Introduction
When I first built IPng Networks AS8298, I decided to use OSPF as an IPv4 and IPv6 internal gateway protocol. Back in March I took a look at two slightly different ways of doing this for IPng, notably against a backdrop of conserving IPv4 addresses. As the network grows, the little point to point transit networks between routers really start adding up.
I explored two potential solutions to this problem:
- [Babel] can use IPv6 nexthops for IPv4 destinations - which is super useful because it would allow me to retire all of the IPv4 /31 point to point networks between my routers.
- [OSPFv3] makes it difficult to use IPv6 nexthops for IPv4 destinations, but in a discussion with the Bird Users mailinglist, we found a way: by reusing a single IPv4 loopback address on adjacent interfaces

In May I ran a modest set of two canaries, one between the two routers in my house (chbtl0 and
chbtl1), and another between a router at the Daedalean colocation and Interxion datacenters (ddln0
and chgtg0). AS8298 has about quarter of a /24 tied up in these otherwise pointless point-to-point
transit networks (see what I did there?). I want to reclaim these!
Seeing as the two tests went well, I decided to roll this out and make it official. This post describes how I rolled out an (almost) IPv4-less core network for IPng Networks. It was actually way easier than I had anticipated, and apparently I was not alone - several of my buddies in the industry have asked me about it, so I thought I’d write a little bit about the configuration.
Background: OSPFv3 with IPv4
💩 /30: 4 addresses: In the oldest of days, two routers that formed an IPv4 OSPF adjacency would have a /30 point-to-point transit network between them. Router A would have the lower available IPv4 address, and Router B would have the upper available IPv4 address. The other two addresses in the /30 would be the network and broadcast addresses of the prefix. Not a very efficient way to do things, but back in the old days, IPv4 addresses were in infinite supply.
🥈 /31: 2 addresses: Enter [RFC3021], from December 2000, which some might argue are also the old days. With ever-increasing pressure to conserve IP address space on the Internet, it makes sense to consider where relatively minor changes can be made to fielded practice to improve numbering efficiency. This RFC describes how to halve the amount of address space assigned to point-to-point links (common throughout the Internet infrastructure) by allowing the use of /31 prefixes for them. At some point, even our friends from Latvia figured it out!
🥇 /32: 1 address: In most networks, each router has what is called a loopback IPv4 and IPv6 address, typically a /32 and /128 in size. This allows the router to select a unique address that is not bound to any given interface. It comes in handy in many ways – for example to have stable addresses to manage the router, and to allow it to connect to iBGP route reflectors and peers from well known addresses.
As it so turns out, two routers that form an adjacency can advertise ~any IPv4 address as nexthop, provided that their adjacent peer knows how to find that address. Of course, with a /30 or /31 this is obvious: if I have a directly connected /31, I can simply ARP for the other side, learn its MAC address, and use that to forward traffic to the other router.
The Trick
What would it look like if there’s no subnet that directly connects two adjacent routers? Well, I happen to know that RouterA and RouterB both have a /32 loopback address. So if I simply let RouterA (1) advertise its loopback address to neighbor RouterB, and also (2) answer ARP requests for that address, the two routers should be able to form an adjacency. This is exactly what Ondrej’s [Bird2 commit (1)] and my [VPP gerrit (2)] accomplish, as perfect partners:
- Ondrej’s change will make the Link LSA be onlink, which is a way to describe that the next hop
is not directly connected, in other words RouterB will be at nexthop
192.0.2.1, while RouterA itself is192.0.2.0/32. - My change will make VPP answer for ARP requests in such a scenario where RouterA with an
unnumbered interface with
192.0.2.0/32will respond to a request from the not directly connected onlink peer RouterB at192.0.2.1.
Rolling out P2P-less OSPFv3
1. Upgrade VPP + Bird2
First order of business is to upgrade all routers. I need a VPP version with the [ARP
gerrit] and a Bird2 version with the [OSPFv3
commit]. I build
a set of Debian packages on bookworm-builder and upload them to IPng’s website
[ref].
I schedule a two nightly maintenance windows. In the first one, I’ll upgrade two routers (frggh0
and ddln1) by means of canary. I’ll let them run for a few days, and then wheel over the rest
after I’m confident there are no regressions.
For each router, I will first drain it: this means in Kees, setting the OSPFv2 and OSPFv3 cost of routers neighboring it to a higher number, so that traffic flows around the ’expensive’ link. I will also move the eBGP sessions into shutdown mode, which will make the BGP sessions stay connected, but the router will not announce any prefixes nor accept any from peers. Without it announcing or learning any prefixes, the router stops seeing traffic. After about 10 minutes, it is safe to make intrusive changes to it.
Seeing as I’ll be moving from OSPFv2 to OSPFv3, I will allow for a seemless transition by
configuring both protocols to run at the same time. The filter that applies to both flavors of OSPF
is the same: I will only allow more specifics of IPng’s own prefixes to be propagated, and in
particular I’ll drop all prefixes that come from BGP. I’ll rename the protocol called ospf4 to
ospf4_old, and create a new (OSPFv3) protocol called ospf4 which has only the loopback interface
in it. This way, when I’m done, the final running protocol will simply be called ospf4:
filter f_ospf {
if (source = RTS_BGP) then reject;
if (net ~ [ 92.119.38.0/24{25,32}, 194.1.163.0/24{25,32}, 194.126.235.0/24{25,32} ]) then accept;
if (net ~ [ 2001:678:d78::/48{56,128}, 2a0b:dd80:3000::/36{48,48} ]) then accept;
reject;
}
protocol ospf v2 ospf4_old {
ipv4 { export filter f_ospf; import filter f_ospf; };
area 0 {
interface "loop0" { stub yes; };
interface "xe1-1.302" { type pointopoint; cost 61; bfd on; };
interface "xe1-0.304" { type pointopoint; cost 56; bfd on; };
};
}
protocol ospf v3 ospf4 {
ipv4 { export filter f_ospf; import filter f_ospf; };
area 0 {
interface "loop0","lo" { stub yes; };
};
}
In one terminal, I will start a ping to the router’s IPv4 loopback:
pim@summer:~$ ping defra0.ipng.ch
PING (194.1.163.7) 56(84) bytes of data.
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=1 ttl=61 time=6.94 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=2 ttl=61 time=7.00 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=3 ttl=61 time=7.03 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=4 ttl=61 time=7.03 ms
...
While in the other, I log in to the IPng Site Local connection to the router’s management plane, to perform the ugprade:
pim@squanchy:~$ ssh defra0.net.ipng.ch
pim@defra0:~$ wget -m --no-parent https://ipng.ch/media/vpp/bookworm/24.06-rc0~183-gb0d433978/
pim@defra0:~$ cd ipng.ch/media/vpp/bookworm/24.06-rc0~183-gb0d433978/
pim@defra0:~$ sudo nsenter --net=/var/run/netns/dataplane
root@defra0:~# pkill -9 vpp && systemctl stop bird-dataplane vpp && \
dpkg -i ~pim/ipng.ch/media/vpp/bookworm/24.06-rc0~183-gb0d433978/*.deb && \
dpkg -i ~pim/bird2_2.15.1_amd64.deb && \
systemctl start bird-dataplane && \
systemctl restart vpp-snmp-agent-dataplane vpp-exporter-dataplane
Then comes the small window of awkward staring at the ping I started in the other terminal. It always makes me smile because it all comes back very quickly, within 90 seconds the router is back online and fully converged with BGP:
pim@summer:~$ ping defra0.ipng.ch
PING (194.1.163.7) 56(84) bytes of data.
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=1 ttl=61 time=6.94 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=2 ttl=61 time=7.00 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=3 ttl=61 time=7.03 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=4 ttl=61 time=7.03 ms
...
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=94 ttl=61 time=1003.83 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=95 ttl=61 time=7.03 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=96 ttl=61 time=7.02 ms
64 bytes from defra0.ipng.ch (194.1.163.7): icmp_seq=97 ttl=61 time=7.03 ms
pim@defra0:~$ birdc show ospf nei
BIRD v2.15.1-4-g280daed5-x ready.
ospf4_old:
Router ID Pri State DTime Interface Router IP
194.1.163.8 1 Full/PtP 32.113 xe1-1.302 194.1.163.27
194.1.163.0 1 Full/PtP 30.936 xe1-0.304 194.1.163.24
ospf4:
Router ID Pri State DTime Interface Router IP
ospf6:
Router ID Pri State DTime Interface Router IP
194.1.163.8 1 Full/PtP 32.113 xe1-1.302 fe80::3eec:efff:fe46:68a8
194.1.163.0 1 Full/PtP 30.936 xe1-0.304 fe80::6a05:caff:fe32:4616
I can see that the OSPFv2 adjacencies have reformed, which is totally expected. Looking at the router’s current addresses:
pim@defra0:~$ ip -br a | grep UP
loop0 UP 194.1.163.7/32 2001:678:d78::7/128 fe80::dcad:ff:fe00:0/64
xe1-0 UP fe80::6a05:caff:fe32:3e48/64
xe1-1 UP fe80::6a05:caff:fe32:3e49/64
xe1-2 UP fe80::6a05:caff:fe32:3e4a/64
xe1-3 UP fe80::6a05:caff:fe32:3e4b/64
xe1-0.304@xe1-0 UP 194.1.163.25/31 2001:678:d78::2:7:2/112 fe80::6a05:caff:fe32:3e48/64
xe1-1.302@xe1-1 UP 194.1.163.26/31 2001:678:d78::2:8:1/112 fe80::6a05:caff:fe32:3e49/64
xe1-2.441@xe1-2 UP 46.20.246.51/29 2a02:2528:ff01::3/64 fe80::6a05:caff:fe32:3e4a/64
xe1-2.503@xe1-2 UP 80.81.197.38/21 2001:7f8::206a:0:1/64 fe80::6a05:caff:fe32:3e4a/64
xe1-2.514@xe1-2 UP 185.1.210.235/23 2001:7f8:3d::206a:0:1/64 fe80::6a05:caff:fe32:3e4a/64
xe1-2.515@xe1-2 UP 185.1.208.84/23 2001:7f8:44::206a:0:1/64 fe80::6a05:caff:fe32:3e4a/64
xe1-2.516@xe1-2 UP 185.1.171.43/23 2001:7f8:9e::206a:0:1/64 fe80::6a05:caff:fe32:3e4a/64
xe1-3.900@xe1-3 UP 193.189.83.55/23 2001:7f8:33::a100:8298:1/64 fe80::6a05:caff:fe32:3e4b/64
xe1-3.2003@xe1-3 UP 185.1.155.116/24 2a0c:b641:701::8298:1/64 fe80::6a05:caff:fe32:3e4b/64
xe1-3.3145@xe1-3 UP 185.1.167.136/23 2001:7f8:f2:e1::8298:1/64 fe80::6a05:caff:fe32:3e4b/64
xe1-3.1405@xe1-3 UP 80.77.16.214/30 2a00:f820:839::2/64 fe80::6a05:caff:fe32:3e4b/64
Take a look at interfaces xe1-0.304 which is southbound from Frankfurt to Zurich
(chrma0.ipng.ch) and xe1-1.302 which is northbound from Frankfurt to Amsterdam
(nlams0.ipng.ch). I am going to get rid of the IPv4 and IPv6 global unicast addresses on these two
interfaces, and let OSPFv3 borrow the IPv4 address from loop0 instead.
But first, rinse and repeat, until all routers are upgraded.
2. A situational overview
First, let me draw a diagram that helps show what I’m about to do:

In the network overview I’ve drawn four of IPng’s routers. The ones at the bottom are the two
routers at my office in Brüttisellen, Switzerland, which explains their name chbtl0 and
chbtl1, and they are connected via a local fiber trunk using 10Gig optics (drawn in red). On the left, the first router is connected via a
10G Ethernet-over-MPLS link (depicted in green)
to the NTT Datacenter in Rümlang. From there, IPng rents a 25Gbps wavelength to the Interxion
datacenter in Glattbrugg (shown in blue). Finally,
the Interxion router connects back to Brüttisellen using a 10G Ethernet-over-MPLS link (colored
in pink), completing the ring.
You can also see that each router has a set of loopback addresses, for example chbtl0 in the
bottom left has IPv4 address 194.1.163.3/32 and IPv6 address 2001:678:d78::3/128. Each point to
point network has assigned one /31 and one /112 with each router taking one address at either side.
Counting them up real quick, I see twelve IPv4 addresses in this diagram. This is a classic OSPF
design pattern. I seek to save eight of these addresses!
3. First OSPFv3 link
The rollout has to start somewhere, and I decide to start close to home, literally. I’m going to remove the IPv4 and IPv6 addresses from the red link between the two routers in Brüttisellen. They are directly connected, and if anything goes wrong, I can walk over and rescue them. Sounds like a safe way to start!
I quickly add the ability for [vppcfg] to configure unnumbered interfaces. In VPP, these are interfaces that don’t have an IPv4 or IPv6 address of their own, but they borrow one from another interface. If you’re curious, you can take a look at the [User Guide] on GitHub.
Looking at their vppcfg files, the change is actually very easy, taking as an example the
configuration file for chbtl0.ipng.ch:
loopbacks:
loop0:
description: 'Core: chbtl1.ipng.ch'
addresses: ['194.1.163.3/32', '2001:678:d78::3/128']
lcp: loop0
mtu: 9000
interfaces:
TenGigabitEthernet6/0/0:
device-type: dpdk
description: 'Core: chbtl1.ipng.ch'
mtu: 9000
lcp: xe1-0
# addresses: [ '194.1.163.20/31', '2001:678:d78::2:5:1/112' ]
unnumbered: loop0
By commenting out the addresses field, and replacing it with unnumbered: loop0, I instruct
vppcfg to make Te6/0/0, which in Linux is called xe1-0, borrow its addresses from the loopback
interface loop0.
Planning and applying this is straight forward, but there’s one detail I should
mention. In my [previous article] I asked myself a question:
would it be better to leave the addresses unconfigured in Linux, or would it be better to make the
Linux Control Plane plugin carry forward the borrowed addresses? In the end, I decided to not copy
them forward. VPP will be aware of the addresses, but Linux will only carry them on the loop0
interface.
In the article, you’ll see that discussed as Solution 2, and it includes a bit of rationale why I
find this better. I implemented it in this
[commit], in
case you’re curious, and the commandline keyword is lcp lcp-sync-unnumbered off (the default is
on).
pim@chbtl0:~$ vppcfg plan -c /etc/vpp/vppcfg.yaml
[INFO ] root.main: Loading configfile /etc/vpp/vppcfg.yaml
[INFO ] vppcfg.config.valid_config: Configuration validated successfully
[INFO ] root.main: Configuration is valid
[INFO ] vppcfg.vppapi.connect: VPP version is 24.06-rc0~183-gb0d433978
comment { vppcfg prune: 2 CLI statement(s) follow }
set interface ip address del TenGigabitEthernet6/0/0 194.1.163.20/31
set interface ip address del TenGigabitEthernet6/0/0 2001:678:d78::2:5:1/112
comment { vppcfg sync: 1 CLI statement(s) follow }
set interface unnumbered TenGigabitEthernet6/0/0 use loop0
[INFO ] vppcfg.reconciler.write: Wrote 5 lines to (stdout)
[INFO ] root.main: Planning succeeded
pim@chbtl0:~$ vppcfg show int addr TenGigabitEthernet6/0/0
TenGigabitEthernet6/0/0 (up):
unnumbered, use loop0
L3 194.1.163.3/32
L3 2001:678:d78::3/128
pim@chbtl0:~$ vppctl show lcp | grep TenGigabitEthernet6/0/0
itf-pair: [9] TenGigabitEthernet6/0/0 tap9 xe1-0 65 type tap netns dataplane
pim@chbtl0:~$ ip -br a | grep UP
xe0-0 UP fe80::92e2:baff:fe3f:cad4/64
xe0-1 UP fe80::92e2:baff:fe3f:cad5/64
xe0-1.400@xe0-1 UP fe80::92e2:baff:fe3f:cad4/64
xe0-1.400.10@xe0-1.400 UP 194.1.163.16/31 2001:678:d78:2:3:1/112 fe80::92e2:baff:fe3f:cad4/64
xe1-0 UP fe80::21b:21ff:fe55:1dbc/64
xe1-1.101@xe1-1 UP 194.1.163.65/27 2001:678:d78:3::1/64 fe80::14b4:c6ff:fe1e:68a3/64
xe1-1.179@xe1-1 UP 45.129.224.236/29 2a0e:5040:0:2::236/64 fe80::92e2:baff:fe3f:cad5/64
After applying this configuration, I can see that Te6/0/0 indeed is unnumbered, use loop0 noting
the IPv4 and IPv6 addresses that it borrowed. I can see with the second command that Te6/0/0
corresponds in Linux with xe1-0, and finally with the third command I can list the addresses of
the Linux view, and indeed I confirm that xe1-0 only has a link local address. Slick!
After applying this change, the OSPFv2 adjacency in the ospf4_old protocol expires, and I see the
routing table converge. A traceroute between chbtl0 and chbtl1 now takes a bit of a detour:
pim@chbtl0:~$ traceroute chbtl1.ipng.ch
traceroute to chbtl1 (194.1.163.4), 30 hops max, 60 byte packets
1 chrma0.ipng.ch (194.1.163.17) 0.981 ms 0.969 ms 0.953 ms
2 chgtg0.ipng.ch (194.1.163.9) 1.194 ms 1.192 ms 1.176 ms
3 chbtl1.ipng.ch (194.1.163.4) 1.875 ms 1.866 ms 1.911 ms
I can now introduce the very first OSPFv3 adjacency for IPv4, and I do this by moving the neighbor
from the ospf4_old protocol to the ospf4 prototol. Of course, I also update chbtl1 with the
unnumbered interface on its xe1-0, and update OSPF there. And with that, something magical
happens:
pim@chbtl0:~$ birdc show ospf nei
BIRD v2.15.1-4-g280daed5-x ready.
ospf4_old:
Router ID Pri State DTime Interface Router IP
194.1.163.0 1 Full/PtP 30.571 xe0-1.400.10 fe80::266e:96ff:fe37:934c
ospf4:
Router ID Pri State DTime Interface Router IP
194.1.163.4 1 Full/PtP 31.955 xe1-0 fe80::9e69:b4ff:fe61:ff18
ospf6:
Router ID Pri State DTime Interface Router IP
194.1.163.4 1 Full/PtP 31.955 xe1-0 fe80::9e69:b4ff:fe61:ff18
194.1.163.0 1 Full/PtP 30.571 xe0-1.400.10 fe80::266e:96ff:fe37:934c
pim@chbtl0:~$ birdc show route protocol ospf4
BIRD v2.15.1-4-g280daed5-x ready.
Table master4:
194.1.163.4/32 unicast [ospf4 2024-05-19 20:58:04] * I (150/2) [194.1.163.4]
via 194.1.163.4 on xe1-0 onlink
194.1.163.64/27 unicast [ospf4 2024-05-19 20:58:04] E2 (150/2/10000) [194.1.163.4]
via 194.1.163.4 on xe1-0 onlink
Aww, would you look at that! Especially the first entry is interesting to me. It says that this
router has learned the address 194.1.163.4/32, the loopback address of chbtl1 via nexthop
also 194.1.163.4 on interface xe1-0 with a flag onlink.
The kernel routing table agrees with this construction:
pim@chbtl0:~$ ip ro get 194.1.163.4
194.1.163.4 via 194.1.163.4 dev xe1-0 src 194.1.163.3 uid 1000
cache
Now, what this construction tells the kernel, is that it should ARP for 194.1.163.4 using local
address 194.1.163.3, for which VPP on the other side will respond, thanks to my [VPP ARP
gerrit]. As such, I should expect now a FIB entry for VPP:
pim@chbtl0:~$ vppctl show ip fib 194.1.163.4
ipv4-VRF:0, fib_index:0, flow hash:[src dst sport dport proto flowlabel ] epoch:0 flags:none locks:[adjacency:1, default-route:1, lcp-rt:1, ]
194.1.163.4/32 fib:0 index:973099 locks:3
lcp-rt-dynamic refs:1 src-flags:added,contributing,active,
path-list:[189] locks:98 flags:shared,popular, uPRF-list:507 len:1 itfs:[36, ]
path:[166] pl-index:189 ip4 weight=1 pref=32 attached-nexthop: oper-flags:resolved,
194.1.163.4 TenGigabitEthernet6/0/0
[@0]: ipv4 via 194.1.163.4 TenGigabitEthernet6/0/0: mtu:9000 next:10 flags:[] 90e2ba3fcad4246e9637934c810001908100000a0800
adjacency refs:1 entry-flags:attached, src-flags:added, cover:-1
path-list:[1025] locks:1 uPRF-list:1521 len:1 itfs:[36, ]
path:[379] pl-index:1025 ip4 weight=1 pref=0 attached-nexthop: oper-flags:resolved,
194.1.163.4 TenGigabitEthernet6/0/0
[@0]: ipv4 via 194.1.163.4 TenGigabitEthernet6/0/0: mtu:9000 next:10 flags:[] 90e2ba3fcad4246e9637934c810001908100000a0800
Extensions:
path:379
forwarding: unicast-ip4-chain
[@0]: dpo-load-balance: [proto:ip4 index:848961 buckets:1 uRPF:507 to:[1966944:611861009]]
[0] [@5]: ipv4 via 194.1.163.4 TenGigabitEthernet6/0/0: mtu:9000 next:10 flags:[] 90e2ba3fcad4246e9637934c810001908100000a0800
Nice work, VPP and Bird2! I confirm that I can ping the neighbor again, and that the traceroute is direct rather than the scenic route from before, and I validate that IPv6 still works for good measure:
pim@chbtl0:~$ ping -4 chbtl1.ipng.ch
PING 194.1.163.4 (194.1.163.4) 56(84) bytes of data.
64 bytes from 194.1.163.4: icmp_seq=1 ttl=63 time=0.169 ms
64 bytes from 194.1.163.4: icmp_seq=2 ttl=63 time=0.283 ms
64 bytes from 194.1.163.4: icmp_seq=3 ttl=63 time=0.232 ms
64 bytes from 194.1.163.4: icmp_seq=4 ttl=63 time=0.271 ms
^C
--- 194.1.163.4 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3003ms
rtt min/avg/max/mdev = 0.163/0.233/0.276/0.045 ms
pim@chbtl0:~$ traceroute chbtl1.ipng.ch
traceroute to chbtl1 (194.1.163.4), 30 hops max, 60 byte packets
1 chbtl1.ipng.ch (194.1.163.4) 0.190 ms 0.176 ms 0.147 ms
pim@chbtl0:~$ ping6 chbtl1.ipng.ch
PING chbtl1.ipng.ch(chbtl1.ipng.ch (2001:678:d78::4)) 56 data bytes
64 bytes from chbtl1.ipng.ch (2001:678:d78::4): icmp_seq=1 ttl=64 time=0.205 ms
64 bytes from chbtl1.ipng.ch (2001:678:d78::4): icmp_seq=2 ttl=64 time=0.203 ms
64 bytes from chbtl1.ipng.ch (2001:678:d78::4): icmp_seq=3 ttl=64 time=0.213 ms
64 bytes from chbtl1.ipng.ch (2001:678:d78::4): icmp_seq=4 ttl=64 time=0.219 ms
^C
--- chbtl1.ipng.ch ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3068ms
rtt min/avg/max/mdev = 0.203/0.210/0.219/0.006 ms
pim@chbtl0:~$ traceroute6 chbtl1.ipng.ch
traceroute to chbtl1.ipng.ch (2001:678:d78::4), 30 hops max, 80 byte packets
1 chbtl1.ipng.ch (2001:678:d78::4) 0.163 ms 0.147 ms 0.124 ms
4. From one to two

At this point I have two IPv4 IGPs running. This is not ideal, but it’s also not completely broken,
because the OSPF filter allows the routers to learn and propagate any more specific prefix from
194.1.163.0/24. This way, the legacy OSPFv2 called ospf4_old and this new OSPFv3 called ospf4
will be aware of all routes. Bird will learn them twice, and routing decisions may be a bit funky
because the OSPF protocols learn the routes from each other as OSPF-E2. There are two implications
of this:
-
It means that the routes that are learned from the other OSPF protocol will have a fixed metric (==cost), and for the time being, I won’t be able to cleanly add up link costs between the routers that are speaking OSPFv2 and those that are speaking OSPFv3.
-
If an OSPF External Type E1 and Type E2 route exist to the same destination the E1 route will always be preferred irrespective of the metric. This means that within the routers that speak OSPFv2, cost will remain consistent; and also within the routers that speak OSPFv3, it will be consistent. Between them, routes will be learned, but cost will be roughly meaningless.
I upgrade another link, between router chgtg0 and ddln0 at my [colo], which is connected via a 10G EoMPLS link from a local telco called Solnet. The
colo, similar to IPng’s office, has two redundant 10G uplinks, so if things were to fall apart, I
can always quickly shutdown the offending link (thereby removing OSPFv3 adjacencies), and traffic
will reroute. I have created two islands of OSPFv3, drawn in orange, with exactly two links using IPv4-less point to
point networks. I let this run for a few weeks, to make sure things do not fail in mysterious ways.
5. From two to many

From this point on it’s just rinse-and-repeat. For each backbone link, I will:
- I will drain the backbone link I’m about to work on, by raising OSPFv2 and OSPFv3 cost on both sides. If the cost was, say, 56, I will temporarily make that 1056. This will make traffic avoid using the link if at all possible. Due to redundancy, every router has (at least) two backbone links. Traffic will be diverted.
- I first change the VPP router’s
vppcfg.yamlto remove the p2p addresses and replace them with anunnumbered: loop0instead. I apply the diff, and the OSPF adjacency breaks for IPv4. The BFD adjacency for IPv4 will disappear. Curiously, the IPv6 adjacency stays up, because OSPFv3 adjacencies use link-local addresses. - I move the interface section of the old OSPFv2
ospf4_oldprotocol to the new OSPFv3ospf4protocol, which will als use link-local addresses to form adjacencies. The two routers will exchange Link LSA and be able to find each other directly connected. Now the link is running two OSPFv3 protocols, each in their own address family. They will share the same BFD session. - I finally undrain the link by setting the OSPF link cost back to what it was. This link is now a part of the OSPFv3 part of the network.
I work my way through the network. The first one I do is the link between chgtg0 and chbtl1
(which I’ve colored in the diagram in pink), so
that there are four contiguous OSPFv3 links, spanning from chbtl0 - chbtl1 - chgtg0 - ddln0. I
constantly do a traceroute to a machine that is directly connected behind ddln0, and as well use
RIPE Atlas and the NLNOG Ring to ensure that I have reachability:
pim@squanchy:~$ traceroute ipng.mm.fcix.net
traceroute to ipng.mm.fcix.net (194.1.163.59), 64 hops max, 40 byte packets
1 chbtl0 (194.1.163.65) 0.279 ms 0.362 ms 0.249 ms
2 chbtl1 (194.1.163.3) 0.455 ms 0.394 ms 0.384 ms
3 chgtg0 (194.1.163.1) 1.302 ms 1.296 ms 1.294 ms
4 ddln0 (194.1.163.5) 2.232 ms 2.385 ms 2.322 ms
5 mm0.ddln0.ipng.ch (194.1.163.59) 2.377 ms 2.577 ms 2.364 ms
I work my way outwards from there. First completing the ring chbtl0 - chrma0 - chgtg0 - chbtl1, and then completing the ring ddln0 - ddln1 - chrma0 - chgtg0, after which the Zurich metro area is converted. I then work my way clockwise from Zurich to Geneva, Paris, Lille, Amsterdam, Frankfurt, and end up with the last link completing the set: defra0 - chrma0.
Results

In total I reconfigure thirteen backbone links, and they all become unnumbered using the router’s
loopback addresses for IPv4 and IPv6, and they all switch over from their OSPFv2 IGP to the new
OSPFv3 IGP; the total number of routers running the old IGP shrinks until there are none left. Once
that happens, I can simply remove the OSPFv2 protocol called ospf4_old, and keep the two OSPFv3
protocols now intuitively called ospf4 and ospf6. Nice.
This maintenance isn’t super intrusive. For IPng’s customers, latency goes up from time to time as backbone links are drained, the link is reconfigured to become unnumbered and OSPFv3, and put back into service. The whole operation takes a few hours, and I enjoy the repetitive tasks, getting pretty good at the drain-reconfigure-undrain cycle after a while.
It looks really cool on transit routers, like this one in Lille, France:
pim@frggh0:~$ ip -br a | grep UP
loop0 UP 194.1.163.10/32 2001:678:d78::a/128 fe80::dcad:ff:fe00:0/64
xe0-0 UP 193.34.197.143/25 2001:7f8:6d::8298:1/64 fe80::3eec:efff:fe70:24a/64
xe0-1 UP fe80::3eec:efff:fe70:24b/64
xe1-0 UP fe80::6a05:caff:fe32:45ac/64
xe1-1 UP fe80::6a05:caff:fe32:45ad/64
xe1-2 UP fe80::6a05:caff:fe32:45ae/64
xe1-2.100@xe1-2 UP fe80::6a05:caff:fe32:45ae/64
xe1-2.200@xe1-2 UP fe80::6a05:caff:fe32:45ae/64
xe1-2.391@xe1-2 UP 46.20.247.3/29 2a02:2528:ff03::3/64 fe80::6a05:caff:fe32:45ae/64
xe0-1.100@xe0-1 UP 194.1.163.137/29 2001:678:d78:6::1/64 fe80::3eec:efff:fe70:24b/64
pim@frggh0:~$ birdc show bfd ses
BIRD v2.15.1-4-g280daed5-x ready.
bfd1:
IP address Interface State Since Interval Timeout
fe80::3eec:efff:fe46:68a9 xe1-2.200 Up 2024-06-19 20:16:58 0.100 3.000
fe80::6a05:caff:fe32:3e38 xe1-2.100 Up 2024-06-19 20:13:11 0.100 3.000
pim@frggh0:~$ birdc show ospf nei
BIRD v2.15.1-4-g280daed5-x ready.
ospf4:
Router ID Pri State DTime Interface Router IP
194.1.163.9 1 Full/PtP 34.947 xe1-2.100 fe80::6a05:caff:fe32:3e38
194.1.163.8 1 Full/PtP 31.940 xe1-2.200 fe80::3eec:efff:fe46:68a9
ospf6:
Router ID Pri State DTime Interface Router IP
194.1.163.9 1 Full/PtP 34.947 xe1-2.100 fe80::6a05:caff:fe32:3e38
194.1.163.8 1 Full/PtP 31.940 xe1-2.200 fe80::3eec:efff:fe46:68a9
You can see here that the router indeed has an IPv4 loopback address 194.1.163.10/32, and
2001:678:d78::a/128. It has two backbone links, on xe1-2.100 towards Paris and xe1-2.200
towards Amsterdam. Judging by the time between the BFD sessions, it took me somewhere around four
minutes to drain, reconfigure, and undrain each link. I kept on listening to Nora en Pure’s
[Episode #408] the whole time.
A traceroute
The beauty of this solution is that the routers will still have one IPv4 and IPv6 address, from
their loop0 interface. The VPP dataplane will use this when generating ICMP error messages, for
example in a traceroute. It will look quite normal:
pim@squanchy:~/src/ipng.ch$ traceroute bit.nl
traceroute to bit.nl (213.136.12.97), 30 hops max, 60 byte packets
1 chbtl0.ipng.ch (194.1.163.65) 0.366 ms 0.408 ms 0.393 ms
2 chrma0.ipng.ch (194.1.163.0) 1.219 ms 1.252 ms 1.180 ms
3 defra0.ipng.ch (194.1.163.7) 6.943 ms 6.887 ms 6.922 ms
4 nlams0.ipng.ch (194.1.163.8) 12.882 ms 12.835 ms 12.910 ms
5 as12859.frys-ix.net (185.1.203.186) 14.028 ms 14.160 ms 14.436 ms
6 http-bit-ev-new.lb.network.bit.nl (213.136.12.97) 14.098 ms 14.671 ms 14.965 ms
pim@squanchy:~$ traceroute6 bit.nl
traceroute6 to bit.nl (2001:7b8:3:5::80:19), 64 hops max, 60 byte packets
1 chbtl0.ipng.ch (2001:678:d78:3::1) 0.871 ms 0.373 ms 0.304 ms
2 chrma0.ipng.ch (2001:678:d78::) 1.418 ms 1.387 ms 1.764 ms
3 defra0.ipng.ch (2001:678:d78::7) 6.974 ms 6.877 ms 6.912 ms
4 nlams0.ipng.ch (2001:678:d78::8) 13.023 ms 13.014 ms 13.013 ms
5 as12859.frys-ix.net (2001:7f8:10f::323b:186) 14.322 ms 14.181 ms 14.827 ms
6 http-bit-ev-new.lb.network.bit.nl (2001:7b8:3:5::80:19) 14.176 ms 14.24 ms 14.093 ms
The only difference from before is that now, these traceroute hops are from the loopback addresses,
not the P2P transit links (eg the second hop, through chrma0 is now 194.1.163.0 and 2001:678:d78::
respectively, where before that would have been 194.1.163.17 and 2001:678:d78::2:3:2 respectively.
Subtle, but super dope.
Link Flap Test
The proof is in the pudding, they say. After all of this link draining, reconfiguring and undraining, I gain confidence that this stuff actually works as advertised! I thought it’d be a nice touch to demonstrate a link drain, between Frankfurt and Amsterdam. I recorded a little screencast [asciinema, gif], shown here:
{kind=link}
Returning IPv4 (and IPv6!) addresses
Now that the backbone links no longer carry global unicast addresses, and they borrow from the one
IPv4 and IPv6 address in loop0, I can return a whole stack of addresses:
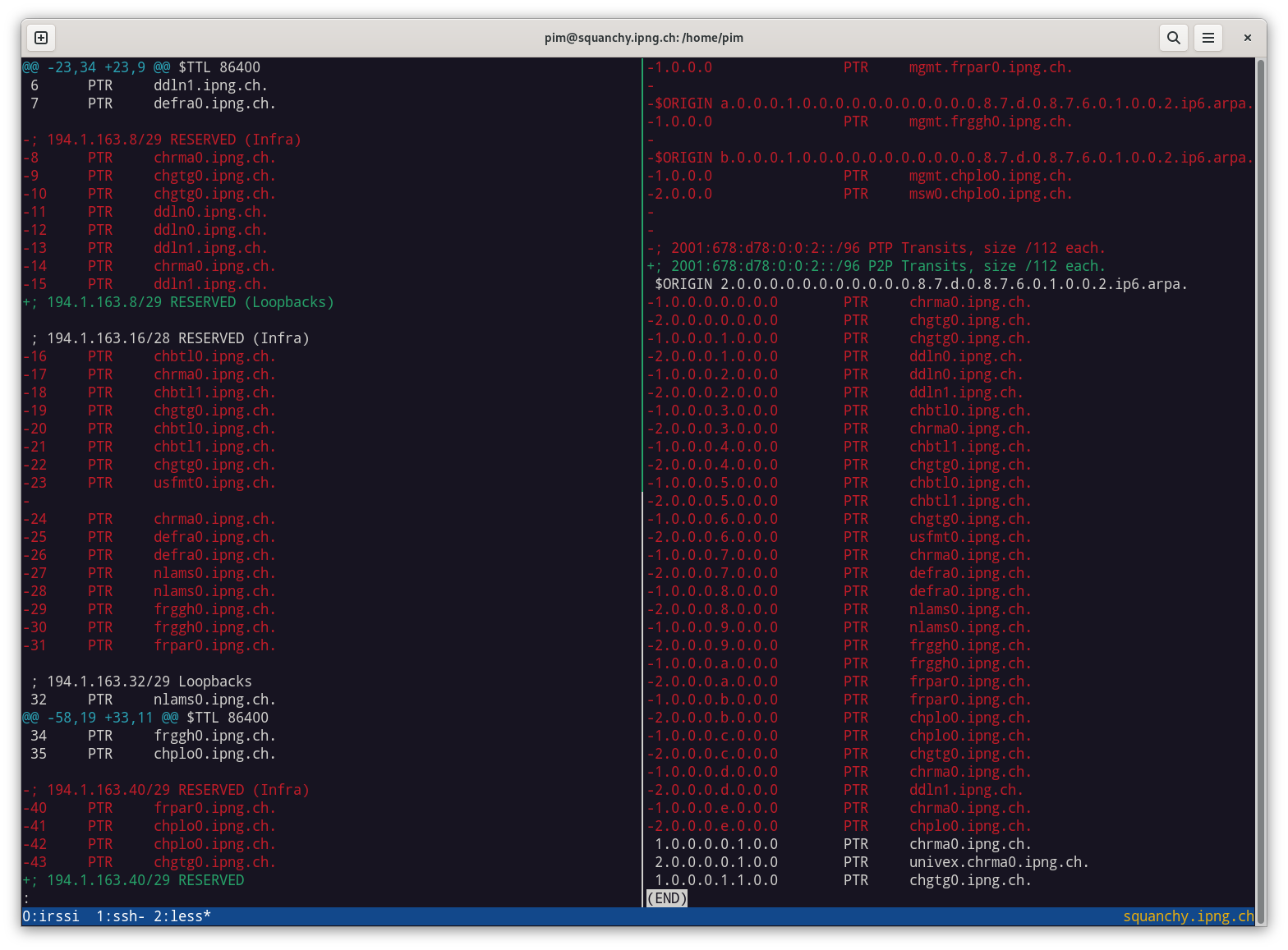
In total, I returned 34 IPv4 addresses from IPng’s /24, which is 13.3%. This is huge, and I’m confident that I will find a better use for these little addresses than being pointless point-to-point links!