Introduction
Last month, I took a good look at the Gowin R86S based on Jasper Lake (N6005) CPU [ref], which is a really neat little 10G (and, if you fiddle with it a little bit, 25G!) router that runs off of USB-C power and can be rack mounted if you print a bracket. Check out my findings in this [article].
David from Gowin reached out and asked me if I was willing to also take a look their Alder Lake (N305) CPU, which comes in a 19" rack mountable chassis, running off of 110V/220V AC mains power, but also with 2x25G ConnectX-4 network card. Why not! For critical readers: David sent me this machine, but made no attempt to influence this article.
Hardware Specs

There are a few differences between this 19" model and the compact mini-pc R86S. The most obvious difference is the form factor. The R86S is super compact, not inherently rack mountable, although I 3D printed a bracket for it. Looking inside, the motherboard is mostly obscured bya large cooling block with fins that are flush with the top plate. There are 5 copper ports in the front: 2x Intel i226-V (these are 2.5Gbit) and 3x Intel i210 (these are 1Gbit), and one of them offers POE, which can be very handy to power a camera or wifi access point. A nice touch.
The Gowin server comes with an OCP v2.0 port, just like the R86S does. There’s a custom bracket with a ribbon cable to the motherboard, and in the bracket is housed a Mellanox ConnectX-4 LX 2x25Gbit network card.
A look inside

The machine comes with an Intel i3-N305 (Alder Lake) CPU running at a max clock of 3GHz and 4x8GB of LPDDR5 memory at 4800MT/s – and considering the Alder Lake can make use of 4-channel memory, this thing should be plenty fast. The memory is soldered to the board, though, so there’s no option of expanding or changing the memory after buying the unit.
Using likwid-topology, I determine that the 8-core CPU has no hyperthreads, but just straight up 8
cores with 32kB of L1 cache, two times 2MB of L3 cache (shared between cores 0-3, and another bank
shared between cores 4-7), and 6MB of L3 cache shared between all 8 cores. This is again a step up
from the Jasper Lake CPU, and should make VPP run a little bit faster.
What I find a nice touch is that Gowin has shipped this board with a 128GB MMC flash disk, which
appears in Linux as /dev/mmcblk0 and can be used to install an OS. However, there are also two
NVME slots with M.2 2280, one M.SATA slot and two additional SATA slots with 4-pin power. On the
side of the chassis is a clever bracket that holds three 2.5" SSDs in a staircase configuration.
That’s quite a lot of storage options, and given the CPU has some oompf, this little one could
realistically be a NAS, although I’d prefer it to be a VPP router!

The copper RJ45 ports are all on the motherboard, and there’s an OCP breakout port that fits any OCP v2.0 network card. Gowin shipped it with a ConnectX-4 LX, but since I had a ConnectX-5 EN, I will take a look at performance with both cards. One critical observation, as with the Jasper Lake R86S, is that there are only 4 PCIe v3.0 lanes routed to the OCP, which means that the spiffy x8 network interfaces (both the Cx4 and the Cx5 I have here) will run at half speed. Bummer!
The power supply is a 100-240V switching PSU with about 150W of power available. When running idle, with one 1TB NVME drive, I measure 38.2W on the 220V side. When running VPP at full load, I measure 47.5W of total load. That’s totally respectable for a 2x 25G + 2x 2.5G + 3x 1G VPP router.
I’ve added some pictures to a [Google Photos] album, if you’d like to take a look.
VPP Loadtest: RDMA versus DPDK
You (hopefully>) came here to read about VPP stuff. For years now, I have been curious as to the performance and functional differences in VPP between using DPDK and the native RDMA driver support that Mellanox network cards have support for. In this article, I’ll do four loadtests, with the stock Mellanox Cx4 that comes with the Gowin server, and with the Mellanox Cx5 card that I had bought for the R86S. I’ll take a look at the differences betwen DPDK on the one hand and RDMA on the other. This will yield, for me at least, a better understanding on the differences. Spoiler: there are not many!
DPDK

The Data Plane Development Kit (DPDK) is an open source software project managed by the Linux Foundation. It provides a set of data plane libraries and network interface controller polling-mode drivers for offloading ethernet packet processing from the operating system kernel to processes running in user space. This offloading achieves higher computing efficiency and higher packet throughput than is possible using the interrupt-driven processing provided in the kernel.
You can read more about it on [Wikipedia] or on the [DPDK Homepage]. VPP uses DPDK as one of the (more popular) drivers for network card interaction.
DPDK: ConnectX-4 Lx
This is the OCP network card that came with the Gowin server. It identifies in Linux as:
0e:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
0e:00.1 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
Albeit with an important warning in dmesg, about the lack of PCIe lanes:
[3.704174] pci 0000:0e:00.0: [15b3:1015] type 00 class 0x020000
[3.708154] pci 0000:0e:00.0: reg 0x10: [mem 0x60e2000000-0x60e3ffffff 64bit pref]
[3.716221] pci 0000:0e:00.0: reg 0x30: [mem 0x80d00000-0x80dfffff pref]
[3.724079] pci 0000:0e:00.0: Max Payload Size set to 256 (was 128, max 512)
[3.732678] pci 0000:0e:00.0: PME# supported from D3cold
[3.736296] pci 0000:0e:00.0: reg 0x1a4: [mem 0x60e4800000-0x60e48fffff 64bit pref]
[3.756916] pci 0000:0e:00.0: 31.504 Gb/s available PCIe bandwidth, limited by 8.0 GT/s PCIe x4 link
at 0000:00:1d.0 (capable of 63.008 Gb/s with 8.0 GT/s PCIe x8 link)
With a PCIe v3.0 overhead of 130b/128b, that means the card will have (128/130) * 32 = 31.508 Gbps
available and I’m actually not quite sure why the kernel claims 31.504G in the log message. Anyway,
the card itself works just fine at this speed, and is immediately detected in DPDK while continuing
to use the mlx5_core driver. This would be a bit different with Intel based cards, as there the
driver has to be rebound to vfio_pci or uio_pci_generic. Here, the NIC itself remains visible
(and usable!) in Linux, which is kind of neat.
I do my standard set of eight loadtests: {unidirectional,bidirectional} x {1514b, 64b multiflow, 64b singleflow, MPLS}. This teaches me a lot about how the NIC uses flow hashing, and what it’s maximum performance is. Without further ado, here’s the results:
| Loadtest: Gowin CX4 DPDK | L1 bits/sec | Packets/sec | % of Line |
|---|---|---|---|
| 1514b-unidirectional | 25.00 Gbps | 2.04 Mpps | 100.2 % |
| 64b-unidirectional | 7.43 Gbps | 11.05 Mpps | 29.7 % |
| 64b-single-unidirectional | 3.09 Gbps | 4.59 Mpps | 12.4 % |
| 64b-mpls-unidirectional | 7.34 Gbps | 10.93 Mpps | 29.4 % |
| 1514b-bidirectional | 22.63 Gbps | 1.84 Mpps | 45.2 % |
| 64b-bidirectional | 7.42 Gbps | 11.04 Mpps | 14.8 % |
| 64b-single-bidirectional | 5.33 Gbps | 7.93 Mpps | 10.7 % |
| 64b-mpls-bidirectional | 7.36 Gbps | 10.96 Mpps | 14.8 % |
Some observations:
- In the large packet department, the NIC easily saturates the port speed in unidirectional, and saturates the PCI bus (x4) in bidirectional forwarding. I’m surprised that the bidirectional forwarding capacity is a bit lower (1.84Mpps versus 2.04Mpps).
- The NIC is using three queues, and the difference between single flow (which could only use one queue, and one CPU thread) is not exactly linear (4.59Mpps vs 11.05Mpps for 3 RX queues)
- The MPLS performance is higher than single flow, which I think means that the NIC is capable of hashing the packets based on the inner packet. Otherwise, while using the same MPLS label, the Cx3 and other NICs tend to just leverage only one receive queue.
I’m very curious how this NIC stacks up between DPDK and RDMA – read on below for my results!
DPDK: ConnectX-5 EN
I swap the card out of its OCP bay and replace it with a ConnectX-5 EN that I have from when I tested the [R86S]. It identifies as:
0e:00.0 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]
0e:00.1 Ethernet controller: Mellanox Technologies MT27800 Family [ConnectX-5]
And similar to the ConnectX-4, this card also complains about PCIe bandwidth:
[6.478898] mlx5_core 0000:0e:00.0: firmware version: 16.25.4062
[6.485393] mlx5_core 0000:0e:00.0: 31.504 Gb/s available PCIe bandwidth, limited by 8.0 GT/s PCIe x4 link
at 0000:00:1d.0 (capable of 63.008 Gb/s with 8.0 GT/s PCIe x8 link)
[6.816156] mlx5_core 0000:0e:00.0: E-Switch: Total vports 10, per vport: max uc(1024) max mc(16384)
[6.841005] mlx5_core 0000:0e:00.0: Port module event: module 0, Cable plugged
[7.023602] mlx5_core 0000:0e:00.0: MLX5E: StrdRq(1) RqSz(8) StrdSz(2048) RxCqeCmprss(0)
[7.177744] mlx5_core 0000:0e:00.0: Supported tc offload range - chains: 4294967294, prios: 4294967295
With that said, the loadtests are quite a bit more favorable for the newer ConnectX-5:
| Loadtest: Gowin CX5 DPDK | L1 bits/sec | Packets/sec | % of Line |
|---|---|---|---|
| 1514b-unidirectional | 24.98 Gbps | 2.04 Mpps | 99.7 % |
| 64b-unidirectional | 10.71 Gbps | 15.93 Mpps | 42.8 % |
| 64b-single-unidirectional | 4.44 Gbps | 6.61 Mpps | 17.8 % |
| 64b-mpls-unidirectional | 10.36 Gbps | 15.42 Mpps | 41.5 % |
| 1514b-bidirectional | 24.70 Gbps | 2.01 Mpps | 49.4 % |
| 64b-bidirectional | 14.58 Gbps | 21.69 Mpps | 29.1 % |
| 64b-single-bidirectional | 8.38 Gbps | 12.47 Mpps | 16.8 % |
| 64b-mpls-bidirectional | 14.50 Gbps | 21.58 Mpps | 29.1 % |
Some observations:
- The NIC also saturates 25G in one direction with large packets, and saturates the PCI bus when pushing in both directions.
- Single queue / thread operation at 6.61Mpps is a fair bit higher than Cx4 (which is 4.59Mpps)
- Multiple threads scale almost linearly, from 6.61Mpps in 1Q to 15.93Mpps in 3Q. That’s respectable!
- Bidirectional small packet performance is pretty great at 21.69Mpps, more than double that of the Cx4 (which is 11.04Mpps).
- MPLS rocks! The NIC forwards 21.58Mpps of MPLS traffic.
One thing I should note, is that at this point, the CPUs are not fully saturated. Looking at Prometheus/Grafana for this set of loadtests:
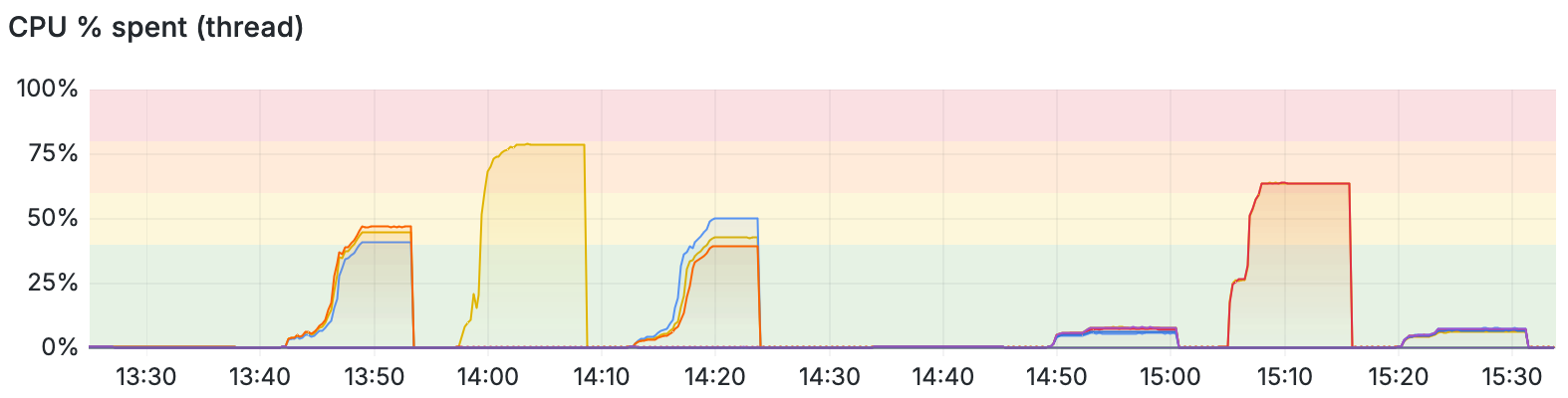
What I find interesting is that in no cases did any CPU thread run to 100% utilization. In the 64b single flow loadtests (from 14:00-14:10 and from 15:05-15:15), the CPU threads definitely got close, but they did not clip – which does lead me to believe that the NIC (or the PCIe bus!) are the bottleneck.
By the way, the bidirectional single flow 64b loadtest shows two threads that have an overall slightly lower utilization (63%) versus the unidirectional single flow 64 loadtest (at 78.5%). I think this can be explained by the two threads being able to use/re-use each others’ cache lines.
Conclusion: ConnectX-5 performs significantly better than ConnectX-4 with DPDK.
RDMA

RDMA supports zero-copy networking by enabling the network adapter to transfer data from the wire directly to application memory or from application memory directly to the wire, eliminating the need to copy data between application memory and the data buffers in the operating system. Such transfers require no work to be done by CPUs, caches, or context switches, and transfers continue in parallel with other system operations. This reduces latency in message transfer.
You can read more about it on [Wikipedia] VPP uses RDMA in a clever way, relying on the Linux library for rdma-core (libibverb) to create a custom userspace poll-mode driver, specifically for Ethernet packets. Despite using the RDMA APIs, this is not about RDMA (no Infiniband, no RoCE, no iWARP), just pure traditional Ethernet packets. Many VPP developers recommend and prefer RDMA for Mellanox devices. I myself have been more comfortable with DPDK. But, now is the time to FAFO.
RDMA: ConnectX-4 Lx
Considering I used three RX queues for DPDK, I instruct VPP now to use 3 receive queues for RDMA as
well. I remove the dpdk_plugin.so from startup.conf, although I could also have kept the DPDK
plugin running (to drive the 1.0G and 2.5G ports!) and de-selected the 0000:0e:00.0 and
0000:0e:00.1 PCI entries, so that the RDMA driver can grab them.
The VPP startup now looks like this:
vpp# create interface rdma host-if enp14s0f0np0 name xxv0 rx-queue-size 512 tx-queue-size 512
num-rx-queues 3 no-multi-seg no-striding max-pktlen 2026
vpp# create interface rdma host-if enp14s0f1np1 name xxv1 rx-queue-size 512 tx-queue-size 512
num-rx-queues 3 no-multi-seg no-striding max-pktlen 2026
vpp# set int mac address xxv0 02:fe:4a:ce:c2:fc
vpp# set int mac address xxv1 02:fe:4e:f5:82:e7
I realize something pretty cool - the RDMA interface gets an ephemeral (randomly generated) MAC address, while the main network card in Linux stays available. The NIC internally has a hardware filter for the RDMA bound MAC address and gives it to VPP – the implication is that the 25G NICs can also be used in Linux itself. That’s slick.
Performance wise:
| Loadtest: Gowin CX4 with RDMA | L1 bits/sec | Packets/sec | % of Line |
|---|---|---|---|
| 1514b-unidirectional | 25.01 Gbps | 2.04 Mpps | 100.3 % |
| 64b-unidirectional | 12.32 Gbps | 18.34 Mpps | 49.1 % |
| 64b-single-unidirectional | 6.21 Gbps | 9.24 Mpps | 24.8 % |
| 64b-mpls-unidirectional | 11.95 Gbps | 17.78 Mpps | 47.8 % |
| 1514b-bidirectional | 26.24 Gbps | 2.14 Mpps | 52.5 % |
| 64b-bidirectional | 14.94 Gbps | 22.23 Mpps | 29.9 % |
| 64b-single-bidirectional | 11.53 Gbps | 17.16 Mpps | 23.1 % |
| 64b-mpls-bidirectional | 14.99 Gbps | 22.30 Mpps | 30.0 % |
Some thoughts:
- The RDMA driver is significantly faster than DPDK in this configuration. Hah!
- 1514b are fine in both directions, RDMA slightly outperforms DPDK in the bidirectional test.
- 64b is massively faster:
- Unidirectional multiflow: RDMA 18.34Mpps, DPDK 11.05Mpps
- Bidirectional multiflow: RDMA 22.23Mpps, DPDK 11.04Mpps
- Bidirectional MPLS: RDMA 22.30Mpps, DPDK 10.93Mpps.
Conclusion: I would say, roughly speaking, that RDMA outperforms DPDK on the Cx4 by a factor of two. That’s really cool, especially because ConnectX-4 network cards are found very cheap these days.
RDMA: ConnectX-5 EN
Well then what about the newer Mellanox ConnectX-5 card? Something surprising happens when I boot the machine and start the exact same configuration as with the Cx4, the loadtests results almost invariably suck:
| Loadtest: Gowin CX5 with RDMA | L1 bits/sec | Packets/sec | % of Line |
|---|---|---|---|
| 1514b-unidirectional | 24.95 Gbps | 2.03 Mpps | 99.6 % |
| 64b-unidirectional | 6.19 Gbps | 9.22 Mpps | 24.8 % |
| 64b-single-unidirectional | 3.27 Gbps | 4.87 Mpps | 13.1 % |
| 64b-mpls-unidirectional | 6.18 Gbps | 9.20 Mpps | 24.7 % |
| 1514b-bidirectional | 24.59 Gbps | 2.00 Mpps | 49.2 % |
| 64b-bidirectional | 8.84 Gbps | 13.15 Mpps | 17.7 % |
| 64b-single-bidirectional | 5.57 Gbps | 8.29 Mpps | 11.1 % |
| 64b-mpls-bidirectional | 8.77 Gbps | 13.05 Mpps | 17.5 % |
Yikes! Cx5 in its default mode can still saturate 1514b loadtests, but turns into single digit with almost all other loadtest types. I’m surprised also that single flow loadtest clocks in at only 4.87Mpps, that’s about the same speed I sawwith the ConnectX-4 using DPDK. This does not look good at all, and honestly, I don’t believe it.
So I start fiddling with settings.
ConnectX-5 EN: Tuning Parameters
There are a few things I found that might speed up processing in the ConnectX network card:
- Allowing for larger PCI packets - by default 512b, I can raise this to 1k, 2k or even 4k.
setpci -s 0e:00.0 68.wwill return some hex number ABCD, the A here stands for max read size. 0=128b, 1=256b, 2=512b, 3=1k, 4=2k, 8=4k. I can set the value by writingsetpci -s 0e:00.0 68.w=3BCD, which immediately speeds up the loadtests! - Mellanox recommends to turn on CQE compression, to allow for the PCI messages to be aggressively
compressed, saving bandwidth. This helps specifically with smaller packets, as the PCI message
overhead really starts to matter.
mlxconfig -d 0e:00.0 set CQE_COMPRESSION=1and reboot. - For MPLS, the Cx5 can do flow matching on the inner packet (rather than hashing all packets to
the same queue based on the MPLS label) –
mlxconfig -d 0e:00.0 set FLEX_PARSER_PROFILE_ENABLE=1and reboot. - Likely the number of receive queues matters, and can be set in the
create interface rdmacommand.
I notice that CQE_COMPRESSION and FLEX_PARSER_PROFILE_ENABLE help in all cases, so I set them and
reboot. The PCI packets resizing also helps specifically with smaller packets, so I set that too in
/etc/rc.local. The fourth variable is left over, which is varying receive queue count.
Here’s a comparison that, to me at least, was surprising. With three receive queues, thus three CPU threads each receiving 4.7Mpps and sending 3.1Mpps, performance looked like this:
$ vppctl create interface rdma host-if enp14s0f0np0 name xxv0 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 3 mode dv no-multi-seg max-pktlen 2026
$ vppctl create interface rdma host-if enp14s0f1np1 name xxv1 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 3 mode dv no-multi-seg max-pktlen 2026
$ vppctl show run | grep vector\ rates | grep -v in\ 0
vector rates in 4.7586e6, out 3.2259e6, drop 3.7335e2, punt 0.0000e0
vector rates in 4.9881e6, out 3.2206e6, drop 3.8344e2, punt 0.0000e0
vector rates in 5.0136e6, out 3.2169e6, drop 3.7335e2, punt 0.0000e0
This is fishy - why is the inbound rate much higher than the outbound rate? The behavior is consistent in multi-queue setups. If I create 2 queues it’s 8.45Mpps in and 7.98Mpps out:
$ vppctl create interface rdma host-if enp14s0f0np0 name xxv0 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 2 mode dv no-multi-seg max-pktlen 2026
$ vppctl create interface rdma host-if enp14s0f1np1 name xxv1 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 2 mode dv no-multi-seg max-pktlen 2026
$ vppctl show run | grep vector\ rates | grep -v in\ 0
vector rates in 8.4533e6, out 7.9804e6, drop 0.0000e0, punt 0.0000e0
vector rates in 8.4517e6, out 7.9798e6, drop 0.0000e0, punt 0.0000e0
And when I create only one queue, the same appears:
$ vppctl create interface rdma host-if enp14s0f0np0 name xxv0 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 1 mode dv no-multi-seg max-pktlen 2026
$ vppctl create interface rdma host-if enp14s0f1np1 name xxv1 rx-queue-size 1024 tx-queue-size 4096
num-rx-queues 1 mode dv no-multi-seg max-pktlen 2026
$ vppctl show run | grep vector\ rates | grep -v in\ 0
vector rates in 1.2082e7, out 9.3865e6, drop 0.0000e0, punt 0.0000e0
But now that I’ve scaled down to only one queue (and thus one CPU thread doing all the work), I
manage to find a clue in the show runtime command:
Thread 1 vpp_wk_0 (lcore 1)
Time 321.1, 10 sec internal node vector rate 256.00 loops/sec 46813.09
vector rates in 1.2392e7, out 9.4015e6, drop 0.0000e0, punt 1.5571e-2
Name State Calls Vectors Suspends Clocks Vectors/Call
ethernet-input active 15543357 3979099392 0 2.79e1 256.00
ip4-input-no-checksum active 15543352 3979098112 0 1.26e1 256.00
ip4-load-balance active 15543357 3979099387 0 9.17e0 255.99
ip4-lookup active 15543357 3979099387 0 1.43e1 255.99
ip4-rewrite active 15543357 3979099387 0 1.69e1 255.99
rdma-input polling 15543357 3979099392 0 2.57e1 256.00
xxv1-output active 15543357 3979099387 0 5.03e0 255.99
xxv1-tx active 15543357 3018807035 0 4.35e1 194.22
It takes a bit of practice to spot this, but see how xx1-output is running at 256 vectors/call,
while xxv1-tx is running at only 194.22 vectors/call? That means that VPP is dutifully handling
the whole packet, but when it is handed off to RDMA to marshall onto the hardware, it’s getting
lost! And indeed, this is corroborated by show errors:
$ vppctl show err
Count Node Reason Severity
3334 null-node blackholed packets error
7421 ip4-arp ARP requests throttled info
3 ip4-arp ARP requests sent info
1454511616 xxv1-tx no free tx slots error
16 null-node blackholed packets error
Wow, billions of packets have been routed by VPP but then had to be discarded because RDMA output could not keep up. Ouch.
Compare the previous CPU utilization graph (from the Cx5/DPDK loadtest) with this Cx5/RDMA/1-RXQ loadtest:
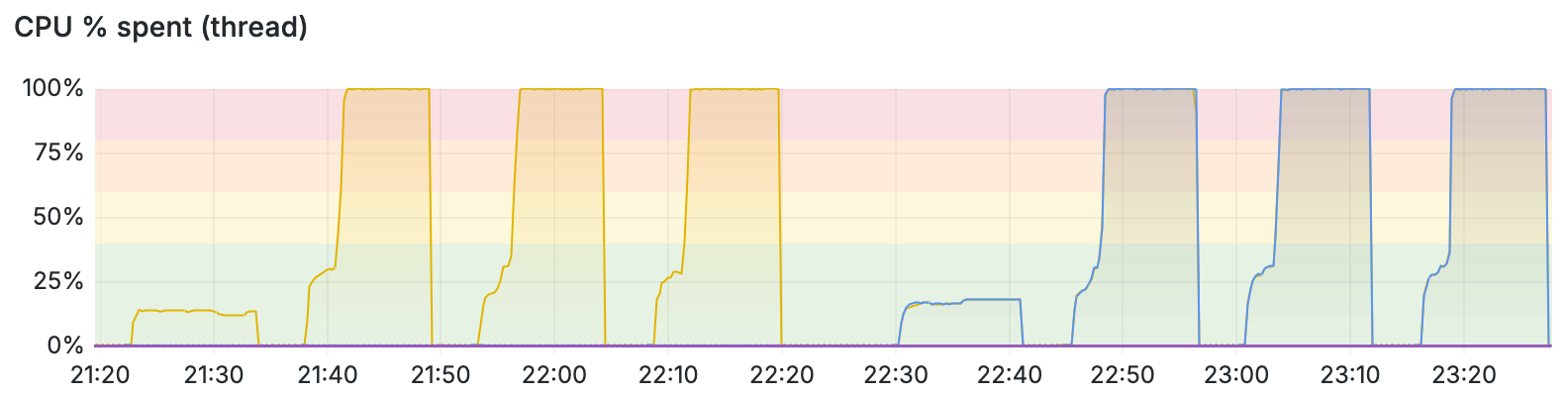
Here I can clearly see that the one CPU thread (in yellow for unidirectional) and the two CPU therads (one for each of the bidirectional flows) jump up to 100% and stay there. This means that when VPP is completely pegged, it is receiving 12.4Mpps per core, but only manages to get RDMA to send 9.40Mpps of those on the wire. The performance further deteriorates when multiple receive queues are in play. Note: 12.4Mpps is pretty great for these CPU threads.
Conclusion: Single Queue RDMA based Cx5 will allow for about 9Mpps per interface, which is a little bit better than DPDK performance; but Cx4 and Cx5 performance are not too far apart.
Summary and closing thoughts
Looking at the RDMA results for both Cx4 and Cx5, when using only one thread, gives fair performance
with very low CPU cost per port – however I could not manage to get rid of the no free tx slots
errors, and VPP can consume / process / forward more packets than RDMA is willing to marshall out on
the wire, which is disappointing.
That said, both RDMA and DPDK performance is line rate at 25G unidirectional with sufficiently large packets, and for small packets, it can realistically handle roughly 9Mpps per CPU thread. Considering the CPU has 8 threads – of which 6 usable by VPP – the machine has more CPU than it needs to drive the NICs. It should be a really great router at 10Gbps traffic rates, and a very fair router at 25Gbps either with RDMA or DPDK.
Here’s a few files I gathered along the way, in case they are useful:
- [LSCPU] - [Likwid Topology] - [DMI Decode] - [LSBLK]
- Mellanox MCX4421A-ACAN: [dmesg] - [LSPCI] - [LSHW]
- Mellanox MCX542B-ACAN: [dmesg] - [LSPCI] - [LSHW]
- VPP Configs: [startup.conf] - [L2 Config] - [L3 Config] - [MPLS Config]