- Author: Pim van Pelt <pim@ipng.nl>
- Reviewed: Jim Thompson <jim@netgate.com>
- Status: Draft - Review - Approved
A few weeks ago, Jim Thompson from Netgate stumbled across my APU6 Post and introduced me to their new desktop router/firewall the Netgate 6100. It currently ships with pfSense Plus, but he mentioned that it’s designed as well to run their TNSR software, considering the device ships with 2x 1GbE SFP/RJ45 combo, 2x 10GbE SFP+, and 4x 2.5GbE RJ45 ports, and all network interfaces are Intel / DPDK capable chips. He asked me if I was willing to take it around the block with VPP, which of course I’d be happy to do, and here are my findings. The TNSR image isn’t yet public for this device, but that’s not a problem because AS8298 runs VPP, so I’ll just go ahead and install it myself …
Executive Summary
The Netgate 6100 router running pfSense has a single core performance of 623kpps and a total chassis throughput of 2.3Mpps, which is sufficient for line rate in both directions at 1514b packets (1.58Mpps), about 6.2Gbit of imix traffic, and about 419Mbit of 64b packets. Running Linux on the router yields very similar results.
With VPP though, the router’s single core performance leaps to 5.01Mpps at 438 CPU cycles/packet. This means that all three of 1514b, imix and 64b packets can be forwarded at line rate in one direction on 10Gbit. Due to its Atom C3558 processor (which has 4 cores, 3 of which are dedicated to VPP’s worker threads, and 1 to its main thread and controlplane running in LInux), achieving 10Gbit line rate in both directions when using 64 byte packets, is not possible.
Running at 19W and a total forwarding capacity of 15.1Mpps, it consumes only 1.26µJ of energy per forwarded packet, while at the same time easily handling a full BGP table with room to spare. I find this Netgate 6100 appliance pretty impressive and when TNSR becomes available, performance will be similar to what I’ve tested here, at a pricetag of USD 699,-
Detailed findings

The Netgate 6100 ships with an Intel Atom C-3558 CPU (4 cores including AES-NI and QuickAssist), 8GB of memory and either 16GB of eMMC, or 128GB of NVME storage. The network cards are its main forté: it comes with 2x i354 gigabit combo (SFP and RJ45), 4x i225 ports (these are 2.5GbE), and 2x X553 10GbE ports with an SFP+ cage each, for a total of 8 ports and lots of connectivity.
The machine is fanless and this is made possible by its power efficient CPU: the Atom here runs at 16W TDP only, and the whole machine clocks in at a very efficient 19W. It comes with an external power brick, but only one power supply, so no redundancy, unfortunately. To make up for that small omission, here are a few nice touches that I noticed:
- The power jack has a screw-on barrel - no more accidentally rebooting the machine when fumbling around under the desk.
- There’s both a Cisco RJ45 console port (115200,8n1), as well as a CP2102 onboard USB/serial connector, which means you can connect to its serial port as well with a standard issue micro-USB cable. Cool!
Battle of Operating Systems
Netgate ships the device with pfSense - it’s a pretty great appliance and massively popular - delivering firewall, router and VPN functionality to homes and small business across the globe. I myself am partial to BSD (albeit a bit more of the Puffy persuasion), but DPDK and VPP are more of a Linux cup of tea. So I’ll have to deface this little guy, and reinstall it with Linux. My game plan is:
- Based on the shipped pfSense 21.05 (FreeBSD 12.2), do all the loadtests
- Reinstall the machine with Linux (Ubuntu 20.04.3), do all the loadtests
- Install VPP using my own HOWTO, and do all the loadtests
This allows for, I think, a pretty sweet comparison between FreeBSD, Linux, and DPDK/VPP. Now, on to a description on the defacing, err, reinstall process on this Netgate 6100 machine, as it was not as easy as I had anticipated (but is it ever easy, really?)
Turning on the device, it presents me with some BIOS firmware from Insyde Software which is loading some software called BlinkBoot [ref], which in turn is loading modules called Lenses, pictured right. Anyway, this ultimately presents me with a Press F2 for Boot Options. Aha! That’s exactly what I’m looking for. I’m really grateful that Netgate decides to ship a device with a BIOS that will allow me to boot off of other media, notably the USB stick in order to reinstall pfSense but in my case, also to install another operating system entirely.
My first approach was to get a default image to boot off of USB (the device has two USB3 ports on the
side). But none of the USB ports want to load my UEFI bootx64.efi prepared USB key. So my second
attempt was to prepare a PXE boot image, taking a few hints from Ubuntu’s documentation [ref]:
wget http://archive.ubuntu.com/ubuntu/dists/focal/main/installer-amd64/current/legacy-images/netboot/mini.iso
mv mini.iso /tmp/mini-focal.iso
grub-mkimage --format=x86_64-efi \
--output=/var/tftpboot/grubnetx64.efi.signed \
--memdisk=/tmp/mini-focal.iso \
`ls /usr/lib/grub/x86_64-efi | sed -n 's/\.mod//gp'`
After preparing DHCPd and a TFTP server, and getting a slight feeling of being transported back in time to the stone age, I see the PXE both request an IPv4 address, and the image I prepared. And, it boots, yippie!
Nov 25 14:52:10 spongebob dhcpd[43424]: DHCPDISCOVER from 90:ec:77:1b:63:55 via bond0
Nov 25 14:52:11 spongebob dhcpd[43424]: DHCPOFFER on 192.168.1.206 to 90:ec:77:1b:63:55 via bond0
Nov 25 14:52:13 spongebob dhcpd[43424]: DHCPREQUEST for 192.168.1.206 (192.168.1.254) from 90:ec:77:1b:63:55 via bond0
Nov 25 14:52:13 spongebob dhcpd[43424]: DHCPACK on 192.168.1.206 to 90:ec:77:1b:63:55 via bond0
Nov 25 15:04:56 spongebob tftpd[2076]: 192.168.1.206: read request for 'grubnetx64.efi.signed'
I took a peek while the grubnetx64 was booting, and saw that the available output terminals
on this machine are spkmodem morse gfxterm serial_efi0 serial_com0 serial cbmemc audio, and that
the default/active one is console, so I make a note that Grub wants to run on ‘console’ (and
specifically NOT on ‘serial’, as is usual, see below for a few more details on this) while the Linux
kernel will of course be running on serial, so I have to add console=ttyS0,115200n8 to the kernel boot
string before booting.
Piece of cake, by which I mean I spent about four hours staring at the boot loader and failing to get
it quite right – pro-tip: install OpenSSH and fix the GRUB and Kernel configs before finishing the
mini.iso install:
mount --bind /proc /target/proc
mount --bind /dev /target/dev
mount --bind /sys /target/sys
chroot /target /bin/bash
# Install OpenSSH, otherwise the machine boots w/o access :)
apt update
apt install openssh-server
# Fix serial for GRUB and Kernel
vi /etc/default/grub
## set GRUB_CMDLINE_LINUX_DEFAULT="console=ttyS0,115200n8"
## set GRUB_TERMINAL=console (and comment out the serial stuff)
grub-install /dev/sda
update-grub
Rebooting now brings me to Ubuntu: Pat on the back, Caveman Pim, you’ve still got it!
Network Loadtest
After that small but exciting detour, let me get back to the loadtesting. The choice of Intel’s network controller on this board allows me to use Intel’s DPDK with relatively high performance, compared to regular (kernel) based routing. I loadtested the stock firmware pfSense (21.05, based on FreeBSD 12.2), Linux (Ubuntu 20.04.3), and VPP (22.02, [ref]).
Specifically worth calling out is that while Linux and FreeBSD struggled in the packets-per-second
department, the use of DPDK in VPP meant absolutely no problems filling a unidirectional 10G stream
of “regular internet traffic” (referred to as imix), it was also able to fill line rate with
“64b UDP packets”, with just a little headroom there, but it ultimately struggled with bidirectional
64b UDP packets.
Methodology
For the loadtests, I used Cisco’s T-Rex [ref] in stateless mode,
with a custom Python controller that ramps up and down traffic from the loadtester to the device
under test (DUT) by sending traffic out port0 to the DUT, and expecting that traffic to be
presented back out from the DUT to its port1, and vice versa (out from port1 -> DUT -> back
in on port0). The loadtester first sends a few seconds of warmup, this is to ensure the DUT is
passing traffic and offers the ability to inspect the traffic before the actual rampup. Then
the loadtester ramps up linearly from zero to 100% of line rate (in this case, line rate is
10Gbps in both directions), finally it holds the traffic at full line rate for a certain
duration. If at any time the loadtester fails to see the traffic it’s emitting return on its
second port, it flags the DUT as saturated; and this is noted as the maximum bits/second and/or
packets/second.
Since my last loadtesting post, I’ve learned a lot more about packet forwarding and how to make it easier or harder on the router. Let me go into a few more details about the various loadtests that I’ve done here.
Method 1: Single CPU Thread Saturation
Most kernels (certainly OpenBSD, FreeBSD and Linux) will make use of multiple receive queues if the network card supports it. The Intel NICs in this machine are all capable of Receive Side Scaling (RSS), which means the NIC can offload its packets into multiple queues. The kernel will typically enable one queue for each CPU core – the Atom has 4 cores, so 4 queues are initialized, and inbound traffic is sent, typically using some hashing function, to individual CPUs, allowing for a higher aggregate throughput.
Mostly, this hashing function is based on some L3 or L4 payload, for example a hash over the source IP/port and destination IP/port. So one interesting test is to send the same packet over and over again – the hash function will then return the same value for each packet, which means all traffic goes into exactly one of the N available queues, and therefore handled by only one core.
One such TRex stateless traffic profile is udp_1pkt_simple.py which, as the name implies,
simply sends the same UDP packet from source IP/port and destination IP/port, padded with
a bunch of ‘x’ characters, over and over again:
packet = STLPktBuilder(pkt =
Ether()/
IP(src="16.0.0.1",dst="48.0.0.1")/
UDP(dport=12,sport=1025)/(10*'x')
)
Method 2: Rampup using trex-loadtest.py
TRex ships with a very handy bench.py stateless traffic profile which, without any additional
arguments, does the same thing as the above method. However, this profile optionally takes a few
arguments, which are called tunables, notably:
- size - set the size of the packets to either a number (ie. 64, the default, or any number
up to a maximum of 9216 byes), or the string
imixwhich will send a traffic mix consisting of 60b, 590b and 1514b packets. - vm - set the packet source/dest generation. By default (when the flag is
None), the same src (16.0.0.1) and dst (48.0.0.1) is set for each packet. When setting the value tovar1, the source IP is incremented from16.0.0.[4-254]. If the value is set tovar2, the source and destination IP are incremented, the destination from48.0.0.[4-254].
So tinkering with the vm parameter is an excellent way of driving one or many receive queues. Armed
with this, I will perform a loadtest with four modes of interest, from easier to more challenging:
- bench-var2-1514b: multiple flows, ~815Kpps at 10Gbps; this is the easiest test to perform, as the traffic consists of large (1514 byte) packets, and both source and destination are different each time, which means lots of multiplexing across receive queues, and relatively few packets/sec.
- bench-var2-imix: multiple flows, with a mix of 60, 590 and 1514b frames in a certain ratio. This yields what can be reasonably expected from normal internet use, just about 3.2Mpps at 10Gbps. This is the most representative test for normal use, but still the packet rate is quite low due to (relatively) large packets. Any respectable router should be able to perform well at an imix profile.
- bench-var2-64b: Still multiple flows, but very small packets, 14.88Mpps at 10Gbps, often refered to as the theoretical maximum throughput on Tengig. Now it’s getting harder, as the loadtester will fill the line with small packets (of 64 bytes, the smallest that an ethernet packet is allowed to be). This is a good way to see if the router vendor is actually capable of what is referred to as line rate forwarding.
- bench: Now restricted to a constant src/dst IP:port tuple, and the same rate of 14.88Mpps at 10Gbps, means only one Rx queue (and thus, one CPU core) can be used. This is where single-core performance becomes relevant. Notably, vendors who boast many CPUs, will often struggle with a test like this, in case any given CPU core cannot individually handle a full line rate. I’m looking at you, Tilera!
Further to this list, I can send traffic in one direction only (TRex will emit this from its port0 and expect the traffic to be seen back at port1); or I can send it in both directions. The latter will double the packet rate and bandwidth, to approx 29.7Mpps.
NOTE: At these rates, TRex can be a bit fickle trying to fit all these packets into its own transmit queues, so I decide to drive it a bit less close to the cliff and stop at 97% of line rate (this is 28.3Mpps). It explains why lots of these loadtests top out at that number.
Results
Method 1: Single CPU Thread Saturation
Given the approaches above, for the first method I can “just” saturate the line and see how many packets emerge through the DUT on the other port, so that’s only 3 tests:
| Netgate 6100 | Loadtest | Throughput (pps) | L1 Throughput (bps) | % of linerate |
|---|---|---|---|---|
| pfSense | 64b 1-flow | 622.98 Kpps | 418.65 Mbps | 4.19% |
| Linux | 64b 1-flow | 642.71 Kpps | 431.90 Mbps | 4.32% |
| VPP | 64b 1-flow | 5.01 Mpps | 3.37 Gbps | 33.67% |
NOTE: The bandwidth figures here are so called L1 throughput which means bits on the wire, as opposed to L2 throughput which means bits in the ethernet frame. This is relevant particularly at 64b loadtests as the overhead for each ethernet frame is 20 bytes (7 bytes preamble, 1 byte start-frame, and 12 bytes inter-frame gap [ref]). At 64 byte frames, this is 31.25% overhead! It also means that when L1 bandwidth is fully consumed at 10Gbps, that the observed L2 bandwidth will be only 7.62Gbps.
Interlude - VPP efficiency
In VPP it can be pretty cool to take a look at efficiency – one of the main reasons why it’s so quick is because VPP will consume the entire core, and grab a set of packets from the NIC rather than do work for each individual packet. VPP then advances the set of packets, called a vector, through a directed graph. The first of these packets will result in the code for the current graph node to be fetched into the CPU’s instruction cache, and the second and further packets will make use of the warmed up cache, greatly improving per-packet efficiency.
I can demonstrate this by running a 1kpps, 1Mpps and 10Mpps test against the VPP install on this router, and
observing how many CPU cycles each packet needs to get forwarded from the input interface to the output interface.
I expect this number to go down when the machine has more work to do, due to the higher CPU i/d-cache hit rate.
Seeing the time spent in each of VPP’s graph nodes, and for each individual worker thread (which correspond 1:1
with CPU cores), can be done with vppctl show runtime command and some awk magic:
$ vppctl clear run && sleep 30 && vppctl show run | \
awk '$2 ~ /active|polling/ && $4 > 25000 {
print $0;
if ($1=="ethernet-input") { packets = $4};
if ($1=="dpdk-input") { dpdk_time = $6};
total_time += $6
} END {
print packets/30, "packets/sec, at",total_time,"cycles/packet,",
total_time-dpdk_time,"cycles/packet not counting DPDK"
}'
This gives me the following, somewhat verbose but super interesting output, which I’ve edited down to fit on screen, and omit the columns that are not super relevant. Ready? Here we go!
tui>start -f stl/udp_1pkt_simple.py -p 0 -m 1kpps
Graph Node Name Clocks Vectors/Call
----------------------------------------------------------------
TenGigabitEthernet3/0/1-output 6.07e2 1.00
TenGigabitEthernet3/0/1-tx 8.61e2 1.00
dpdk-input 1.51e6 0.00
ethernet-input 1.22e3 1.00
ip4-input-no-checksum 6.59e2 1.00
ip4-load-balance 4.50e2 1.00
ip4-lookup 5.63e2 1.00
ip4-rewrite 5.83e2 1.00
1000.17 packets/sec, at 1514943 cycles/packet, 4943 cycles/pkt not counting DPDK
I’ll observe that a lot of time is spent in dpdk-input, because that is a node that is constantly polling
the network card, as fast as it can, to see if there’s any work for it to do. Apparently not, because the average
vectors per call is pretty much zero, and considering that, most of the CPU time is going to sit in a nice “do
nothing”. Because reporting CPU cycles spent doing nothing isn’t particularly interesting, I shall report on
both the total cycles spent, that is to say including DPDK, and as well the cycles spent per packet in the
other active nodes. In this case, at 1kpps, VPP is spending 4953 cycles on each packet.
Now, take a look what happens when I raise the traffic to 1Mpps:
tui>start -f stl/udp_1pkt_simple.py -p 0 -m 1mpps
Graph Node Name Clocks Vectors/Call
----------------------------------------------------------------
TenGigabitEthernet3/0/1-output 3.80e1 18.57
TenGigabitEthernet3/0/1-tx 1.44e2 18.57
dpdk-input 1.15e3 .39
ethernet-input 1.39e2 18.57
ip4-input-no-checksum 8.26e1 18.57
ip4-load-balance 5.85e1 18.57
ip4-lookup 7.94e1 18.57
ip4-rewrite 7.86e1 18.57
981830 packets/sec, at 1770.1 cycles/packet, 620 cycles/pkt not counting DPDK
Whoa! The system is now running the VPP loop with ~18.6 packets per vector, and you can clearly see that the CPU efficiency went up greatly, from 4953 cycles/packet at 1kpps, to 620 cycles/packet at 1Mpps. That’s an order of magnitude improvement!
Finally, let’s give this Netgate 6100 router a run for its money, and slam it with 10Mpps:
tui>start -f stl/udp_1pkt_simple.py -p 0 -m 10mpps
Graph Node Name Clocks Vectors/Call
----------------------------------------------------------------
TenGigabitEthernet3/0/1-output 1.41e1 256.00
TenGigabitEthernet3/0/1-tx 1.23e2 256.00
dpdk-input 7.95e1 256.00
ethernet-input 6.74e1 256.00
ip4-input-no-checksum 3.95e1 256.00
ip4-load-balance 2.54e1 256.00
ip4-lookup 4.12e1 256.00
ip4-rewrite 4.78e1 256.00
5.01426e+06 packets/sec, at 437.9 cycles/packet, 358 cycles/pkt not counting DPDK
And here is where I learn the maximum packets/sec that this one CPU thread can handle: 5.01Mpps, at which point every packet is super efficiently handled at 358 CPU cycles each, or 13.8 times (4953/438) as efficient under high load than when the CPU is unloaded. Sweet!!
Another really cool thing to do here is derive the effective clock speed of the Atom CPU. We know it runs at 2200Mhz, and we’re doing 5.01Mpps at 438 cycles/packet including the time spent in DPDK, which adds up to 2194MHz, remarkable precision. Color me impressed :-)
Method 2: Rampup using trex-loadtest.py
For the second methodology, I have to perform a lot of loadtests. In total, I’m testing 4 modes (1514b, imix, 64b-multi and 64b 1-flow), then take a look at unidirectional traffic and bidirectional traffic, and perform each of these loadtests on pfSense, Ubuntu, and VPP with one, two or three Rx/Tx queues. That’s a total of 40 loadtests!
| Loadtest | pfSense | Ubuntu | VPP 1Q | VPP 2Q | VPP 3Q | Details |
|---|---|---|---|---|---|---|
| Unidirectional | ||||||
| 1514b | 97% | 97% | 97% | 97% | 97% | [graphs] |
| imix | 61% | 75% | 96% | 95% | 95% | [graphs] |
| 64b | 15% | 17% | 33% | 66% | 96% | [graphs] |
| 64b 1-flow | 4.4% | 4.7% | 33% | 33% | 33% | [graphs] |
| Bidirectional | ||||||
| 1514b | 192% | 193% | 193% | 193% | 194% | [graphs] |
| imix | 63% | 71% | 190% | 190% | 191% | [graphs] |
| 64b | 15% | 16% | 61% | 63% | 81% | [graphs] |
| 64b 1-flow | 8.6% | 9.0% | 61% | 61% | 33% (+) | [graphs] |
A picture says a thousand words - so I invite you to take a look at the interactive graphs from the table above. I’ll cherrypick what I find the most interesting one here:
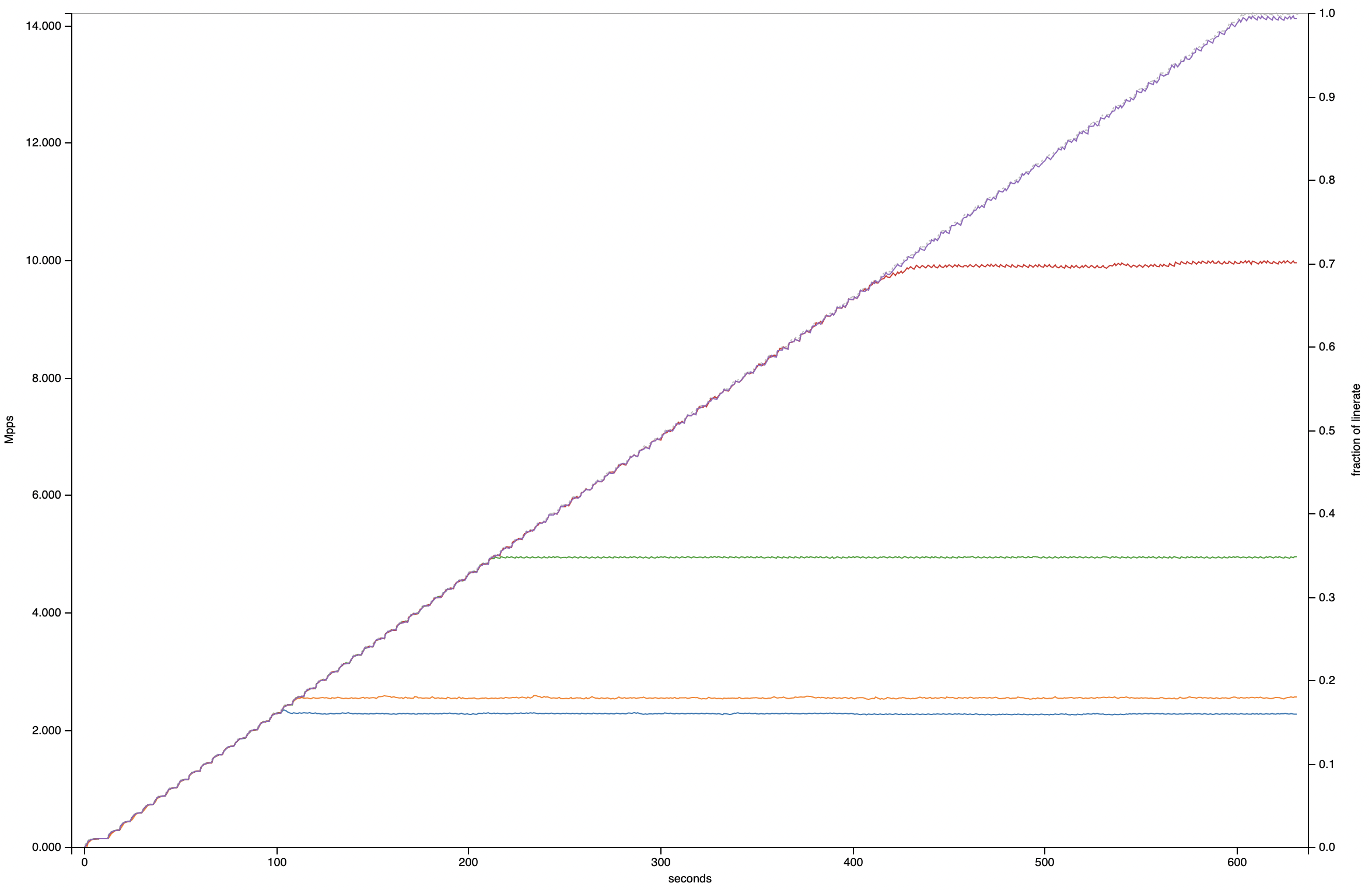
The graph above is of the unidirectional 64b loadtest. Some observations:
- pfSense 21.05 (running FreeBSD 12.2, the bottom blue trace), and Ubuntu 20.04.3 (running Linux 5.13, the orange trace just above it) are are equal performers. They handle fullsized (1514 byte) packets just fine, struggle a little bit with imix, and completely suck at 64b packets (shown here), in particular if only 1 CPU core can be used.
- Even at 64b packets, VPP scales linearly from 33% of line rate with 1Q (the green trace), 66% with 2Q (the red trace) and 96% with 3Q (the purple trace, that makes it through to the end).
- With VPP taking 3Q, one CPU is left over for the main thread and controlplane software like FRR or Bird2.
Caveats
The unit was shipped courtesy of Netgate (thanks again! Jim, this was fun!) for the purposes of load- and systems integration testing and comparing their internal benchmarking with my findings. Other than that, this is not a paid endorsement and views of this review are my own.
One quirk I noticed is that while running VPP with 3Q and bidirectional traffic, performance is much worse than with 2Q or 1Q. This is not a fluke with the loadtest, as I have observed the same strange performance with other machines (Supermicro 5018D-FN8T for example). I confirmed that each VPP worker thread is used for each queue, so I would’ve expected ~15Mpps shared by both interfaces (so a per-direction linerate of ~50%), but I get 16.8% instead [graphs]. I’ll have to understand that better, but for now I’m releasing the data as-is.
Appendix
Generating the data
You can find all of my loadtest runs in this archive.
The archive contains the trex-loadtest.py script as well, for curious readers!
These JSON files can be fed directly into Michal’s visualizer
to plot interactive graphs (which I’ve done for the table above):
DEVICE=netgate-6100
ruby graph.rb -t 'Netgate 6100 All Loadtests' -o ${DEVICE}.html netgate-*.json
for i in bench-var2-1514b bench-var2-64b bench imix; do
ruby graph.rb -t 'Netgate 6100 Unidirectional Loadtests' --only-channels 0 \
netgate-*-${i}-unidi*.json -o ${DEVICE}.$i-unidirectional.html
done
for i in bench-var2-1514b bench-var2-64b bench imix; do
ruby graph.rb -t 'Netgate 6100 Bidirectional Loadtests' \
netgate-*-${i}.json -o ${DEVICE}.$i-bidirectional.html
done
Notes on pfSense
I’m not a pfSense user, but I know my way around FreeBSD just fine. After installing the firmware, I
simply choose the ‘Give me a Shell’ option, and take it from there. The router will run pf out of
the box, and it is pretty complex, so I’ll just configure some addresses, routes and disable the
firewall alltogether. That sounds just fair, as the same tests with Linux and VPP also do not use
a firewall (even though obviously, both VPP and Linux support firewalls just fine).
ifconfig ix0 inet 100.65.1.1/24
ifconfig ix1 inet 100.65.2.1/24
route add -net 16.0.0.0/8 100.65.1.2
route add -net 48.0.0.0/8 100.65.2.2
pfctl -d
Notes on Linux
When doing loadtests on Ubuntu, I have to ensure irqbalance is turned off, otherwise the kernel will thrash around re-routing softirq’s between CPU threads, and at the end of the day, I’m trying to saturate all CPUs anyway, so balancing/moving them around doesn’t make any sense. Further, Linux wants to configure a static ARP entry for the interfaces from TRex:
sudo systemctl disable irqbalance
sudo systemctl stop irqbalance
sudo systemctl mask irqbalance
sudo ip addr add 100.65.1.1/24 dev enp3s0f0
sudo ip addr add 100.65.2.1/24 dev enp3s0f1
sudo ip nei replace 100.65.1.2 lladdr 68:05:ca:32:45:94 dev enp3s0f0 ## TRex port0
sudo ip nei replace 100.65.2.2 lladdr 68:05:ca:32:45:95 dev enp3s0f1 ## TRex port1
sudo ip ro add 16.0.0.0/8 via 100.65.1.2
sudo ip ro add 48.0.0.0/8 via 100.65.2.2
On Linux, I now see a reasonable spread of IRQs by CPU while doing a unidirectional loadtest:
root@netgate:/home/pim# cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 3 0 0 1
TIMER: 203788 247280 259544 401401
NET_TX: 8956 8373 7836 6154
NET_RX: 22003822 19316480 22526729 19430299
BLOCK: 2545 3153 2430 1463
IRQ_POLL: 0 0 0 0
TASKLET: 5084 60 1830 23
SCHED: 137647 117482 56371 49112
HRTIMER: 0 0 0 0
RCU: 11550 9023 8975 8075