After receiving an e-mail from a newer [China based OEM], I had a chat with their founder and learned that the combination of switch silicon and software may be a good match for IPng Networks.
I got pretty enthusiastic when this new vendor claimed VxLAN, GENEVE, MPLS and GRE at 56 ports and line rate, on a really affordable budget ($4'200,- for the 56 port; and $1'650,- for the 26 port switch). This reseller is using a less known silicon vendor called [Centec], who have a lineup of ethernet silicon. In this device, the CTC8096 (GoldenGate) is used for cost effective high density 10GbE/40GbE applications paired with 4x100GbE uplink capability. This is Centec’s fourth generation, so CTC8096 inherits the feature set from L2/L3 switching to advanced data center and metro Ethernet features with innovative enhancement. The switch chip provides up to 96x10GbE ports, or 24x40GbE, or 80x10GbE + 4x100GbE ports, inheriting from its predecessors a variety of features, including L2, L3, MPLS, VXLAN, MPLS SR, and OAM/APS. Highlights features include Telemetry, Programmability, Security and traffic management, and Network time synchronization.


After discussing basic L2, L3 and Overlay functionality in my [previous post], I left somewhat of a cliffhanger alluding to all this fancy MPLS and VPLS stuff. Honestly, I needed a bit more time to play around with the featureset and clarify a few things. I’m now ready to assert that this stuff is really possible on this switch, and if this tickles your fancy, by all means read on :)
Detailed findings
Hardware

The switch comes well packaged with two removable 400W Gold powersupplies from Compuware
Technology which output 12V/33A and +5V/3A as well as four removable PWM controlled fans from
Protechnic. The switch chip is a Centec
[CTC8096] which is a competent silicon unit that can offer
48x10, 2x40 and 4x100G, and its smaller sibling carries the newer
[CTC7132] from 2019, which brings
24x10 and 2x100G connectivity. While the firmware seems slightly different in denomination, the large
one shows NetworkOS-e580-v7.4.4.r.bin as the firmware, and the smaller one shows
uImage-v7.0.4.40.bin, I get the impression that the latter is a compiled down version of the
former to work with the newer chipset.
In my [previous post], I showed L2, L3 and VxLAN, GENEVE and NvGRE capabilities of this switch to be line rate. But the hardware also supports MPLS, so I figured I’d complete the Overlay series by exploring VxLAN, and the MPLS, EoMPLS (L2VPN, Martini style), and VPLS functionality of these units.
Topology
 {: style=“width:500px; float: right; margin-left: 1em;
margin-bottom: 1em;”}
{: style=“width:500px; float: right; margin-left: 1em;
margin-bottom: 1em;”}
In the [IPng Networks LAB], I build the following topology using the loadtester, packet analyzer, and switches:
- msw-top: S5624-2Z-EI switch
- msw-core: S5648X-2Q4ZA switch
- msw-bottom: S5624-2Z-EI switch
- All switches connect to:
- each other with 100G DACs (right, black)
- T-Rex machine with 4x10G (left, rainbow)
- Each switch gets a mgmt IPv4 and IPv6
This is the same topology in the previous post, and it gives me lots of wiggle room to patch anything to anything as I build point to point MPLS tunnels, VPLS clouds and eVPN overlays. Although I will also load/stress test these configurations, this post is more about the higher level configuration work that goes into building such an MPLS enabled telco network.
MPLS
Why even bother, if we have these fancy new IP based transports that I [wrote about] last week? I mentioned that the industry is moving on from MPLS to a set of more flexible IP based solutions like VxLAN and GENEVE, as they certainly offer lots of benefits in deployment (notably as overlays on top of existing IP networks).
Here’s one plausible answer: You may have come across an architectural network design concept known as [BGP Free Core] and operating this way gives very little room for outages to occur in the L2 (Ethernet and MPLS) transport network, because it’s relatively simple in design and implementation. Some advantages worth mentioning:
- Transport devices do not need to be capable of supporting a large number of IPv4/IPv6 routes, either in the RIB or FIB, allowing them to be much cheaper.
- As there is no eBGP, transport devices will not be impacted by BGP-related issues, such as high CPU utilization during massive BGP re-convergence.
- Also, without eBGP, some of the attack vectors in ISPs (loopback DDoS or ARP storms on public internet exchange, to take two common examples) can be eliminated. If a new BGP security vulnerability were to be discovered, transport devices aren’t impacted.
- Operator errors (the #1 reason for outages in our industry) associated with BGP configuration and the use of large RIBs (eg. leaking into IGP, flapping transit sessions, etc) can be eradicated.
- New transport services such as MPLS point to point virtual leased lines, SR-MPLS, VPLS clouds, and eVPN can all be introduced without modifying the routing core.
If deployed correctly, this type of transport-only network can be kept entirely isolated from the Internet, making DDoS and hacking attacks against transport elements impossible, and it also opens up possibilities for relatively safe sharing of infrastructure resources between ISPs (think of things like dark fibers between locations, rackspace, power, cross connects).
For smaller clubs (like IPng Networks), being able to share a 100G wave with others, significantly reduces price per Megabit! So if you’re in Zurich, Switzerland, or Europe and find this an interesting avenue to expand your reach in a co-op style environment, [reach out] to us, any time!
MPLS + LDP Configuration
OK, let’s talk bits and bytes. Table stakes functionality is of course MPLS switching and label distribution, which is performed with LDP, described in [RFC3036]. Enabling these features is relatively straight forward:
msw-top# show run int loop0
interface loopback0
ip address 172.20.0.2/32
ipv6 address 2001:678:d78:400::2/128
ipv6 router ospf 8298 area 0
msw-top# show run int eth-0-25
interface eth-0-25
description Core: msw-bottom eth-0-25
speed 100G
no switchport
mtu 9216
label-switching
ip address 172.20.0.12/31
ipv6 address 2001:678:d78:400::3:1/112
ip ospf network point-to-point
ip ospf cost 104
ipv6 ospf network point-to-point
ipv6 ospf cost 106
ipv6 router ospf 8298 area 0
enable-ldp
msw-top# show run router ospf
router ospf 8298
network 172.20.0.0/24 area 0
msw-top# show run router ipv6 ospf
router ipv6 ospf 8298
router-id 172.20.0.2
msw-top# show run router ldp
router ldp
router-id 172.20.0.2
transport-address 172.20.0.2
This seems like a mouthful, but really not too complicated. From the top, I create a loopback interface with an IPv4 (/32) and IPv6 (/128) address. Then, on the 100G transport interfaces, I specify an IPv4 (/31, let’s not be wasteful, take a look at [RFC 3021]) and IPv6 (/112) transit network, after which I add the interface to OSPF and OSPFv3.
The main two things to note in the interface definition is the use of label-switching which enables
MPLS on the interface, and enable-ldp which makes it periodically multicast LDP discovery
packets. If another device is also doing that, an LDP adjacency is formed using a TCP session.
The two devices then exchange MPLS label tables, so that they learn from each other how to switch
MPLS packets across the network.
LDP signalling kind of looks like this on the wire:
14:21:43.741089 IP 172.20.0.12.646 > 224.0.0.2.646: LDP, Label-Space-ID: 172.20.0.2:0, pdu-length: 30
14:21:44.331613 IP 172.20.0.13.646 > 224.0.0.2.646: LDP, Label-Space-ID: 172.20.0.1:0, pdu-length: 30
14:21:44.332773 IP 172.20.0.2.36475 > 172.20.0.1.646: Flags [S],seq 195175, win 27528,
options [mss 9176,sackOK,TS val 104349486 ecr 0,nop,wscale 7], length 0
14:21:44.333700 IP 172.20.0.1.646 > 172.20.0.2.36475: Flags [S.], seq 466968, ack 195176, win 18328,
options [mss 9176,sackOK,TS val 104335979 ecr 104349486,nop,wscale 7], length 0
14:21:44.334313 IP 172.20.0.2.36475 > 172.20.0.1.646: Flags [.], ack 1, win 216,
options [nop,nop,TS val 104349486 ecr 104335979], length 0
The first two packets here are the routers announcing to [well known
multicast] address for all-routers (224.0.0.2),
and well known port 646 (for LDP), in a packet called a Hello Message. The router with
address 172.20.0.12 is the one we just configured (msw-top), and the one with address 172.20.0.13 is
the other side (msw-bottom). In these Hello messages, the router informs multicast listeners
where they should connect (called the IPv4 transport address), in the case of msw-top, it’s
172.20.0.2.
Now that they’ve noticed one anothers willingness to form an adjacency, a TCP connection is
initiated from our router’s loopback address (specified by transport-address in the LDP
configuration), towards the loopback that was learned from the Hello Message in the multicast
packet earlier. A TCP three way handshake follows, in which the routers also tell each other their
MTU (by means of the MSS field set to 9176, which is 9216 minus 20 bytes [IPv4
header] and 20 bytes [TCP
header]). The adjacency forms and both
routers exchange label information (in things called a Label Mapping Message). Once done
exchanging this info, msw-top can now switch MPLS packets across its two 100G interfaces.
Zooming back out from what happened on the wire with the LDP signalling, I can take a look at the
msw-top switch: besides the adjacency that I described in detail above, another one has formed over
the IPv4 transit network between msw-top and msw-core (refer to the topology diagram to see what
connects where). As this is a layer3 network, icky things like spanning tree and forwarding loops
are no longer an issue. Any switch can forward MPLS packets to any neighbor in this topology, preference
on the used path is informed with OSPF costs for the IPv4 interfaces (because LDP is using IPv4 here).
msw-top# show ldp adjacency
IP Address Intf Name Holdtime LDP-Identifier
172.20.0.10 eth-0-26 15 172.20.0.1:0
172.20.0.13 eth-0-25 15 172.20.0.0:0
msw-top# show ldp session
Peer IP Address IF Name My Role State KeepAlive
172.20.0.0 eth-0-25 Active OPERATIONAL 30
172.20.0.1 eth-0-26 Active OPERATIONAL 30
MPLS pseudowire
The easiest form (and possibly most widely used one), is to create a point to point ethernet link betwen an interface on one switch, through the MPLS network, and into another switch’s interface on the other side. Think of this as a really long network cable. Ethernet frames are encapsulated into an MPLS frame, and passed through the network though some sort of tunnel, called a pseudowire.
There are many names of this tunneling technique. Folks refer to them as PWs (PseudoWires), VLLs (Virtual Leased Lines), Carrier Ethernet, or Metro Ethernet. Luckily, these are almost always interoperable, because under the covers, the vendors are implementing these MPLS cross connect circuits using [Martini Tunnels] which were formalized in [RFC 4447].
The way Martini tunnels work is by creating an extension in LDP signalling. An MPLS label-switched-path is annotated as being of a certain type, carrying a 32 bit pseudowire ID, which is ignored by all intermediate routers (they will just switch the MPLS packet onto the next hop), but the last router will inspect the MPLS packet and find which pseudowire ID it belongs to, and look up in its local table what to do with it (mostly just unwrap the MPLS packet, and marshall the resulting ethernet frame into an interface or tagged sub-interface).
Configuring the pseudowire is really simple:
msw-top# configure terminal
interface eth-0-1
mpls-l2-circuit pw-vll1 ethernet
!
mpls l2-circuit pw-vll1 829800 172.20.0.0 raw mtu 9000
msw-top# show ldp mpls-l2-circuit 829800
Transport Client VC Trans Local Remote Destination
VC ID Binding State Type VC Label VC Label Address
829800 eth-0-1 UP Ethernet 32774 32773 172.20.0.0
After I’ve configured this on both msw-top and msw-bottom, using LDP signalling, a new LSP will be
set up which carries ethernet packets at up to 9000 bytes, encapsulated MPLS, over the network. To
show this in more detail, I’ll take the two ethernet interfaces that are connected to msw-top:eth-0-1
and msw-bottom:eth-0-1, and move them in their own network namespace on the lab machine:
root@dut-lab:~# ip netns add top
root@dut-lab:~# ip netns add bottom
root@dut-lab:~# ip link set netns top enp66s0f0
root@dut-lab:~# ip link set netns bottom enp66s0f1
I can now enter the top and bottom namespaces, and play around with those interfaces, for example I’ll give them an IPv4 address and a sub-interface with dot1q tag 1234 and an IPv6 address:
root@dut-lab:~# nsenter --net=/var/run/netns/bottom
root@dut-lab:~# ip addr add 192.0.2.1/31 dev enp66s0f1
root@dut-lab:~# ip link add link enp66s0f1 name v1234 type vlan id 1234
root@dut-lab:~# ip addr add 2001:db8::2/64 dev v1234
root@dut-lab:~# ip link set v1234 up
root@dut-lab:~# nsenter --net=/var/run/netns/top
root@dut-lab:~# ip addr add 192.0.2.0/31 dev enp66s0f0
root@dut-lab:~# ip link add link enp66s0f0 name v1234 type vlan id 1234
root@dut-lab:~# ip addr add 2001:db8::1/64 dev v1234
root@dut-lab:~# ip link set v1234 up
root@dut-lab:~# ping -c 5 2001:db8::2
PING 2001:db8::2(2001:db8::2) 56 data bytes
64 bytes from 2001:db8::2: icmp_seq=1 ttl=64 time=0.158 ms
64 bytes from 2001:db8::2: icmp_seq=2 ttl=64 time=0.155 ms
64 bytes from 2001:db8::2: icmp_seq=3 ttl=64 time=0.162 ms
The mpls-l2-circuit that I created will transport the received ethernet frames between enp66s0f0
(in the top namespace) and enp66s0f1 (in the bottom namespace), using MPLS encapsulation, and
giving the packets a stack of two labels. The outer most label helps the switches determine where
to switch the MPLS packet (in other words, route it from msw-top to msw-bottom). Once the
destination is reached, the outer label is popped off the stack, to reveal the second label, the
purpose of which is to tell the msw-bottom switch what, preciesly, to do with this payload. The
switch will find that the second label instructs it to transmit the MPLS payload as an ethernet
frame out on port eth-0-1.
If I want to look at what happens on the wire with tcpdump(8), I can use the monitor port on
msw-core which mirrors all packets transiting through it. But, I don’t get very far:
root@dut-lab:~# tcpdump -evni eno2 mpls
19:57:37.055854 00:1e:08:0d:6e:88 > 00:1e:08:26:ec:f3, ethertype MPLS unicast (0x8847), length 144:
MPLS (label 32768, exp 0, ttl 255) (label 32773, exp 0, [S], ttl 255)
0x0000: 9c69 b461 7679 9c69 b461 7678 8100 04d2 .i.avy.i.avx....
0x0010: 86dd 6003 4a42 0040 3a40 2001 0db8 0000 ..`.JB.@:@......
0x0020: 0000 0000 0000 0000 0001 2001 0db8 0000 ................
0x0030: 0000 0000 0000 0000 0002 8000 3553 9326 ............5S.&
0x0040: 0001 2185 9363 0000 0000 e7d9 0000 0000 ..!..c..........
0x0050: 0000 1011 1213 1415 1617 1819 1a1b 1c1d ................
0x0060: 1e1f 2021 2223 2425 2627 2829 2a2b 2c2d ...!"#$%&'()*+,-
0x0070: 2e2f 3031 3233 3435 3637 ./01234567
19:57:37.055890 00:1e:08:26:ec:f3 > 00:1e:08:0d:6e:88, ethertype MPLS unicast (0x8847), length 140:
MPLS (label 32774, exp 0, [S], ttl 254)
0x0000: 9c69 b461 7678 9c69 b461 7679 8100 04d2 .i.avx.i.avy....
0x0010: 86dd 6009 4122 0040 3a40 2001 0db8 0000 ..`.A".@:@......
0x0020: 0000 0000 0000 0000 0002 2001 0db8 0000 ................
0x0030: 0000 0000 0000 0000 0001 8100 3453 9326 ............4S.&
0x0040: 0001 2185 9363 0000 0000 e7d9 0000 0000 ..!..c..........
0x0050: 0000 1011 1213 1415 1617 1819 1a1b 1c1d ................
0x0060: 1e1f 2021 2223 2425 2627 2829 2a2b 2c2d ...!"#$%&'()*+,-
0x0070: 2e2f 3031 3233 3435 3637 ./01234567
For a brief moment, I stare closely at the first part of the hex dump, and I recognize two MAC addresses
9c69.b461.7678 and 9c69.b461.7679 followed by what appears to be 0x8100 (the ethertype for
[Dot1Q]) and then 0x04d2 (which is 1234 in decimal,
the VLAN tag I chose).
Clearly, the hexdump here is “just” an ethernet frame. So why doesn’t tcpdump decode it? The answer is simple: nothing in the MPLS packet tells me that the payload is actually ethernet. It could be anything, and it’s really up to the recipient of the packet with the label 32773 to determine what its payload means. Luckily, Wireshark can be prompted to decode further based on which MPLS label is present. Using the Decode As… option, I can specify that data following label 32773 is Ethernet PW (no CW), where PW here means pseudowire and CW means controlword. Et, voilà, the first packet reveals itself:

Pseudowires on Sub Interfaces
One very common use case for me at IPng Networks is to work with excellent partners like [IP-Max] who provide Internet Exchange transport, for example from DE-CIX or SwissIX, to the customer premises. IP-Max uses Cisco’s ASR9k routers, an absolutely beautiful piece of technology [ref], and with those you can terminate a L2VPN in any sub-interface.
Let’s configure something similar. I take one port on msw-top, and branch that out into three
remote locations, in this case msw-bottom port 1, 2 and 3. I will be terminating all three pseudowires
on the same endpoint, but obviously this could also be one port that goes to three internet exchanges,
say SwissIX, DE-CIX and FranceIX, on three different endpoints.
The configuration for both switches will look like this:
msw-top# configure terminal
interface eth-0-1
switchport mode trunk
switchport trunk native vlan 5
switchport trunk allowed vlan add 6-8
mpls-l2-circuit pw-vlan10 vlan 10
mpls-l2-circuit pw-vlan20 vlan 20
mpls-l2-circuit pw-vlan30 vlan 30
mpls l2-circuit pw-vlan10 829810 172.20.0.0 raw mtu 9000
mpls l2-circuit pw-vlan20 829820 172.20.0.0 raw mtu 9000
mpls l2-circuit pw-vlan30 829830 172.20.0.0 raw mtu 9000
msw-bottom# configure terminal
interface eth-0-1
mpls-l2-circuit pw-vlan10 ethernet
interface eth-0-2
mpls-l2-circuit pw-vlan20 ethernet
interface eth-0-3
mpls-l2-circuit pw-vlan30 ethernet
mpls l2-circuit pw-vlan10 829810 172.20.0.2 raw mtu 9000
mpls l2-circuit pw-vlan20 829820 172.20.0.2 raw mtu 9000
mpls l2-circuit pw-vlan30 829830 172.20.0.2 raw mtu 9000
Previously, I configured the port in ethernet mode, which takes all frames and forwards them into
the MPLS tunnel. In this case, I’m using vlan mode, specifying a VLAN tag that, when frames arrive
on the port matching it, will selectively be put into a pseudowire. As an added benefit, this allows
me to still use the port as a regular switchport, in the snippet above it will take untagged frames
and assign them to VLAN 5, allow tagged frames with dot1q VLAN tag 6, 7 or 8, and handle them as any
normal switch would. VLAN tag 10, however, is directed into the pseudowire called pw-vlan10, and
the other two tags similarly get put into their own l2-circuit. Using LDP signalling, the pw-id
(829810, 829820, and 829830) determines which label is assigned. On the way back, that label
allows the switch to correlate the ethernet frame with the correct port and transmit the it with the
configured VLAN tag.
To show this from an end-user point of view, let’s take a look at the Linux server connected to these switches. I’ll put one port in a namespace called top, and three other ports in a network namespace called bottom, and then proceed to give them a little bit of config:
root@dut-lab:~# ip link set netns top dev enp66s0f0
root@dut-lab:~# ip link set netns bottom dev enp66s0f1
root@dut-lab:~# ip link set netns bottom dev enp66s0f2
root@dut-lab:~# ip link set netns bottom dev enp4s0f1
root@dut-lab:~# nsenter --net=/var/run/netns/top
root@dut-lab:~# ip link add link enp66s0f0 name v10 type vlan id 10
root@dut-lab:~# ip link add link enp66s0f0 name v20 type vlan id 20
root@dut-lab:~# ip link add link enp66s0f0 name v30 type vlan id 30
root@dut-lab:~# ip addr add 192.0.2.0/31 dev v10
root@dut-lab:~# ip addr add 192.0.2.2/31 dev v20
root@dut-lab:~# ip addr add 192.0.2.4/31 dev v30
root@dut-lab:~# nsenter --net=/var/run/netns/bottom
root@dut-lab:~# ip addr add 192.0.2.1/31 dev enp66s0f1
root@dut-lab:~# ip addr add 192.0.2.3/31 dev enp66s0f2
root@dut-lab:~# ip addr add 192.0.2.5/31 dev enp4s0f1
root@dut-lab:~# ping 192.0.2.4
PING 192.0.2.4 (192.0.2.4) 56(84) bytes of data.
64 bytes from 192.0.2.4: icmp_seq=1 ttl=64 time=0.153 ms
64 bytes from 192.0.2.4: icmp_seq=2 ttl=64 time=0.209 ms
To unpack this a little bit, in the first block I assign the interfaces to their respective
namespace. Then, for the interface connected to the msw-top switch, I create three dot1q
sub-interfaces, corresponding to the pseudowires I created. Note: untagged traffic out of
enp66s0f0 will simply be picked up by the switch and assigned VLAN 5 (and I’m also allowed to send
VLAN tags 6, 7 and 8, which will all be handled locally).
But, VLAN 10, 20 and 30 will be moved through the MPLS network and pop out on the msw-bottom
switch, where they are each assigned a unique port, represented by enp66s0f1, enp66s0f2 and
enp4s0f1 connected to the bottom switch.
When I finally ping 192.0.2.4, that ICMP packet goes out on enp4s0f1, which enters
msw-bottom:eth-0-3, it gets assigned the pseudowire name pw-vlan30, which corresponds to the
pw-id 829830, then it travels over the MPLS network, arriving at msw-bottom carrying a label
that tells that switch that it belongs to its local pw-id 829830 which corresponds to name
pw-vlan30 and is assigned VLAN tag 30 on port eth-0-1. Phew, I made it. It actually makes sense
when you think about it!
VPLS
The pseudowires that I described in the previous section are simply ethernet cross connects spanning over an MPLS network. They are inherently point-to-point, much like a physical Ethernet cable is. Sometimes, it makes more sense to take a local port and create what is called a Virtual Private LAN Service (VPLS), described in [RFC4762], where packets into this port are capable of being sent to any number of other ports on any number of other switches, while using MPLS as transport.
By means of example, let’s say a telco offers me one port in Amsterdam, one in Zurich and one in Frankfurt. A VPLS instance would create an emulated LAN segment between these locations, in other words a Layer 2 broadcast domain that is fully capable of learning and forwarding on Ethernet MAC addresses but the ports are dedicated to me, and they are isolated from other customers. The telco has essentially created a three-port switch for me, but at the same time, that telco can create any number of VPLS services, each one unique to their individual customers. It’s a pretty powerful concept.
In principle, a VPLS consists of two parts:
- A full mesh of simple MPLS point-to-point tunnels from each participating switch to each other one. These are just pseudowires with a given pw-id, just like I showed before.
- The pseudowires are then tied together in a form of bridge domain, and learning is applied to MAC addresses that appear behind each port, signalling that these are available behind the port.
Configuration on the switch looks like this:
msw-top# configure terminal
interface eth-0-1
mpls-vpls v-ipng ethernet
interface eth-0-2
mpls-vpls v-ipng ethernet
interface eth-0-3
mpls-vpls v-ipng ethernet
interface eth-0-4
mpls-vpls v-ipng ethernet
!
mpls vpls v-ipng 829801
vpls-peer 172.20.0.0 raw
vpls-peer 172.20.0.1 raw
The first set of commands add each individual interface into the VPLS instance by binding it to a
name, in this case v-ipng. Then, the VPLS neighbors are specified, by offering a pw-id (829801)
which is used to construct a pseudowire to the two peers. The first, 172.20.0.0 is msw-bottom, and
the other, 172.20.0.1 is msw-core. Each switch that participates in the VPLS for v-ipng will signal
LSPs to each of its peers, and MAC learning will be enabled just as if each of these pseudowires
were a regular switchport.
Once I configure this pattern on all three switches, effectively interfaces eth-0-1 - 4 are now
bound together as a virtual switch with a unique broadcast domain dedicated to instance v-ipng.
I’ve created a fully transparent 12-port switch, which means that what-ever traffic I generate, will
be encapsulated in MPLS and sent through the MPLS network towards its destination port.
Let’s take a look at the msw-core switch to see how this looks like:
msw-core# show ldp vpls
VPLS-ID Peer Address State Type Label-Sent Label-Rcvd Cw
829801 172.20.0.0 Up ethernet 32774 32773 0
829801 172.20.0.2 Up ethernet 32776 32774 0
msw-core# show mpls vpls mesh
VPLS-ID Peer Addr/name In-Label Out-Intf Out-Label Type St Evpn Type2 Sr-tunid
829801 172.20.0.0/- 32777 eth-0-50 32775 RAW Up N N -
829801 172.20.0.2/- 32778 eth-0-49 32776 RAW Up N N -
msw-core# show mpls vpls detail
Virtual Private LAN Service Instance: v-ipng, ID: 829801
Group ID: 0, Configured MTU: NULL
Description: none
AC interface :
Name TYPE Vlan
eth-0-1 Ethernet ALL
eth-0-2 Ethernet ALL
eth-0-3 Ethernet ALL
eth-0-4 Ethernet ALL
Mesh Peers :
Peer TYPE State C-Word Tunnel name LSP name
172.20.0.0 RAW UP Disable N/A N/A
172.20.0.2 RAW UP Disable N/A N/A
Vpls-mac-learning enable
Discard broadcast disabled
Discard unknown-unicast disabled
Discard unknown-multicast disabled
Putting this to the test, I decide to run a loadtest saturating 12x 10G of traffic through this spiffy 12-port virtual switch. I randomly assign ports on the loadtester to the 12 ports in the v-ipng VPLS, and then I start full line rate load with 128 byte packets. Considering I’m using twelve TenGig ports, I would expect 12x8.43 or roughly 101Mpps flowing, and indeed, the loadtests demonstrate this mark nicely:
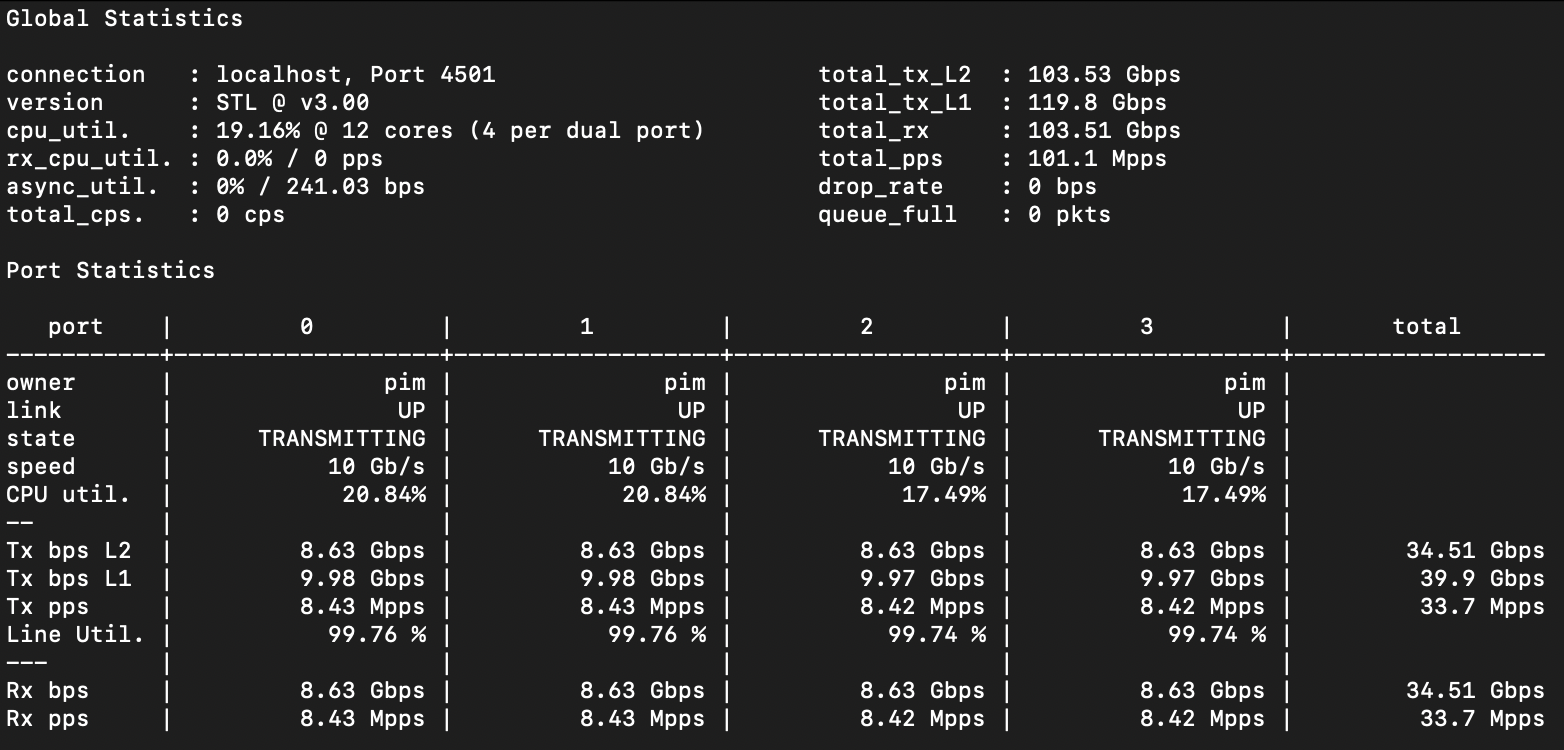
Important: The screenshot above shows the first four ports on the T-Rex interface only, but there are actually twelve ports participating in this loadtest. In the top right corner, the total throughput is correctly represented. The switches are handling 120Gbps of L1, 103.5Gbps of L2 (which is expected at 128b frames, as there is a little bit of ethernet overhead for each frame), which is a whopping 101Mpps, which is exactly what I would expect.
And the chassis doesn’t even get warm.
Conclusions
It’s just super cool to see a switch like this work as expected. I did not manage to overload it at all, in my [previous article], I showed VxLAN, GENEVE and NvGRE overlays at line rate. Here, I can see that MPLS with all of its Martini bells and whistles, and as well the more advanced VPLS, are keeping up like a champ. I think at least for initial configuration and throughput on all MPLS features I tested, both the small 24x10 + 2x100G switch, and the larger 48x10 + 2x40 + 4x100G switch, are keeping up just fine.
A duration test will have to show if the configuration and switch fabric are stable over time, but I am hopeful that Centec is hitting the exact sweet spot for me on the MPLS transport front.
Yes, yes yes. I did as well promise to take a look at eVPN functionality (this is another form of L3VPN which uses iBGP to share which MAC addresses live behind which VxLAN ports). This post has been fun, but also quite long (4300 words!) so I’ll follow up in a future article on the eVPN capabilities of the Centec switches.