), MPLS (label 103, exp 0, [S], ttl 63)
10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 298, length 64
17:45:35.787575 52:54:00:12:10:01 > 52:54:00:13:10:00, ethertype 802.1Q (0x8100), length 102: vlan 22, p 0,
ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 298, length 64
17:45:35.788320 52:54:00:13:10:02 > 52:54:00:20:10:03, ethertype 802.1Q (0x8100), length 102: vlan 33, p 0,
ethertype IPv4 (0x0800), 10.0.1.1 > 10.0.1.0: ICMP echo reply, id 6172, seq 298, length 64
I can now see that the behavior has changed in a subtle way once again. Where before, there were
three MPLS packets all the way between vpp1-3 through vpp1-2 and vpp1-1 onto vpp1-0, now
there are only two MPLS packets, and the last one (on the way out in VLAN 20, and on the way
back in VLAN 22), is just an IPv4 packet. PHP is slick!
Loadtesting Setup: Bare Metal

In 1997, an Internet Engineering Task Force (IETF) working group created standards to help fix the issues of the time, mostly around internet traffic routing. MPLS was developed as an alternative to multilayer switching and IP over asynchronous transfer mode (ATM). In the 90s, routers were comparatively weak in terms of CPU, and things like content addressable memory to facilitate faster lookups, was incredibly expensive. Back then, every FIB lookup counted, so tricks like Penultimate Hop Popping really helped. But what about now? I’m reasonably confident that any silicon based router would not mind to have one extra MPLS FIB operation, and equally would not mind to unwrap the MPLS packet at the end. But, since these things exist, I thought it would be a fun activity to see how much they would help in the VPP world, where just like in the old days, every operation performed on a packet does cost valuable CPU cycles.
I can’t really perform a loadtest on the virtual machines backed by Open vSwitch, while tightly packing six machines on one hypervisor. That setup is made specifically to do functional testing and development work. To do a proper loadtest, I will need bare metal. So, I grabbed three Supermicro SYS-5018D-FN8T, which I’m running throughout [AS8298], as I know their performance quite well. I’ll take three of these, and daisychain them with TenGig ports. This way, I can take a look at the cost of P-Routers (which only SWAP MPLS labels and forward the result), as well as PE-Routers (which have to encapsulate, and sometimes decapsulate the IP or Ethernet traffic).
These machines get a fresh Debian Bookworm install and VPP 23.06 without any plugins. It’s weird for me to run a VPP instance without Linux CP, but in this case I’m going completely vanilla, so I disable all plugins and give each VPP machine one worker thread. The install follows my popular [VPP-7]. By the way did you know that you can just type the search query [VPP-7] directly into Google to find this article. Am I an influencer now? Jokes aside, I decide to call the bare metal machines France, Belgium and Netherlands. And because if it ain’t dutch, it ain’t much, the Netherlands machine sits on top :)
IPv4 forwarding performance
The way Cisco T-Rex works in its simplest stateless loadtesting mode, is that it reads a Scapy file,
for example bench.py, and it then generates a stream of traffic from its first port, through the
device under test (DUT), and expects to see that traffic returned on its second port. In a
bidirectional mode, traffic is sent from 16.0.0.0/8 to 48.0.0.0/8 in one direction, and back
from 48.0.0.0/8 to 16.0.0.0/8 in the other.
OK so first things first, let me configure a basic skeleton, taking Netherlands as an example:
netherlands# set interface ip address TenGigabitEthernet6/0/1 192.168.13.7/31
netherlands# set interface ip address TenGigabitEthernet6/0/1 2001:678:d78:230::2:2/112
netherlands# set interface state TenGigabitEthernet6/0/1 up
netherlands# ip route add 100.64.0.0/30 via 192.168.13.6
netherlands# ip route add 192.168.13.4/31 via 192.168.13.6
netherlands# set interface ip address TenGigabitEthernet6/0/0 100.64.1.2/30
netherlands# set interface state TenGigabitEthernet6/0/0 up
netherlands# ip nei TenGigabitEthernet6/0/0 100.64.1.1 9c:69:b4:61:ff:40 static
netherlands# ip route add 16.0.0.0/8 via 100.64.1.1
netherlands# ip route add 48.0.0.0/8 via 192.168.13.6
The Belgium router just has static routes back and forth, and the France router looks similar except it has its static routes all pointing in the other direction, and of course it has different /31 transit networks towards T-Rex and Belgium. The one thing that is a bit curious is the use of a static ARP entry that allows the VPP routers to resolve the nexthop for T-Rex – in the case above, T-Rex is sourcing from 100.64.1.1/30 (which has MAC address 9c:69:b4:61:ff:40) and sending to our 100.64.1.2 on Te6/0/0.
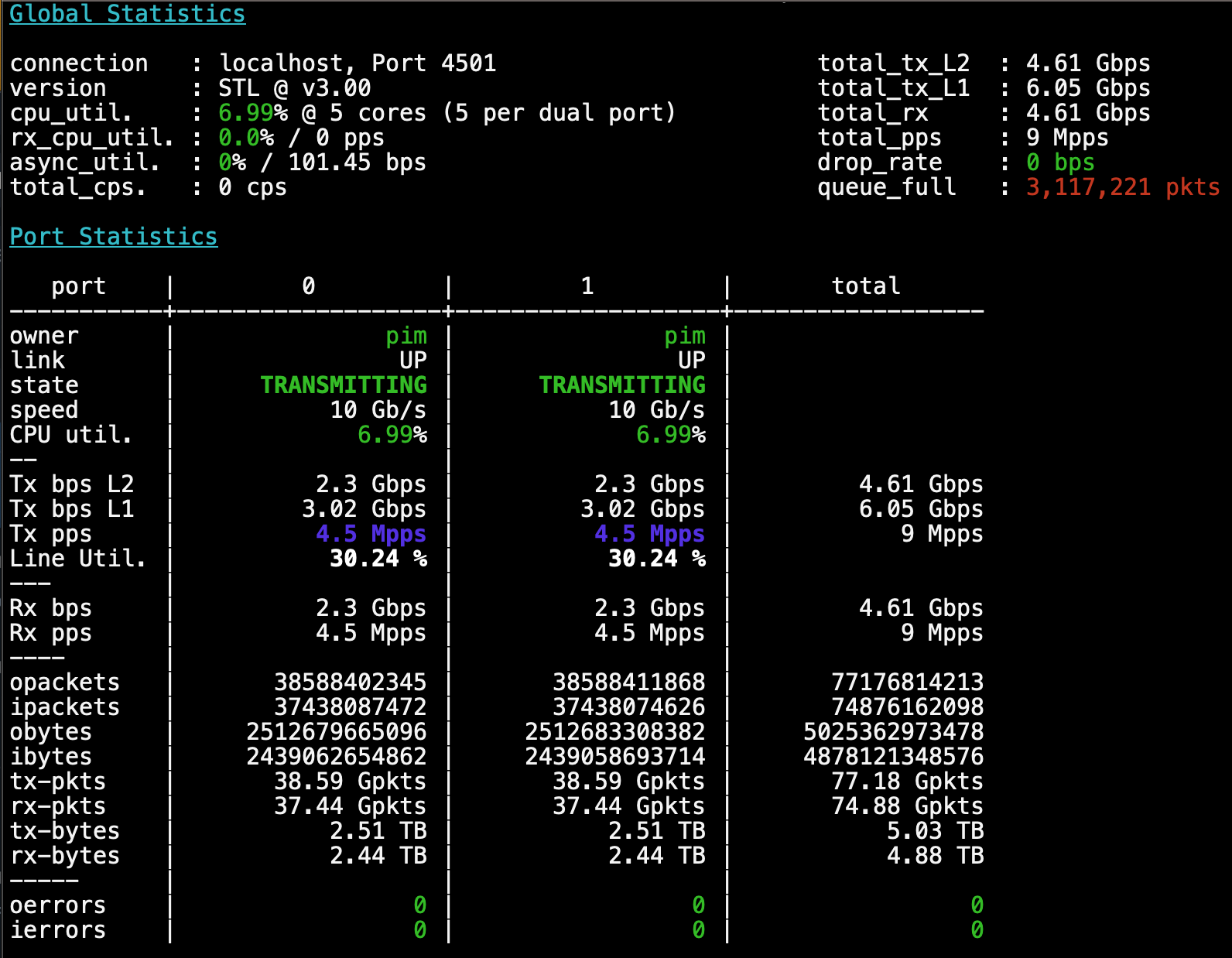
After fiddling around a little bit with imix, I do notice the machine is still keeping up
with one CPU thread in both directions (~6.5Mpps). So I switch to 64b packets and ram up traffic
until that one VPP worker thread is saturated, which is a around the 9.2Mpps mark, so I lower it
slightly to a cool 9Mpps. Note: this CPU can have 3 worker threads in production, so it can do roughly
27Mpps per router, which is way cool!
The machines are at this point all doing exactly the same: receive ethernet from DPDK, do an IPv4 lookup, rewrite the header, and emit the frame on another interface. I can see that clearly in the runtime statistics, taking a look at Belgium for example:
belgium# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 7912.6, 10 sec internal node vector rate 207.47 loops/sec 20604.47
vector rates in 8.9997e6, out 9.0054e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/0-output active 172120948 35740749991 0 6.47e0 207.65
TenGigabitEthernet6/0/0-tx active 171687877 35650752635 0 8.49e1 207.65
TenGigabitEthernet6/0/1-output active 172119849 35740963315 0 7.79e0 207.65
TenGigabitEthernet6/0/1-tx active 171471125 35605967085 0 8.48e1 207.65
dpdk-input polling 171588827 71211720238 0 4.87e1 415.01
ethernet-input active 344675998 71571710136 0 2.16e1 207.65
ip4-input-no-checksum active 343340278 71751697912 0 1.86e1 208.98
ip4-load-balance active 342929714 71661706997 0 1.44e1 208.97
ip4-lookup active 341632798 71391716172 0 2.28e1 208.97
ip4-rewrite active 342498637 71571712383 0 2.59e1 208.97
Looking at the time spent for one individual packet, it’s about 245 CPU cycles, and considering the cores on this Xeon D1518 run at 2.2GHz, that checks out very accurately: 2.2e9 / 245 = 9Mpps! Every time that DPDK is asked for some work, it yields on average a vector of 208 packets – and this is why VPP is so super fast: the first packet may need to page in the instructions belonging to one of the graph nodes, but the second through 208th packet will find almost 100% hitrate in the CPU’s instruction cache. Who needs RAM anyway?
MPLS forwarding performance
Now that I have a baseline, I can take a look at the difference between the IPv4 path and the MPLS path, and here’s where the routers will start to behave differently. France and Netherlands will be PE-Routers and handle encapsulation/decapsulation, while Belgium has a comparatively easy job, as it will only handle MPLS forwarding. I’ll choose country-codes for the labels, that which is destined to France will have MPLS label 33,S=1; while that which goes to Netherlands will have MPLS label 31,S=1.
netherlands# ip ro del 48.0.0.0/8 via 192.168.13.6
netherlands# ip ro add 48.0.0.0/8 via 192.168.13.6 TenGigabitEthernet6/0/1 out-labels 33
netherlands# mpls local-label add 31 eos via ip4-lookup-in-table 0
belgium# ip route del 48.0.0.0/8 via 192.168.13.4
belgium# ip route del 16.0.0.0/8 via 192.168.13.7
belgium# mpls local-label add 33 eos via 192.168.13.4 TenGigabitEthernet6/0/1 out-labels 33
belgium# mpls local-label add 31 eos via 192.168.13.7 TenGigabitEthernet6/0/0 out-labels 31
france# ip route del 16.0.0.0/8 via 192.168.13.5
france# ip route add 16.0.0.0/8 via 192.168.13.5 TenGigabitEthernet6/0/1 out-labels 31
france# mpls local-label add 33 eos via ip4-lookup-in-table 0
The types of operation in MPLS is no longer symmetric. On the way in, the PE-Router has to encapsulate the IPv4 packet into an MPLS packet, and on the way out, the PE-Router has to decapsulate the MPLS packet to reveal the IPv4 packet. So, I change the loadtester to be unidirectional, and ask it to send 10Mpps from Netherlands to France. As soon as I reconfigure the routers in this mode, I see quite a bit of packetlo, as only 7.3Mpps make it through. Interesting! I wonder where this traffic is dropped, and what the bottleneck is, precisely.
MPLS: PE Ingress Performance
First, let’s take a look at Netherlands, to try to understand why it is more expensive:
netherlands# show run
Time 255.5, 10 sec internal node vector rate 256.00 loops/sec 29399.92
vector rates in 7.6937e6, out 7.6937e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/1-output active 7978541 2042505472 0 7.28e0 255.99
TenGigabitEthernet6/0/1-tx active 7678013 1965570304 0 8.25e1 255.99
dpdk-input polling 7684444 1965570304 0 4.55e1 255.79
ethernet-input active 7978549 2042507520 0 1.94e1 255.99
ip4-input-no-checksum active 7978557 2042509568 0 1.75e1 255.99
ip4-lookup active 7678013 1965570304 0 2.17e1 255.99
ip4-mpls-label-imposition-pipe active 7678013 1965570304 0 2.42e1 255.99
mpls-output active 7678013 1965570304 0 6.71e1 255.99
Each packet gets from dpdk-input into ethernet-input, the resulting IPv4 packet visits
ip4-lookup FIB where the MPLS out-label is found in the IPv4 FIB, the packet is then wrapped into
an MPLS packet in ip4-mpls-label-imposition-pipe and then sent through mpls-output to the NIC.
In total the input path (ip4-* plus mpls-*) takes 131 CPU cycles for each packet. Including
all the nodes, from DPDK input to DPDK output sums up to 285 cycles, so 2.2GHz/285 = 7.69Mpps which
checks out.
MPLS: P Transit Performance
I would expect that Belgium has it easier, as it’s only doing label swapping and MPLS forwarding.
belgium# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 595.6, 10 sec internal node vector rate 47.68 loops/sec 224464.40
vector rates in 7.6930e6, out 7.6930e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/1-output active 97711093 4659109793 0 8.83e0 47.68
TenGigabitEthernet6/0/1-tx active 96096377 4582172229 0 8.14e1 47.68
dpdk-input polling 161102959 4582172278 0 5.72e1 28.44
ethernet-input active 97710991 4659111684 0 2.45e1 47.68
mpls-input active 97709468 4659096718 0 2.25e1 47.68
mpls-label-imposition-pipe active 99324916 4736048227 0 2.52e1 47.68
mpls-lookup active 99324903 4736045943 0 3.25e1 47.68
mpls-output active 97710989 4659111742 0 3.04e1 47.68
Indeed, Belgium can still breathe, it’s spending 110 Cycles per packet doing the MPLS
switching (mpls-*), which is 18% less than the PE-Router ingress. Judging by the vectors/Call
(last column), it’s also running a bit cooler than the ingress router.
It’s nice to see that the claim that P-Routers are cheaper on the CPU can be verified to be true in practice!
MPLS: PE Egress Performance
On to the last router, France, which is in charge of decapsulating the MPLS packet and doing the resulting IPv4 lookup:
france# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 1067.2, 10 sec internal node vector rate 256.00 loops/sec 27986.96
vector rates in 7.3234e6, out 7.3234e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/0-output active 30528978 7815395072 0 6.59e0 255.99
TenGigabitEthernet6/0/0-tx active 30528978 7815395072 0 8.20e1 255.99
dpdk-input polling 30534880 7815395072 0 4.68e1 255.95
ethernet-input active 30528978 7815395072 0 1.97e1 255.99
ip4-load-balance active 30528978 7815395072 0 1.35e1 255.99
ip4-mpls-label-disposition-pip active 30528978 7815395072 0 2.82e1 255.99
ip4-rewrite active 30528978 7815395072 0 2.48e1 255.99
lookup-ip4-dst active 30815069 7888634368 0 3.09e1 255.99
mpls-input active 30528978 7815395072 0 1.86e1 255.99
mpls-lookup active 30528978 7815395072 0 2.85e1 255.99
This router is spending its time (in *ip4* and mpls-*) roughly at roughly 144.5 Cycles per
packet and reveals itself as the bottleneck. Netherlands sent Belgium 7.69Mpps which it all
forwarded to France, where only 7.3Mpps make it through this PE-Router egress, and into the
hands of T-Rex. In total, this router is spending 298 cycles/packet, which amounts to 7.37Mpps.
MPLS Explicit Null performance
At the beginning of this article, I made a claim that we could take some shortcuts, and now is a good time to see if those short cuts are worthwhile in the VPP setting. I’ll reconfigure the Belgium router to set the IPv4 Explicit NULL label (0), which can help my poor overloaded France router save some valuable CPU cycles.
belgium# mpls local-label del 33 eos via 192.168.13.4 TenGigabitEthernet6/0/1 out-labels 33
belgium# mpls local-label add 33 eos via 192.168.13.4 TenGigabitEthernet6/0/1 out-labels 0
The situation for Belgium doesn’t change at all, it’s still doing the SWAP operation on the incoming packet, but it’s writing label 0,S=1 now (instead of label 33,S=1 before). But, haha!, take a look at France for an important difference:
france# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 53.3, 10 sec internal node vector rate 85.35 loops/sec 77643.80
vector rates in 7.6933e6, out 7.6933e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/0-output active 4773870 409847372 0 6.96e0 85.85
TenGigabitEthernet6/0/0-tx active 4773870 409847372 0 8.07e1 85.85
dpdk-input polling 4865704 409847372 0 5.01e1 84.23
ethernet-input active 4773870 409847372 0 2.15e1 85.85
ip4-load-balance active 4773869 409847235 0 1.51e1 85.85
ip4-rewrite active 4773870 409847372 0 2.60e1 85.85
lookup-ip4-dst-itf active 4773870 409847372 0 3.41e1 85.85
mpls-input active 4773870 409847372 0 1.99e1 85.85
mpls-lookup active 4773870 409847372 0 3.01e1 85.85
First off, I notice the input vector rates match the output vector rates, both at 7.69Mpps, and that the average Vectors/Call is no longer pegged at 256. The router is now spending 125 Cycles per packet which is a lot better than it was before (15.4% better than 144.5 Cycles/packet).
Conclusion: MPLS Explicit NULL is cheaper!
MPLS Implicit Null (PHP) performance
So there’s one mode of operation left for me to play with. What if we asked Belgium to unwrap the MPLS packet and forward it as an IPv4 packet towards France, in other words apply Penultimate Hop Popping? Of course, the ingress Netherlands won’t change at all, but I reconfigure the Belgium router, like so:
belgium# mpls local-label del 33 eos via 192.168.13.4 TenGigabitEthernet6/0/1 out-labels 0
belgium# mpls local-label add 33 eos via 192.168.13.4 TenGigabitEthernet6/0/1 out-labels 3
The situation in Belgium now looks subtly different:
belgium# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 171.1, 10 sec internal node vector rate 50.64 loops/sec 188552.87
vector rates in 7.6966e6, out 7.6966e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/1-output active 26128425 1316828499 0 8.74e0 50.39
TenGigabitEthernet6/0/1-tx active 26128424 1316828327 0 8.16e1 50.39
dpdk-input polling 39339977 1316828499 0 5.58e1 33.47
ethernet-input active 26128425 1316828499 0 2.39e1 50.39
ip4-mpls-label-disposition-pip active 26128425 1316828499 0 3.07e1 50.39
ip4-rewrite active 27648864 1393790359 0 2.82e1 50.41
mpls-input active 26128425 1316828499 0 2.21e1 50.39
mpls-lookup active 26128422 1316828355 0 3.16e1 50.39
After doing the mpls-lookup, this router finds that it can just toss the label and forward the
packet as IPv4 down south. Cost for Belgium: 113 Cycles per packet.
France is now not participating in MPLS at all - it is simply receiving IPv4 packets which it has to route back towards T-Rex. I take one final look at France to see where it’s spending its time:
france# show run
Thread 1 vpp_wk_0 (lcore 1)
Time 397.3, 10 sec internal node vector rate 42.17 loops/sec 259634.88
vector rates in 7.7112e6, out 7.6964e6, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
TenGigabitEthernet6/0/0-output active 74381543 3211443520 0 9.47e0 43.18
TenGigabitEthernet6/0/0-tx active 70820630 3057504872 0 8.26e1 43.17
dpdk-input polling 131873061 3063377312 0 6.09e1 23.23
ethernet-input active 72645873 3134461107 0 2.66e1 43.15
ip4-input-no-checksum active 70820629 3057504812 0 2.68e1 43.17
ip4-load-balance active 72646140 3134473660 0 1.74e1 43.15
ip4-lookup active 70820628 3057504796 0 2.79e1 43.17
ip4-rewrite active 70820631 3057504924 0 2.96e1 43.17
As an IPv4 router, France spends in total 102 Cycles per packet. This matches very closely with the 104 cycles/packet I found when doing my baseline loadtest with only IPv4 routing. I love it when numbers align!!
Scaling
One thing that I was curious to know, is if MPLS packets would allow for multiple receive queues, to
enable horizontal scaling by adding more VPP worker threads. The answer is a resounding YES! If I
restart the VPP routers Netherlands, Belgium and France with three workers and set DPDK
num-rx-queues to 3 as well, I see perfect linear scaling, in other words these little routers
would be able to forward roughly 27Mpps of MPLS packets with varying inner payloads (be it IPv4 or
IPv6 or Ethernet traffic with differing src/dest MAC addresses). All things said, IPv4 is still a
little bit cheaper on the CPU, at least on these routers with only a very small routing table. But,
it’s great to see that MPLS forwarding can leverage RSS.
Conclusions
This is all fine and dandy, but I think it’s a bit trickier to see if PHP is actually cheaper or not. To answer this question, I think I should count the total amount of CPU cycles spent end to end: for a packet traveling from T-Rex coming into Netherlands, through Belgium and France, and back out to T-Rex.
| Netherlands | Belgium | France | Total Cost | |
|---|---|---|---|---|
| Regular IPv4 path | 104 cycles | 104 cycles | 104 cycles | 312 cycles |
| MPLS: Simple LSP | 131 cycles | 110 cycles | 145 cycles | 386 cycles |
| MPLS: Explicit NULL LSP | 131 cycles | 110 cycles | 125 cycles | 366 cycles |
| MPLS: Penultimate Hop Pop | 131 cycles | 113 cycles | 102 cycles | 346 cycles |
Note: The clock cycle numbers here are only *mpls* and *ip4* nodes, exclusing the *-input,
*-output and *-tx nodes, as they will add the same cost for all modes of operation.
I threw a lot of numbers into this article, and my head is spinning as I write this. But I still think I can wrap it up in a way that allows me to have a few high level takeaways:
- IPv4 forwarding is a fair bit cheaper than MPLS forwarding (with an empty FIB, anyway). I had not expected this!
- End to end, the MPLS bottleneck is in the PE-Ingress operation.
- Explicit NULL helps without any drawbacks, as it cuts off one MPLS FIB lookup in the PE-Egress operation.
- Implicit NULL (aka Penultimate Hop Popping) is also the fastest way to do MPLS with VPP, all things considered.
What’s next
I joined forces with @vifino who has effectively added MPLS handling to the Linux Control Plane, so VPP can start to function as an MPLS router using FRR’s label distribution protocol implementation. Gosh, I wish Bird3 would have LDP :)
Our work is mostly complete, there’s two pending Gerrit’s which should be ready to review and certainly ready to play with:
- [Gerrit 38826]: This adds the ability to listen to internal state changes of an interface, so that the Linux Control Plane plugin can enable MPLS on the LIP interfaces and Linux sysctl for MPLS input.
- [Gerrit 38702]: This adds the ability to listen to Netlink messages in the Linux Control Plane plugin, and sensibly apply these routes to the IPv4, IPv6 and MPLS FIB in the VPP dataplane.
If you’d like to test this - reach out to the VPP Developer mailinglist [ref] any time!